一种基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的预测模型及应用
1.本发明涉及一种人体健康风险的预测模型,具体涉及一种基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的预测模型及其应用,属于环境保护技术领域。
背景技术:
2.影响农用地土壤质量的主要污染物是重金属,其中镉为首要污染物。暴露在受污染的土壤上种植的粮食作物和蔬菜等农产品可能构成公共健康危害。镉作为一种非必须金属元素,对生物体具有高毒性。它能影响农产品的产量和品质,危害人居环境安全,威胁生态环境安全。
3.中国既是蔬菜生产大国,又是蔬菜消费大国。蔬菜种类繁多,它们能提供人们所需的碳水化合物、蛋白质、维生素、矿物质和纤维等人类健康的关键营养素。蔬菜中镉污染在我国不同地区被广泛报道,而蔬菜是膳食重金属暴露中主要的暴露方式,所以评价蔬菜中的重金属对人体的健康风险十分重要。
4.富集系数是植物组织中污染物的浓度与土壤中浓度的比值,它能反映不同蔬菜的富集能力大小,不同蔬菜富集能力不同,它也是重金属在土壤中的迁移和积累以及土壤生物有效性的重要参数,最重要的一点,它是土壤-蔬菜系统中重金属经食物链传递到人的关键环节,是起始环节。富集系数差异受多种因素影响,如污染物性质及其浓度,土壤理化性质(如ph、有机质、阳离子交换量等),还受到气候和蔬菜种类等的影响。因此富集系数一定程度上表明各种差异,是一个综合指标,一方面用于指导蔬菜种植及食用,提供蔬菜种植与食用策略,另一方面对于探索重金属在土壤-蔬菜系统经食物链传递至人体的健康风险具有重要意义,有助于建立并修正人体健康风险评价的方法与模型。
5.当前我国人体健康风险评价方法基于四步法,既危害识别,危害评估,暴露评估,风险表征,使用的成熟模型有美国材料与试验协会开发的rbca模型,荷兰住房部开发的csoil模型,美国环保署开发的rags模型等。这些模型主要通过三种方式评价人体健康风险,即皮肤接触,呼吸吸入,经口摄入,其中经口膳食暴露风险可达到90%以上,为主要的暴露途径。虽然当前有这么多成熟模型,但由于原有的评价模型的参数较多,数据获取较为困难,缺乏用富集系数预测经口膳食的人体健康风险的简化模型。因此,亟需建立一个以富集系数作为修正的符合我国国情的膳食评价方法与健康风险评价模型。
技术实现要素:
6.针对现有技术问题,本发明的第一个目的在于提供一种基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的预测模型,该模型通过随机森林算法建立,经过有限次训练后,模型可根据富集系数准确预测蔬菜中的重金属对于人体健康影响,该模型具有结构简单,预测准确,数据获取简单和适用范围广泛等优点。
7.本发明的第二个目的在于提供一种上述模型的应用,通过上述模型判断不同季节
和地域的蔬菜中重金属富集系数对人体健康的危害等级,并根据风险等级指导蔬菜的种植和食用,有效保障了生产者和消费者的财产和健康安全。
8.为实现上述技术目的,本发明提供了一种基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的预测模型,包括以下步骤:
9.步骤1):获取蔬菜的与重金属富集相关特征数据;
10.步骤2):对所述与重金属相关特征数据进行清洗和预处理;
11.步骤3):获取蔬菜经口膳食参数,并计算蔬菜经口膳食的人体健康风险值;
12.步骤4):建立蔬菜特征数据与蔬菜经口膳食的人体健康风险值的机器学习模型;
13.步骤5):对所得机器学习模型进行性能评价。
