二型糖尿病合并癌症与常规化验指标相关性分析模型的制作方法
1.本发明涉及医学化验指标数据分析技术领域,具体涉及一种二型糖尿病合并癌症与常规化验指标相关性分析模型。
背景技术:
2.研究资料表明,糖尿病患者中肿瘤发病率可高达28.35%,远远高于普通人群各年龄段最高的1.16%发病率。目前,糖尿病导致恶性肿瘤发病率增加的确切发病机制尚不清楚,降糖药物与癌症风险间关系的研究也十分有限。因此探究二型糖尿病是否是癌症发生的一个独立风险因素,定量评估糖尿病,降糖药物使用与癌症以及肺癌,肝癌,结直肠癌等21种常见癌症发生风险之间的关系,能为糖尿病与癌症的疾病防治与慢性病管理提供临床与政策建议。
技术实现要素:
3.本发明提供一种二型糖尿病合并癌症与常规化验指标相关性分析模型,基于监督学习的多种机器学习方法的综合应用,可以有效地挖掘隐藏在大样本真实数据中的知识和规则,并利用这些变量进行建模,可根据常规检查指标预测2型糖尿病病人中罹患癌症的危险人群。
4.为了达到上述目的,本发明提供如下技术方案:一种二型糖尿病合并癌症与常规化验指标相关性分析模型,其创建方法包括以下步骤:
5.步骤一、对确诊糖尿病的病例进行筛选,获得确诊二型糖尿病合并癌症,排除心脏病、肾病、高血压、动脉硬化、高血脂的观察病例,和确诊二型糖尿病,排除癌症、心脏病、肾病、高血压、动脉硬化、高血脂的对照病例;分别对观察病例以及对照病例进行筛分获得相对应的关联化验数据;对两组关联化验数据在年龄、性别上进行聚类匹配法进行匹配,得到观察组和对照组;
6.步骤二、数据清洗,提取的化验项数据变量,将缺失值率超过30%的变量予以删除,获得有效变量;对有效变量中的定量变量进行正态性检验,凡是通过正态检验的利用均值对缺失值予以填充,未通过正态性检验的利用中位数予以填充;对变量中的分类变量,利用其构成比对缺失值进行填充;
7.步骤三、主要特征探索,首先使用最小描述长度算法,探索提取数据中变量中的每一个的特征重要性,找出观察组与对照组之间最重要的特征;
8.步骤四、建立机器学习模型;
9.步骤五、模型评估。
10.优选的,所述聚类匹配法为,根据年龄性别采用k均值算法将观察组进行聚类,分成不同的亚组{am}并得到分组规则,根据分组规则将对照组同样进行分组,得到{bm},以同类两组例数比最低值min(ai∶bi)为基础比例,在对照组的每个亚组,即对应观察组的每个亚组中根据基础比例随机选取病例,b’j=aj/min(ai∶bi),保证两组在每个亚组的比例相
同,同时保证将所有的观察组数据均纳入分析。
11.优选的,所述步骤三中,利用mdl算法将每一个相关变量看做是一个简单的预测模型,使用其相应的mdl度量对这些单一预测模型进行比较和评分,并找出相关变量;
12.公式为:si(modeli,d)=s(modeli)+s(ci),
13.其中si(modeli,d)为应用第i个属性建立简单预测模型后得到的总大小,s(modeli)为应用第i个属性建立简单预测模型的大小,s(ci)是第i个属性建立简单预测模型后所有预测错误的原始数据大小的总和。
14.优选的,所述步骤三中,根据特征选择算法所发现的特征是优选特征。
15.优选的,所述步骤三中,选择的特征涵盖常规检查不同的方面,如血常规、肝肾功能、电解质。
16.优选的,所述步骤三中,特征独立于变量,并降低多元相关性和多元共线性。
17.本发明有益效果为:通过数据挖掘和探索发现了2型糖尿病合并癌症与2型糖尿病研究相关的几个指标,利用机器学习算法可以建立效率较高的分类模型,并验证了这些相关指标的可靠性指标也得到了核实。分类模型在有监督学习的基础上,应用了mdl变量选择模型、决策树和bayes分类模型等多种机器学习方法,对多年的大样本临床数据进行分类。对2型糖尿病合并癌症的相关特征进行了探讨、挖掘和分析。结果表明,基于红细胞体积分布宽度、红细胞比积测定、中性粒细胞比率、血红蛋白测定、胆碱脂酶、钾的分类模型对2型糖尿病合并癌症的预测分类更为有效。这种基于监督学习的多种机器学习方法的综合应用,可以有效地挖掘隐藏在大样本真实数据中的知识和规则。因此,利用这些变量进行建模,可以根据常规检查指标预测2型糖尿病病人中罹患癌症的危险人群,有助于早期发现、早期防治。
附图说明
18.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
19.图1为本发明中前30个特征系数分布图;
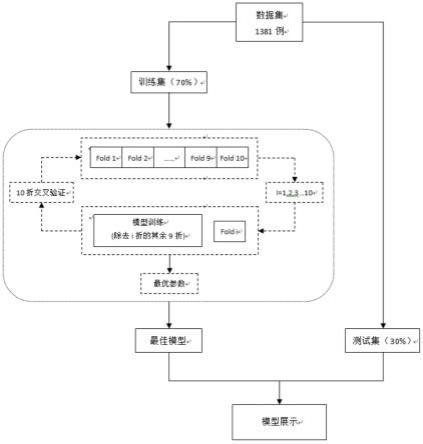
20.图2为本发明机器模型的学习流程图;
21.图3示出了本发明roc曲线汇总;
22.图4示出了本发明6个模型的校正曲线。
具体实施方式
23.下面将结合本发明的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
24.一种二型糖尿病合并癌症与常规化验指标相关性分析模型,其创建方法包括以下步骤:
25.步骤一、对确诊糖尿病的病例进行筛选,获得确诊二型糖尿病合并癌症,排除心脏病、肾病、高血压、动脉硬化、高血脂的观察病例,和确诊二型糖尿病,排除癌症、心脏病、肾病、高血压、动脉硬化、高血脂的对照病例;分别对观察病例以及对照病例进行筛分获得相对应的关联化验数据;对两组关联化验数据在年龄、性别上进行聚类匹配法进行匹配,得到观察组和对照组;
