1.本发明涉及互联网医疗领域,具体为一种互联网医疗分诊方法及系统。
背景技术:2.近年来,互联网医疗由于使用上方便快捷,同时又能享受到优质的医疗资源等诸多优点,已经越来越受到人们的欢迎。在互联网医疗的流程中,分诊是患者就诊的第一个环节,因此分诊得准确性和及时性对就诊效率有着重要影响。
3.现有技术中,部分互联网分诊系统采用规则匹配和知识库结合的方法来实现分诊功能,需要用户通过多轮交互选择或者回答相关问题才能得到结果,但规则和知识库又难以全面覆盖用户实际情况,用户体验显得繁琐、耗时且效果不佳。还有部分互联网分诊系统采用单个神经网络模型来实现,操作虽然方便了,但是又存在准确率不高或实现难度大等问题。为此,我们提出一种互联网医疗分诊方法及系统。
技术实现要素:4.本发明要解决的技术问题是克服现有的缺陷,提供一种互联网医疗分诊方法及系统,综合使用了bert向量搜索和fasttext分类模型两种推荐结果,并考虑了用户性别和年龄的影响因素,提高了分诊的准确率,可以有效解决背景技术中的问题。
5.为实现上述目的,本发明提供如下技术方案:一种互联网医疗分诊方法,包括以下步骤:
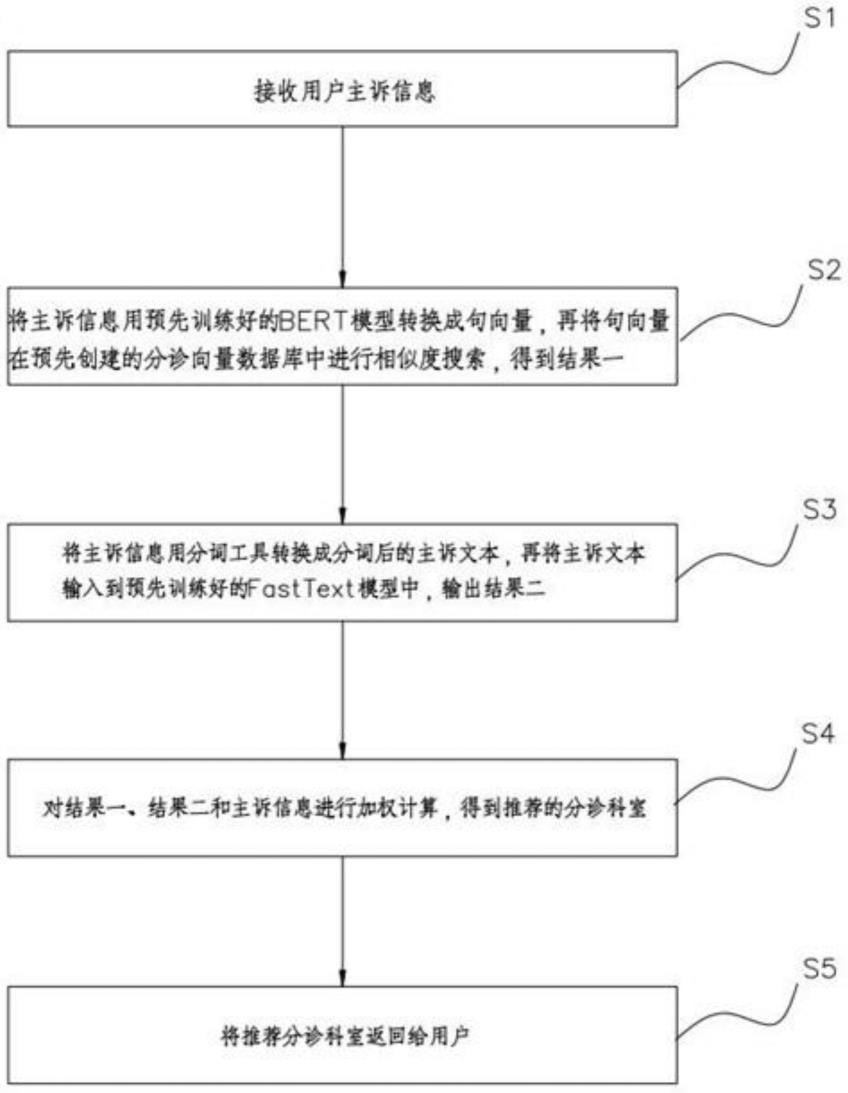
6.s1接收用户主诉信息;
7.s2将主诉信息用预先训练好的bert模型转换成句向量,再将句向量在预先创建的分诊向量数据库中进行相似度搜索,得到结果一;
8.s3将主诉信息用分词工具转换成分词后的主诉文本,再将主诉文本输入到预先训练好的fasttext模型中,输出结果二;
9.s4对结果一、结果二和主诉信息进行加权计算,得到推荐的分诊科室;
10.s5将推荐分诊科室返回给用户。
11.进一步的,s1中,接收的用户主诉信息为主诉文本,可选项包括性别和年龄信息。
12.进一步的,s2中,bert模型为开源的公共模型或针对医学领域知识专门训练的模型。
13.进一步的,s2中,分诊向量数据库的创建方法,包括以下步骤:
14.(1)在公开的医疗问答网站和医疗百科中获取数据并清洗成科室和描述对应的样本数据集合;
15.(2)将样本数据集合中的每条初始数据的描述用bert模型转化成句向量形成新的科室和句向量对应的向量集合;
16.(3)将向量集合存入支持按搜索相似度排序的向量数据库中。
17.进一步的,s2中,用于将主诉信息转化成句向量的bert模型和将样本数据描述转
化成句向量的bert模型为同一模型。
18.进一步的,s2中,结果一是根据搜索相似度由高到低排序的科室和相似度对应的集合,可指定返回的集合条目数为n。
19.进一步的,s3中,fasttext模型训练方法,包括以下步骤:
20.(1)将公开的医疗问答网站和医疗百科中获取的数据集合作为fasttext模型训练的样本数据集合;
21.(2)对集合中每条样本数据的描述用分词工具进行分词并和该条数据的科室对应转换成fasttext模型的输入格式形成训练数据。并将训练数据按照一定比例分配为训练集、验证集和测试集;
22.(3)设置fasttext模型的训练参数并进行训练。
23.进一步的,s3中,结果二是根据预测概率由高到低排序的科室分类和概率对应的集合,可指定科室分类个数为k。
24.进一步的,s4中,对结果一、结果二和主诉信息进行加权计算的方法,包括以下步骤:
25.(1)先对结果一的集合按照相同科室只保留一条记录的规则进行合并,同科室合并后的相似度为被合并条目的相似度进行加权计算后的相似度,合并后再按相似度由高到低排序并限制集合长度不大于k得到结果三;
26.(2)对结果三和结果二的集合也按照相同科室只保留一条记录的规则进行合并,同科室合并后的权重为结果三中被合并项的相似度和结果二被合并项的概率进行加权计算后的值,合并后再按权重值由高到低排序,排序后的科室和对应权重集合作为结果四。