14.本发明采用五步法建模,通过机器学习方法建立蔬菜与蔬菜经口膳食的人体健康风险之间的映射关系,通过有限次的训练,该模型可以根据蔬菜的特征数据精准的预测其对人体健康存在的风险,auc大于0.97,总体分类精度达91%以上。
15.作为一项优选的方案,所述重金属富集相关特征数据包括:蔬菜中重金属的富集系数、蔬菜种植土壤重金属浓度、种植区域和蔬菜种类。
16.作为一项优选的方案,所述蔬菜中重金属的富集系数为蔬菜中可食用部位的重金属浓度与蔬菜种植土壤中重金属浓度的比值。
17.本发明采用蔬菜中重金属的富集系数反映不同蔬菜的富集能力大小,是土壤
ꢀ‑
蔬菜系统中重金属经食物链传递到人体的关键环节与起始环节的关键参数之一,对于评价经口膳食暴露的人体健康风险起着关键的作用;蔬菜重金属富集系数差异受到多种因素的影响(如污染物性质及其浓度、土壤理化性质与气候等),是一个综合指标,可以代替其它因素准确预测蔬菜中的重金属对于人体健康的影响,达到利用富集系数等特征数据提供预测精度的目的。
18.作为一项优选的方案,所述种植区域按地理位置划分为:北方地区、东部地区、中部地区、南部地区和西南地区。
19.作为一项优选的方案,所述重金属包括:铬、镉、汞、砷、镍、铜和锌中至少一种。
20.本发明从蔬菜中重金属的种类和地域两个维度来描述蔬菜中重金属的富集系数,由于蔬菜本身是一种强季节性作物,因此,可额外增加季节维度来辅助描述蔬菜中重金属的富集系数。
21.作为一项优选的方案,所述数据清洗和预处理过程,包括:i)对特征数据进行关联性验证,并分类;ii)对特征数据进行格式清洗;iii)对特征数据中的异常值进行删除清理;iv)对特征数据中的缺失值进行插值处理。
22.作为一项优选的方案,所述蔬菜经口膳食参数包括:蔬菜中可食部位污染物浓度cf,每日经口摄入的蔬菜量ir、暴露频率ef、暴露期ed、体重bw、平均暴露时间at、消化道吸收效率因子abso和经口摄入参考剂量rfdo。
23.作为一项优选的方案,所述计算蔬菜经口膳食的人体健康风险的方程为:
24.式1:
25.其中:hq为蔬菜经口膳食的人体健康风险值,无量纲;cf为蔬菜中可食部位污染物浓度,量纲为mg/kg;ir为每日经口摄入的蔬菜量,量纲为mg/d;ef 为暴露频率,量纲为
days/year;ed为暴露期,量纲为year;bw为体重,量纲为kg;at为平均暴露时间,量纲为days;abso为消化道吸收效率因子,无量纲;rfdo为经口摄入参考剂量,量纲为mg/kg-day。
26.作为一项优选的方案,所述蔬菜经口膳食的人体健康风险按人群居住特性分为蔬菜经口膳食的城市人群人体健康风险和蔬菜经口膳食的农村人群人体健康风险。
27.作为一项优选的方案,所述蔬菜特征数据与蔬菜经口膳食的人体健康风险值的机器学习模型采用随机森林分类模型,建立过程包括:
28.i)蔬菜经口膳食的人体健康风险值划分为以下四个风险等级:0<hq≤0.5 为无风险、0.5<hq≤1为低风险、1<hq≤2为中风险和2<hq为高风险;
29.ii)将特征数据分为测试集数据和训练集数据,测试集数据占特征数据总量的50~80%;
30.iii)确定随机森林分类模型的主要参数,并将测试集数据与风险等级进行模型拟合,所述随机森林分类模型的主要参数包括:确定随机决策树的数量ntree 和每颗决策树随机取样的预测变量的数量mtry;
31.iv)对测试集数据进行重要性分析,采用meandecreasegini表示,其中gini 指数计算表达式为:
32.式2:
33.其中:n表示测试集数据的n个类别;p(i)为当前节点中第i个类别所占的比例;
34.v)采用测试集数据进行模型测试。
