一种高可靠性的情绪特征提取与筛选方法与流程
1.本发明属于数据挖掘与分析领域,涉及一种高可靠性的情绪特征提取与筛选方法。
背景技术:
2.近年来,随着社会生活压力逐步增大,人员负面情绪乃至心理疾病的发生率普遍呈上升趋势,社会对人员负面情绪评估的需求在逐步增多。特征提取与选择的效果对负面情绪评估模型的准确度有较大的影响。
3.然而,现有的研究更侧重于设计出优越的模型结构,在特征提取方面几乎没有改进,负面情绪评估模型缺乏与之配套的可靠的特征提取与选择方法。此外,数据集通常包含较多的特征,这些特征与时间、空间邻近的数据大多是不相关的,或者它们的相关性也没有事先分析好。数据集中不相关特征的存在会造成机器学习算法缺乏准确性、占用过多计算资源导致速度变慢的问题。
技术实现要素:
4.有鉴于此,本发明的目的在于克服上述现有技术的缺点,提供了一种高可靠性的情绪特征提取与筛选方法,以解决现有负面情绪评估模型缺乏可靠特征提取方法以及特征数据冗余的技术问题。
5.为达到上述目的,本发明采用以下的技术方案:本发明的一种基于生成对抗网络的情绪特征提取方法,包括如下步骤:步骤一:将语音和图像特征向量转换为二维图像特征图;步骤二:构建双向生成对抗网络,采用二级分层学习策略训练之,不仅训练生成器也训练编码器;步骤三:利用所述双向生成对抗网络提取数据集的特征。
6.进一步地,在步骤二,采用二级分层学习策略来降低训练阶段的复杂性并促进模型的收敛。在第一层,我们将原始输入特征图分割成几个子图像,对于每个子图像,分配双向生成对抗网络模型来学习特征图中的合成特征:征图中的合成特征:。
7.进一步地,在双向生成对抗网络训练过程中,我们不仅训练生成器,还训练编码器,双向生成对抗网络的训练目标定义为极小极大目标:其中,
,e代表数学期望,enc代表编码器。
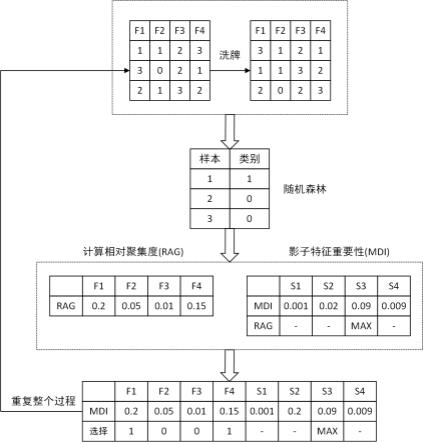
8.本发明的一种基于随机森林的情绪特征筛选方法,包括如下步骤:步骤一:对利用上述情绪特征提取方法提取而得的数据进行预处理,复制一份特征数据并对该副本进行洗牌操作,生成影子特征;步骤二:选择在综合数据集上使用随机森林分类器和测量相对聚集度的方法来量化每个特征的重要性;步骤三:对于每次迭代,找出影子特征属性之间的最大相对聚集度,并验证实际特征的相对聚集度是否高于其大多数阴影特征的最大相对聚集度;步骤四:如果某特征的相对聚集度低于其影子特征的最大相对聚集度,则认为该特征不相关,并将其完全移除;步骤五:当验证或拒绝所有特征时,或当达到随机森林的极限时,特征选择算法将终止。
9.进一步地,在步骤二中,在随机森林算法的每次迭代中,对完全集成的新特征集、原始特征和影子特征的重要性分数进行评估,以过滤可用于建模的最佳特征集。
10.进一步地,在步骤二中,袋外误差相对聚集度rag的定义如下:rag=μ(e
ob
)/ σ(e
ob
),其中e
ob
=(y
i-y
iob
)2/n其中e
ob
是随机森林的袋外误差;yi为样本值;y
iob
是样本yi的袋外样本的预测值,μ(e
ob
)是袋外误差的平均值,σ(e
ob
)是袋外误差的标准差。
11.进一步地,在步骤二中,随机森林中的特征分组方法为:计算每个特征和类别的互信息,按照互信息从小到大的顺序进行排序,并对特征集进行分组。定义特征分组的标准q可以表示为:其中,。
12.本发明具有以下有益效果:本发明所述的一种高可靠性的情绪特征提取与筛选方法在具体应用时,提出了一种基于双向生成对抗网络的特征提取方法、二级分层学习策略来降低训练阶段的复杂性并
促进模型的收敛,提高情绪特征提取能力。提出了一种基于随机森林的特征选择方法,从一组随机样本中收集结果,大大减轻了随机波动和变量之间关系的误导影响,意味着能更准确地所有特征划分为精华特征(予以保留)和非精华特征。本发明可以有效地从数据集中提取特征,并选择高价值的特征避免计算开销大与过拟合的问题,与其他方法相比具有更好的性能和更广泛的应用范围。
附图说明
13.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面对实施例或现有技术描述中所需要使用的附图做简单的介绍;显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