27.进一步的,如果主诉信息有年龄和性别信息,通过查询年龄和性别对应科室权重表对结果四的权重值进行加权调整,年龄和性别对应科室权重表,是由科室和对应年龄和性别的相关概率组成的二维表,具体概率值可查公开数据或专家评估指导得出。
28.进一步的,对结果四的科室进行科室标准化,方法包括以下步骤:
29.(1)统计样本数据集合中出现过的科室列表;
30.(2)对科室列表中的每个科室映射一个对应的标准科室,形成样本数据中出现的科室对应标准科室的二维表;
31.(3)根据标准科室二维表对结果四的科室进行标准科室替换;
32.(4)替换后如有相同科室的再进行合并,计算对应的加权权重值。
33.进一步的,检查推荐结果是否有效,若判断为无效结果时将结果四的集合置空,判断方法包括但不限于:
34.(1)判断结果四中最大权重值是否大于rq,大于则有效否则无效;
35.(2)判断结果四集合长度是否小于预设值rn,小于则有效否则无效;
36.(3)判断结果四的权重平均值是否大于预设值rr,大于则有效否则无效;
37.(4)判断结果四的权重离散系数是否大于预设值rv,大于则有效否则无效。
38.进一步的,s5中,将推荐分诊科室返回给用户,方法包括以下步骤:
39.(1)若结果四集合不为空,则返回集合中的第一个科室作为推荐科室,同时告知分诊状态为成功;
40.(2)若结果四集合为空,则返回推荐科室为空,同时告知分诊状态为失败。
41.进一步的,返回推荐分诊科室后,接收用户最终的就诊科室信息,方法包括以下步骤:
42.(1)记录用户最终实际就诊科室。最终就诊科室和推荐科室可能不一致包括但不限于用户自己修改就诊科室和医生进行了转诊操作;
43.(2)将最终就诊科室和主诉及后续补充信息对应作为正样本数据,并按照前述方法分别添加到分诊向量数据库和fasttext模型训练集并更新模型。
44.一种互联网医疗分诊系统,包括:
45.信息接收模块,用于接收用户主诉信息;
46.bert处理模块,用于使用预先训练好的bert模型转换成句向量,将句向量在预先准备好的分诊向量数据库中进行相似度搜索得到结果一;
47.fasttext处理模块,用于将主诉信息用分词工具转换成分词后的主诉文本,将主诉文本输入到预先训练好的fasttext模型中,模型输出结果二;
48.结果处理模块,用于对结果一、结果二和主诉信息进行加权计算得到推荐分诊科室;
49.结果返回模块,用于将推荐分诊科室返回给用户。
50.与现有技术相比,本互联网医疗分诊方法及系统,具有以下好处:
51.本技术提供的互联网医疗分诊方法及系统,用户只需提交主诉信息一步操作便可获得推荐就诊科室,使用上更加方便快捷,降低了用户使用门槛,扩大了受众群体。
52.同时综合使用了bert向量搜索和fasttext分类模型两种推荐结果,并考虑了用户性别和年龄的影响因素,提高了分诊的准确率。并随着用户的使用会不断的产生正样本可持续改进推荐效果。另外本方案可操作性强易于实施,有利于降低使用成本。
附图说明
53.图1为本发明中一种互联网医疗分诊方法的流程图;
54.图2为本发明中一种互联网医疗分诊系统的架构图。
具体实施方式
55.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
56.请参阅图1,本技术中提供了一种互联网医疗分诊方法,包括步骤:
57.s1接收用户主诉信息;
58.s2将主诉用预先训练好的bert模型转换成句向量,将句向量在预先准备好的分诊向量数据库中进行相似度搜索得到结果一;
59.s3将主诉用分词工具转换成分词后的主诉文本,将主诉文本输入到预先训练好的fasttext模型中,模型输出结果二;
60.s4对结果一、结果二和主诉信息进行加权计算得到推荐分诊科室;
61.s5将推荐分诊科室返回给用户。
62.实施例一
63.本方案提出了一种互联网医疗分诊方法,可以应用在互联网医疗的移动智能终端设备,如手机、电脑、医疗机器人等,以下统称为用户端。用户端通过互联网与服务器相连,由服务器端来提供分诊的数据处理和结果计算。