35.本发明将训练集数据作为随机森林分类模型的输入参量,对于随机森林分类模型中的每一颗决策树,通过自助法(bootstrap)抽样得到未参与该决策树选择的样本数据,应注意的是,当样本数据的基础量足够大时,每颗树总会有36.8%的数据没有抽取到,这一部分数据被称为袋外数据。因此,可根据所有决策树的平均袋外误差的最小值来确定随机森林分类模型中每颗决策树随机取样的预测变量的数量和决策树的数量,进一步的,还可以用于参数的寻优过程。
36.作为一项优选的方案,所述性能评价主要过程为:采用混淆矩阵对模型进行精度检验和模型性能评价;所述模型性能评价包括曲线下面积、召回率和总体分类精度,其中,召回率和总体分类精度的计算公式为:
37.式3:
38.式4:
39.式5:
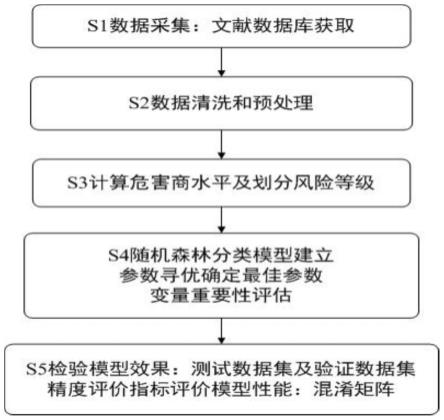
40.式3~5中:tp为模型分类正确的正样本个数,无量纲;fn为模型分类错误的正样本个数,无量纲;fp为模型分类错误的负样本个数,无量纲;tn为模型分类正确的负样本个数,无量纲;tpr为真正例率,无量纲;r为召回率,无量纲;fpr为假正例率,无量纲;oa为总体分类精度,无量纲。
41.混淆矩阵是表示预测精度的一种检测方式,在本发明中,以蔬菜中重金属的富集
系数作为输入量来预测蔬菜经口膳食的人体健康风险,因此,本发明所采用的混淆矩阵为对蔬菜经口膳食的人体健康风险预测结果的误差矩阵。根据混淆矩阵进一步的采用曲线下面积(auc)、召回率(r)和总体分类精度(oa)描述模型性能,其中,召回率虽然与模型的准确率没有必然的关系,但在实际测试中,召回率与准确率大多呈现负相关关系,因此,在本发明中也可以采用召回率来反应模型的准确率;进一步的,为了更好的检测模型整体的性能,本发明又计算了模型的auc,auc指roc曲线下面积,但本发明没有绘制roc曲线图,由于本发明中蔬菜的特征数据均为离散值,因此可直接采用编程计数法得到,auc 可用于度量分类模型的泛化能力,当曲线下面积越接近1时,模型的泛化能力越好,性能也就越好。通过上述各项检测过程,可以做到准确的、较为全面的对模型的整体性能进行分析,并可以根据模型性能的分析结果进行针对性的参数优化。
42.本发明还提供了基于上述模型的应用,指导蔬菜的种植和食用选择。根据模型计算出的结果,若蔬菜对应的hq表示为高风险则不建议种植和食用,若hq 表示为低风险或无风险,则建议种植和食用,若hq值表示为中风险,则建议少量种植和少量食用。
43.相对现有技术,本发明带来的有益技术效果为:
44.1)本发明提供的蔬菜中重金属富集系数与经口膳食暴露的人体健康风险的模型采用随机森林算法,经过有限次训练后,该模型可根据富集系数准确预测蔬菜中的重金属对于人体健康影响。此外,该模型随着使用次数的增加,可以进行自主调节,使得测试结果越来越准确。
45.2)本发明所提供的技术方案中,数据来源广泛,模型结构简单,通过时间和空间多维度的分类,进一步提高了模型的适用性,根据本发明所提供模型的预测结果,可快速、准确的找出蔬菜在种植和食用过程中的潜在风险,对于蔬菜的生产和消费具有重要的指导意义。
附图说明
46.图1为本发明构建的基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的模型方法流程示意图。
47.图2为本发明构建基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的模型自变量的重要性图:(a)城市人群(b)农村人群。
48.图3为本发明的训练集与测试集检验随机森林分类模型的auc值图。
49.图4为本发明的验证集检验随机森林分类模型的auc值图。
50.图5为本发明基于蔬菜镉富集系数与模型预测结果所提出的蔬菜种植区域推荐图。
具体实施方式
51.以下具体实施例旨在进一步说明本发明内容,而不是限制权利要求的保护范围。