14.图1是本发明实施例二提供的高可靠性的情绪特征筛选方法流程图。
具体实施方式
15.以下所描述的实施例仅仅是本发明一部分的实施例,不是全部的实施例,而并非要限制本发明公开的范围。此外,在以下说明中,省略了部分对公知技术的描述,以避免不必要的混淆本发明公开的概念。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
16.在附图中示出了根据本发明公开实施例的结构示意图。这些图并非是按比例绘制的,其中为了清楚表达的目的,放大了某些细节,并且可能省略了某些细节。图中所示出的各种区域、层的形状及它们之间的相对大小、位置关系仅是示例性的,实际中可能有所偏差,并且本领域技术人员根据实际所需可以另外设计具有不同形状、大小、相对位置的区域/层。
17.为了使本领域的技术人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
18.实施例一本发明所述的一种基于生成对抗网络的情绪特征提取方法,包括如下步骤。
19.步骤一:将语音和图像特征向量转换为二维图像特征图。
20.步骤二:构建双向生成对抗网络,采用二级分层学习策略训练之,不仅训练生成器也训练编码器。
21.在本实施例中,采用二级分层学习策略来降低训练阶段的复杂性并促进模型的收敛。在第一层,我们将原始输入特征图分割成几个子图像,每个子图像的大小为25
×
25。对于每个子图像,分配双向生成对抗网络模型来学习特征图中的合成特征:分配双向生成对抗网络模型来学习特征图中的合成特征:。
22.在双向生成对抗网络训练过程中,我们不仅训练生成器,还训练编码器,双向生成对抗网络的训练目标定义为极小极大目标:
其中,其中,,e代表数学期望,enc代表编码器。
23.步骤三:利用所述双向生成对抗网络提取数据集的特征。
24.实施例二请参阅图1,本发明所述的一种基于随机森林的情绪特征筛选方法,包括如下步骤。
25.步骤一:利用本发明实施例一提供的一种高可靠性的情绪特征提取方法提取特征数据,并对所述数据进行预处理,复制一份特征数据并对该副本进行洗牌操作,生成影子特征。
26.步骤二:选择在综合数据集上使用随机森林分类器和测量相对聚集度的方法来量化每个特征的重要性。
27.具体地,在随机森林算法的每次迭代中,对完全集成的新特征集、原始特征和影子特征的重要性分数进行评估,以过滤可用于建模的最佳特征集。袋外误差相对聚集度rag的定义如下:rag=μ(e
ob
)/ σ(e
ob
),其中e
ob
=(y
i-y
iob
)2/n其中e
ob
是随机森林的袋外误差;yi为样本值;y
iob
是样本yi的袋外样本的预测值,μ(e
ob
)是袋外误差的平均值,σ(e
ob
)是袋外误差的标准差。
28.具体地,随机森林中的特征分组方法为:计算每个特征和类别的互信息,按照互信息从小到大的顺序进行排序,并对特征集进行分组。定义特征分组的标准q可以表示为其中, 。
29.步骤三:对于每次迭代,找出影子特征属性之间的最大相对聚集度,并验证实际特征的相对聚集度是否高于其大多数阴影特征的最大相对聚集度。
30.步骤四:如果某特征的相对聚集度低于其影子特征的最大相对聚集度,则认为该特征不相关,并将其完全移除。
31.步骤五:当验证或拒绝所有特征时,或当达到随机森林的极限时,特征选择算法将终止。
32.综上所述,本发明所述的一种高可靠性的情绪特征提取与筛选方法在具体应用时,提出了一种基于双向生成对抗网络的特征提取方法、二级分层学习策略来降低训练阶段的复杂性并促进模型的收敛,提高情绪特征提取能力。提出了一种基于随机森林的特征选择方法,从一组随机样本中收集结果,大大减轻了随机波动和变量之间关系的误导影响,意味着能更准确地所有特征划分为精华特征(予以保留)和非精华特征。本发明可以有效地从数据集中提取特征,并选择高价值的特征避免计算开销大与过拟合的问题,与其他方法相比具有更好的性能和更广泛的应用范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1