64.如上述步骤s1所述,分诊系统需要获取用户的主诉信息,主诉信息应包含主诉文本,可选项包含性别和年龄信息。为了提高分诊的有效性可以限制主诉文本必须至少包含指定个数的字词,比如本实施用例中可以要求最少包含两个中文字词或一个英文单词。同时可以要求提供性别和年龄信息,性别和年龄信息可以帮助提高分诊的准确性。
65.本实施例获取到的主诉信息如下:
66.主诉文本:从昨天开始眼睛就很不舒服,感觉有些干涩、还有些畏光;
67.性别:男;
68.年龄:18。
69.如上述步骤s2所述,预先训练好的bert(bidirectional encoder representations)模型可以是已经开源的公共模型,也可以是自己用医学领域的资料有针对性地训练出来的模型。本实施例中采用谷歌已经开源的bert中文模型“chinese_l-12_h-768_a-12”,将上述s1中获取的主诉文本输入模型可以得到768维的主诉句向量。
70.预先准备好的分诊向量数据库是支持搜索相似度排序的向量数据库,本实施例中使用elasticsearch 7.x及之后的版本作为向量数据库,并将在公开的医疗问答网站和医疗百科中获取的样本数据转换成句向量和对应科室数据保存到向量数据库作为分诊向量数据库;再将上述主诉句向量在分诊向量数据库中进行搜索,返回的结果按相似度由高到低排列,相似度越高代表主诉句向量和分诊向量数据库中对应的样本向量越接近,相同科室的概率就越高。本实施例中向量搜索指定的相似度函数为余弦相似度函数(cosinesimilarity),指定返回结果的条目数n为10,返回结果为结果一,结果一如下:[('普通内科',1.9273292),('眼科',1.9202818),('眼科',1.9190224),('皮肤科',1.9168247),('心血管内科',1.9162781),('口腔黏膜科',1.9141773),('眼科',1.9140877),('眼科',1.9134121),('眼科',1.9120796),('神经内科',1.9110016)]。
[0071]
如上述步骤s3所述,将主诉用分词工具转换成分词后的主诉文本,本实施例中采用结巴(jieba)作为分词工具,上述主诉文本分词后为“从昨天开始眼睛就很不舒服感觉有些干涩还有些畏光”。
[0072]
预先训练好的fasttext模型在本实施例中是将上述步骤来自公开的医疗问答网站和医疗百科中获取的样本数据用结巴(jieba)进行分词,然后和对应的科室转换成fasttext模型的训练数据,格式如:“__label__皮肤科皮肤皮肤痒是湿疹吗”,并将训练数据按照一定比例分配为训练集、验证集和测试集同时设置fasttext模型的参数并进行训练。如本实施例中比例设置为8:1:1参数设置为lr=0.1、dim=300、epoch=100、word_ngrams=2、loss='softmax'。
[0073]
再将上诉分词后的主诉文本输入训练好的fasttext模型得到结果二,结果二是根据预测概率由高到低排序的科室分类和概率对应的集合,可指定科室分类个数为k。本实施例中指定k为3,结果二如下:[('眼科',0.9679074287414551),('内分泌科',0.011039340868592262),('整形外科',0.003901942167431116)]。
[0074]
如上述步骤s4所述,对结果一、结果二和主诉信息进行加权计算,先对结果一的集合按照相同科室只保留一条记录的规则进行合并,合并后再按相似度由高到低排序并限制集合长度不大于k得到结果三。本实施例中合并加权计算的具体方法为:待合并的第一条记录的相似度和第二条记录的相似度求平均值并加上权重值0.1作为第一条记录的相似度并删除第二条记录,用该方法再次合并待合并项直到不需要合并,并按相似度排序取前k(此时k为3)项得到结果三,本实施例中结果一经过合并后得到结果三为:[('眼科',2.1011103),('普通内科',1.9273292),('皮肤科',1.9168247)]。