52.本发明所提供的实施例均以食用蔬菜中重金属镉产生的人体健康风险模型为例,其余重金属如铬、砷、铜等均可按照实施例所提供的方法进行模型建立。
53.实施例1
54.一种基于蔬菜的重金属富集系数与经口膳食暴露的人体健康风险的模型方法,如
图1,包括以下步骤:
55.步骤s1:获取文献中蔬菜镉富集系数、土壤中镉浓度、种植区域、蔬菜名称等相关数据;
56.具体的,所收集的文献数据来自web of science、中国知网、万方数据库等数据库公开发表的文献;所述的镉富集系数为蔬菜中可食用部位的重金属镉浓度与土壤中重金属镉浓度的比值,种植区域划分为北方、华东、华中、华南、西南,蔬菜种类分为叶类蔬菜、根茎类蔬菜与果实类蔬菜。
57.具体的,叶类蔬菜包括大白菜、菠菜、茼蒿、小白菜、韭菜、油麦菜、空心菜、甘蓝、大葱、芥菜、生菜、苋菜、红菜薹等,根茎类蔬菜包括莴笋、芋头、萝卜、莲藕、芹菜、番薯、大蒜、生姜等,果实类蔬菜包括辣椒、西红柿、豆类、丝瓜、茄子、冬瓜、黄瓜、南瓜、苦瓜等。
58.步骤s2:将所采集的特征数据进行清洗,对异常值进行清理,将缺失值进行插值处理。
59.步骤s3:分不同省份计算蔬菜经口膳食的人体健康风险,受体人群分为城市人群、农村人群,使用的评价模型为美国环保署发布的非致癌危害商模型:
[0060][0061]
其中cf为蔬菜中可食部位污染物浓度(mg/kg),ir为每日经口摄入的蔬菜量(mg/d)、ef为暴露频率(days/year)、ed为暴露期(year)、bw为体重(kg)、 at为平均暴露时间(days)、abso为消化道吸收效率因子、rfdo为经口摄入参考剂量(mg/kg-d),相关参数来自国家统计局、《中国人群暴露参数手册(成人卷)》与《建设用地土壤污染风险评估技术导则》(hj 25.3—2019)。
[0062]
具体的,根据所计算得到的城市人群、农村人群的危害商水平,划分四个风险等级:无风险(0<hq≤0.5)、低风险(0.5<hq≤1)、中风险(1<hq≤2)、高风险(2<hq)。
[0063]
步骤s4:根据上述所划分风险等级后的数据,以镉富集系数、土壤重金属镉浓度、种植区域及蔬菜种类作为自变量,以划分的经口膳食产生的危害商水平分类等级作为因变量,建立随机森林分类模型;
[0064]
具体的,为了确定随机森林分类模型的主要参数,即确定随机森林分类模型中每棵决策树随机取样的预测变量的数量和决策树的数量,包括:(i)在每棵决策树划分节点,即随机取样的预测变量的数量:参数mtry。对于分类模型,默认值为预测变量总数的二次方根。(ii)决策树(分类树)的数量:参数ntree。为了优化最终模型构建的节点与决策树的数量,通过参数寻优过程,最终ntree 设置为500,mtry设置为4;(iii)模型类型,分类:参数类型选择分类进行分类预测;
[0065]
利用随机森林分类模型进行变量重要性评估:对于某预测变量,计算其重要性是变换后的预测误差与原来相比差的均值,可用meandecreasegini表示,其表示为gini指数(节点不纯度)的平均减少值,该值越大表示该变量的重要性越大,gini指数计算表达式为:
[0066][0067]
其中,n表示有n个类别;p(i)=第i类数目/总数目(指当前节点数据值),表明当前节点中类别i所占的比例。
[0068]
具体的,将训练数据集作为随机森林分类模型的输入,对于随机森林分类模型中的每一棵决策树,采用该决策树对应的袋外数据计算其袋外数据误差;所述训练数据集为划分风险等级后的数据的70%,余下30%为测试数据集,所述袋外数据是指构建单棵决策树时,通过boostrap抽样得到的未参与该决策树建立过程的数据;所述的参数寻优过程是根据所有决策树的平均袋外误差最小值确定随机森林分类模型中每棵决策树随机取样的预测变量的数量和决策树的数量;随机森林分类模型的建立过程可以采用r语言软件实现。