26.通过执行真实病例数据,将陕西省人民医院自2018年10月至2019年9月全部住院病例中主要诊断或其他诊断中确诊为糖尿病的病例共23,916例,观察组纳入确诊2型糖尿病合并癌症,排除心脏病、肾病、高血压、动脉硬化、高血脂的病例,共1630例,其中714例关联到化验数据,对照组纳入确诊2型糖尿病,排除癌症、心脏病、肾病、高血压、动脉硬化、高血脂的病例共4290例,其中1724例关联到化验数据;对两组数据在年龄、性别上进行聚类匹配法进行匹配,得到观察组714例,对照组667例。
27.其中的聚类匹配法为,根据年龄性别采用k均值算法将观察组进行聚类,分成不同的亚组{am}并得到分组规则,根据分组规则将对照组同样进行分组,得到{bm},以同类两组例数比最低值min(ai:bi)为基础比例,在对照组的每个亚组,即对应观察组的每个亚组中根据基础比例随机选取病例,b’j=aj/min(ai:bi),保证两组在每个亚组的比例相同,同时保证将所有的观察组数据均纳入分析。
28.步骤二、数据清洗,提取的化验项数据变量共有458个,将缺失值率超过30%的变量予以删除,得到74个有效变量;对变量中的定量变量进行正态性检验,凡是通过正态检验的利用均值对缺失值予以填充,未通过正态性检验的利用中位数予以填充;对变量中的分类变量,利用其构成比对缺失值进行填充。
29.步骤三、主要特征探索,我们首先使用最小描述长度算法,可以有效地发现重要的特征,探索提取数据中变量中的每一个的特征重要性,找出观察组与对照组之间最重要的特征,其中的全部变量特征系数表如下:
30.[0031][0032]
而特征系数如图1所示,其中示出了30个特征系数。
[0033]
该步骤中采用了mdl算法,其将每一个相关变量看做是一个简单的预测模型,使用其相应的mdl度量对这些单一预测模型进行比较和评分,从而找出相关变量。其公式为:si(modeli,d)=s(modeli)+s(ci),其中si(modeli,d)为应用第i个属性建立简单预测模型后得到的总大小,s(modeli)为应用第i个属性建立简单预测模型的大小,s(ci)是第i个属性建立简单预测模型后所有预测错误的原始数据大小总和。
[0034]
我们根据以下条件选择建模特征:1、特征选择算法所发现的特征是优选特征。2.选择的特征应尽可能涵盖常规检查不同的方面,如血常规、肝肾功能、电解质等3.选择的特征应尽可能独立于变量,即,应尽可能降低多元相关性和多元共线性。4.特征数与数据量应保持适当的比例。5.应考虑医学专业的原则和实践经验。
[0035]
步骤四、在建立机器学习模型的过程中,我们计划参与6个特征的建模,其中自变量个数与数据量之比为1:230。因此,模型的数学可靠性得到了很好的保证,6个变量具有很好的解释性,涵盖了许多有意义的医学领域。
[0036]
因此,基于上述原则,我们选择了特征选择算法发现的6个特征,包括红细胞体积分布宽度、红细胞比积测定、中性粒细胞比率、血红蛋白测定、胆碱脂酶、钾等。这些特征包括血常规、肝肾功能等特征。此外,所选特征具有较好的变量独立性,特征间强相关的可能性相对较低。通过统计分析,年龄和性别通过对变量的控制在组间没有统计学差异,即两组在这两个变量上比较均衡,而所选则的六个建模变量则存在明显的统计学差异。
[0037]
其中建模变量表如下所示:
[0038]
meaningimportance红细胞体积0.0575红细胞比积测定0.0268中性粒细胞比率0.0261血红蛋白测定0.0247胆碱脂酶0.0194钾0.0178
[0039]
主要参数统计
[0040][0041][0042]
机器模型的学习流程图如图2所示,图3示出了roc曲线汇总,而其分类建模评价主要参数如下表所示:
[0043][0044][0045]
步骤五、模型评估,图4示出了6个模型的校正曲线,各个模型的预测曲线与完美校正的对角线越接近,说明模型的拟合优度越好,预测模型最可靠。其中,随机森林模型和logistic回归模型最好。
[0046]
由此可知,auc值均大于75%,说明通过数据挖掘和探索发现了2型糖尿病合并癌症与2型糖尿病研究相关的几个指标,利用机器学习算法可以建立效率较高的分类模型,并验证了这些相关指标的可靠性指标也得到了核实。分类模型在有监督学习的基础上,应用了mdl变量选择模型、决策树和bayes分类模型等多种机器学习方法,对多年的大样本临床数据进行分类。对2型糖尿病合并癌症的相关特征进行了探讨、挖掘和分析。结果表明,基于红细胞体积分布宽度、红细胞比积测定、中性粒细胞比率、血红蛋白测定、胆碱脂酶、钾的分类模型对2型糖尿病合并癌症的预测分类更为有效。这种基于监督学习的多种机器学习方
法的综合应用,可以有效地挖掘隐藏在大样本真实数据中的知识和规则。因此,利用这些变量进行建模,可以根据常规检查指标预测2型糖尿病病人中罹患癌症的危险人群,有助于早期发现、早期防治。
[0047]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1