[0075]
再对结果三和结果二的集合也按照相同科室只保留一条记录的规则进行合并,同科室合并后的权重为结果三中被合并项的相似度和结果二被合并项的概率进行加权计算后的值,合并后再按权重值由高到低排序,排序后的科室和对应权重集合作为结果四。本实施例中结果三和结果二合并的具体方法为:将结果二中的概率乘以2.1作为权重值,并将每项添加到结果三中,如果存在相同的科室则只相加权重值得到结果四,本实施例中结果三和结果二合并后得到结果四为:[('眼科',4.133715841356391),('普通内科',1.92732919105266),('皮肤科',1.9168246100014579),('内分泌科',0.02318261582404375),('整形外科',0.008194078551605343)]。
[0076]
可选的,如果上诉主诉信息有年龄和性别信息,对应年龄和性别科室权重表对结果四的权重值进行加权。本实施例中获取的主诉信息包含性别和年龄,性别为男、年龄为18需要降低妇科和老年病科等科室的权重,如结果四中如有妇科和老年病科则对应的权重减去1,当前示例中并没有所以无需修改。
[0077]
可选的,对结果四的科室进行科室标准化,可以通过预先建立的标准科室映射表来进行标准化,标准化后如有相同科室的再进行合并,并计算对应的加权权重值。例如本实施例中结果四中有科室“普通内科”查表可以标准化为“普内科”,因为没有相同科室所以无需合并。结果四修改为:[('眼科',4.133715841356391),('普内科',1.92732919105266),('皮肤科',1.9168246100014579),('内分泌科',0.02318261582404375),('整形外科',0.008194078551605343)]。另外为了使推荐科室的唯一性和结果的一致性建议选择该可选步骤。
[0078]
可选的,检查推荐结果是否有效,在本实施例中设置限制结果四中最大权重值rq需大于2,因为眼科的权重值大于2,所以判断结果四有效。
[0079]
如上述步骤s5所述,将推荐分诊科室返回给用户,并接收用户最终的就诊科室信息。将最终就诊科室和主诉及后续补充信息对应作为正样本数据,并按照前述方法分别添加到分诊向量数据库和fasttext模型训练集并更新模型。本实施例中结果四不为空,返回集合中的第一个科室“眼科”作为推荐科室,并告知分诊状态为成功。客户端反馈该用户最终就诊科室也为眼科,将“眼科”和主诉文本“从昨天开始眼睛就很不舒服,感觉有些干涩、还有些畏光”对应作为正样本加入分诊向量数据库和fasttext模型训练集并更新fasttext模型。
[0080]
请参阅图2,本技术中还提供一种互联网医疗的分诊系统,包括:
[0081]
信息接收模块,用于接收待分诊用户主诉信息;
[0082]
bert处理模块,用于使用预先训练好的bert模型转换成句向量,将句向量在预先准备好的分诊向量数据库中进行相似度搜索得到结果一;
[0083]
fasttext处理模块,用于将主诉信息用分词工具转换成分词后的主诉文本,将主诉文本输入到预先训练好的fasttext模型中,模型输出结果二;
[0084]
结果处理模块,用于对结果一、结果二和主诉信息进行加权计算得到推荐分诊科室;
[0085]
结果返回模块,用于将推荐分诊科室返回给用户。
[0086]
如上所述,本互联网医疗分诊系统中的各个模块可以实现上述互联网医疗分诊方法中的任一项功能,具体结构不再赘述。
[0087]
以上仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。