[0069]
步骤s5检验模型性能:利用所划分的测试数据集及验证集检验模型的性能;精度评价指标评价模型性能;其中,精度评价指标通过利用测试集及验证集生成的混淆矩阵对基于随机森林的人群风险预测模型进行精度检验获得。
[0070]
具体的,所述验证集为通过实地协同采集土壤与蔬菜样品,经测定重金属浓度后,计算及分类后的数据;所述对人群风险预测的精度进行评价的混淆矩阵 (confusion matrix)也称误差矩阵,是表示精度评价的一种标准格式,用n行n 列的矩阵形式来表示。由测试集及验证集检验生成混淆矩阵,具体评价指标有曲线下面积(area under the curve,auc)、召回率(recall,r)、总体分类精度 (overall accuracy,oa)等,这些精度指标从不同的侧面反映了分类的精度。
[0071]
具体的,这里的曲线下面积(area under the curve,auc)指受试者工作特征(receiver operating characteristic,roc)曲线下面积,用于度量分类模型的泛化能力,auc值越接近于1,模型的泛化能力越好,即性能越好;以真正例率(true positive rate,tpr)为纵轴,假正例率(false positive rate,fpr) 为横轴绘制roc曲线,然后通过计算roc曲线下面积即auc值;召回率 (recall,r)表示某分类类别中分类正确的样本个数占该分类类别中总样本个数的比例;总体分类精度(overall accuracy,oa)表示分类正确的样本个数占所有样本个数的比例;
[0072]
真正例率(tpr)、假正例率(fpr)、召回率(r)、总体分类精度(oa) 的计算表达式为:
[0073][0074][0075][0076]
其中,tp为模型分类正确的正样本个数,fn为模型分类错误的正样本个数, fp为模型分类错误的负样本个数,tn为模型分类正确的负样本个数,正样本表示某分类类别,负样本表示除去正样本某分类类别后的其它类别。
[0077]
利用所划分的测试集数据检验分类模型的效果:自变量对构建此模型的重要性如图2,图中表明所选定的自变量富集系数对预测结果起主要作用,说明选用富集系数评价人体健康风险是合理的;训练集与测试集auc值(area under thecurve)如图3,图中训练集城市人群、农村人群的风险预测的模型auc值均为 1,表明在训练集取得最佳性能;图中测试集城市人群、农村人群的风险预测的模型auc值分别为0.9857、0.9765,均接近1,表明模型泛化能力较好,模型性能较好;表1与表2为随机森林分类模型输出的测试集中城市与农
村人群混淆矩阵的结果。
[0078]
表1蔬菜经口膳食暴露的城市人群风险预测结果
[0079][0080][0081]
表2蔬菜经口膳食暴露的农村人群风险预测结果
[0082][0083]
预测结果表明城市人群的无风险、低风险、中风险、高风险的召回率分别为 96.50%、82.71%、76.40%、95.04%,农村人群的无风险、低风险、中风险、高风险的召回率分别为97.84%、79.84%、73.33%、95.04%,城市人群、农村人群的总体分类精度分别为91.75%、91.77%,准确率较高,表明此模型的泛化能力较好。
[0084]
实施例2
[0085]
为了进一步说明实施例1中的模型性能,本实施例采用实测数据进行验证:
[0086]
1、实测数据采集:采集101个蔬菜样本以及种植蔬菜的土壤样本分别进行镉浓度分析,分析方法参照国家gb5009.15-2014标准以及hj803-2016标准进行。
[0087]
2、富集系数计算及危害商等级划分
[0088]
将每种蔬菜的镉浓度与种植该蔬菜的土壤镉浓度进行比值计算,计算其富集系数,再通过蔬菜镉浓度计算危害商水平,划分风险等级。计算结果见表3:
[0089]
表3蔬菜中镉富集系数及城市、农村人群危害商风险等级
[0090]
[0091]
[0092]
[0093]
[0094][0095]
3、检验模型的效果
[0096]
验证集检验模型auc值如图4,图中城市人群、农村人群的风险预测的模型auc值分别为0.9789、0.9740,均接近1,表明经验证集检验模型的性能,也能取得较好的结果,说明此分类模型可用于实际情景;表4与表5为随机森林分类模型输出的验证集中城市与农村人群混淆矩阵的结果。
[0097]
表4蔬菜经口膳食暴露的城市人群风险预测结果
[0098][0099]
表5蔬菜经口膳食暴露的农村人群风险预测结果
[0100][0101]
预测结果表明城市人群的无风险、低风险、中风险、高风险的召回率分别为 100%、78.95%、72.22%、100%,农村人群的无风险、低风险、中风险、高风险的召回率分别为100%、84.21%、82.35%、93.75%,城市人群、农村人群的总体分类精度分别为91.09%、93.07%,准确率较高,表明此模型在实际值的应用上也能取得较好性能,所以基于富集系数预测蔬菜经口膳食的人体健康风险的简化模型被证明是有效的。
[0102]
实施例3
[0103]
一种基于富集系数与经口膳食暴露的人体健康风险的模型的蔬菜种植与食用策略:利用已有数据进行蔬菜镉富集系数差异分析,包括季节镉富集差异与区域镉富集差异,比较同种类蔬菜在不同季节与区域的镉富集能力大小;同时利用实施例1所建立的模型计算出的人体健康风险水平,比较同种类蔬菜在不同季节与区域食用所产生的人体健康风险高低,根据蔬菜镉富集系数差异与食用蔬菜的人体健康风险高低,确定同种类蔬菜在何种季节及何种区域种植与食用将会有更低的健康风险水平,低风险水平的蔬菜将会被推荐种植与食用,从而提出一种基于富集系数的蔬菜种植与食用策略,包括春夏季、秋冬季种植与食用策略(表6),南方人群、北方人群种植与食用策略(表6)以及蔬菜种植区域推荐图(图5)。
[0104]
表6季节与区域蔬菜种植与食用策略
[0105][0106]
如表6所示,推荐在春夏季种植与食用韭菜、大葱、大蒜、茄子,因为相比于秋冬季,在春夏季食用这些蔬菜有较低的人体健康风险;同样的,推荐在秋冬季种植与食用生菜、菠菜、小白菜、油麦菜、芹菜、西红柿。对于南北方区域种植与食用建议,推荐在南方地区种植与食用菠菜、生菜、空心菜、香菜,因为相比于北方地区,在南方地区食用这些蔬菜有较低的人体健康风险;同样的,推荐在北方地区种植与食用菜薹、苋菜、小白菜、油麦菜、芹菜、西红柿、辣椒。根据以上所述,通过调整种植模式、合理的进行各区域的蔬菜调配,可以减弱重金属镉经食物链传递至人体的危害。
[0107]
蔬菜种植区域推荐图如图5,根据蔬菜在不同地区的种植与食用风险比较,确定六
个被推荐的蔬菜种植区域,如图中所示,分别是叶类、根茎类、果实类推荐种植区域,叶类、根茎类推荐种植区域,果实类推荐种植区域,叶类、果实类推荐种植区域,根茎类推荐种植区域,根茎类、果实类推荐种植区域。根据所推荐的六个种植区域,通过合理种植,可以减少经食用蔬菜所产生的人体健康风险。
[0108]
以上是对本发明的较佳实施进行了具体说明,并不用以限制本发明,凡在不违背本发明精神的前提下作出种种的等同变形、替换和改进等,均包含在本技术权利要求所限定的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1