一种基于结构脑连接组方法的阿尔兹海默症预测平台
1.本发明涉及一种阿尔兹海默症风险预测技术,特别涉及一种基于结构脑连接组方法的阿尔兹海默症预测平台。
背景技术:
2.近年来,全球的老年化趋势日益严重,而在老年人群众,阿尔兹海默症肆虐,并且目前并没有有效的根治方式,只能对其进行早期的预防措施,但是很多人觉得随着年龄的增长,便会患上阿尔兹海默症,从而对其并不上心。
3.在fmri预处理方面,fmri的配准并不完全准确。可能由于扫描过程中受到一些因素影响导致图像不同步或出现错误匹配点等现象。
技术实现要素:
4.针对背景技术中提到的问题,本发明的目的是提供一种基于结构脑连接组方法的阿尔兹海默症预测平台。
5.本发明的上述技术目的是通过以下技术方案得以实现的:
6.综上所述,本发明主要具有以下有益效果:
7.(1)整体界面清晰明了,对于各种功能操作简便,适合各种年龄段的人群使用,从而老年人群可以很方便的使用概率预测功能。
8.(2)本次设计选用的数据集中的样本较为典型,通过114个被试者进行测试,可以通过图论分析构建出功能脑网络。
9.(3)本次设计所构建的脑网络模型,通过社区发现算法中的gn算法,挖掘出差异脑区的社区。
10.(4)本设计完全属于公益性的项目,社会各层次的人员皆可进行使用,将繁杂的数据通过图标的样式展现出来,并且提供了ad预测的功能,从而有利于提高全社会对于老年痴呆病的防范意识。
附图说明
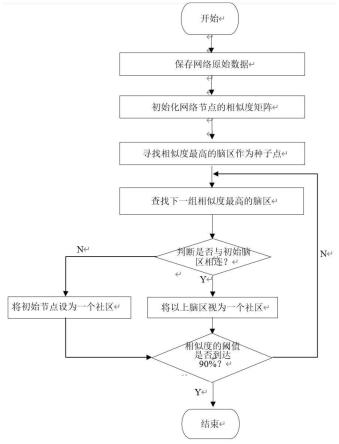
11.图1为运用社区寻找算法挖掘脑网络社区的流程图;
12.图2为相似度最高的三个社区形成的网络图一;
13.图3为社区1的脑区连接过程示意图;
14.图4为社区2的脑区连接过程示意图;
15.图5为相似度最高的社区形成的网络;
16.图6为相似度最高的三个社区形成的网络图二;
17.图7为与ad密切相关的脑区所在大脑的位置示意图;
18.图8为各组q值的大小的示意图;
19.图9为adni数据库中的脑影像(a);
20.图10为adni数据库中的脑影像(b);
21.图11为aal模板示意图;
22.图12为ad、cn、emci、lmci组关于最短路径的小提琴图对照;
23.图13为ad、cn、emci、lmci组关于小世界属性的小提琴图对照;
24.图14为ad组与cn组差异的脑网络可视化示意图;
25.图15为ad组与emci组差异的脑网络可视化示意图;
26.图16为ad组与lmci组差异的脑网络可视化示意图;
27.图17为ad组与lmci组差异的脑网络可视化示意图。
具体实施方式
28.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
29.因此,本发明对这些问题进行了研究。下一步是尝试更精确的脑部分割算法来进行影像配准。此外,本发明使用aal模板来对脑区划分,大脑每个大脑在个体空间里是不同的。本发明可以尝试手动标记脑区来获得更精确的脑网络和统计分析结果。
30.在数据集方面。本发明所用的数据量有限,可以通过采集更多的病人数据来增加数据量。在统计分析中,大数据量能更准确地代表这一群体的状态,使分析结果更加可靠,以在临床诊断中达到更高的准确率。当数据量增大以后,还可以尝试张量、深度学习等降维和分类方法。
31.将静息状态功能磁共振图像的数据预处理后,用图论网络分析的方式来建立脑功能网络系统,并观察ad分组与cn组(正常人),ad分别与emc i组,以及ad分别与lmci分组的脑功能网络系统状况,并由此来分析各对照组的功能脑网络系统的变化特性,并使用图论方式估计功能脑网络系统的拓扑属性。利用对拓扑属性如小世界属性,度中心属性等的不同确定了发生在异常脑区中的度和边的研究,并通过对度和边的区别,利用社区发现算法中的gn算法(一种凝聚型的社区发现算法)挖掘出了相似率最高的差异脑区,由cn组,emci组,lmci组至ad组之间的大脑损伤范围,这些脑区主要分布于默认的模式网络中,并伴随着ad患者的记忆水平下降,感知能力减退,或者是在日常生活中无法自理等的临床表现。通过对这些脑部损伤区域功能的分析,确定其是否与阿尔兹海默症有关,以此来达到对阿尔兹海默症预测的目的。
32.算法介绍:
33.先存储网络原始数据,并初始化网络节点的相似度矩阵,然后查找相似性最高的脑区(最少有两个脑区,只有两个以上的脑区可以比较相似度)作为种子点,并查找下一组相似度最高的脑区,此过程中查看该脑区是否直接或间接的与初始脑区相连,若与初始脑区相连,则将这些脑区形成的脑网络视为一个社区,若不与初始脑区相连,则依旧将初始脑区现已形成的网络视为一个社区,接下来,相似度的阈值是否到达90%,若未达到90%的阈值,则要继续去查找下一组相似度最高的脑区,一直到90个脑区都遍历一遍,完成社区寻找算法挖掘脑网络社区的过程,该过程如上图1所示。
34.ad-cn组相似度前十的差异脑区形成的社区,如表4-1所示:
35.表4-1 ad-cn组挖掘到的连通脑区形成的社区
[0036][0037][0038]
从表4-1里面可以看到第二组与第六组的挖掘到的连通脑区与其他组脑区都不相同,之所以不同,是因为初始脑区不同,则与初始脑区连接的脑区可能不相同。而第一组的脑区与第三组、第四组、第五组、第六组、第七组及第八组包含有相同的脑区。也可以看到因为初始脑区不相同,而导致最终产生的社区中有部分脑区是相同的,之所以相同,是因为该脑区按照相似度,可能与不同的脑区都有连接。
[0039]
第一个社区形成的网络,第二个社区形成的网络,第三个社区形成的网络可如图2中所示:
[0040]
因此该对照组获得的相似度最大的挖掘到的连通脑区为第45个脑区(楔叶左脑区,cun.l),第46个脑区(楔叶右脑区,cun.r),第55个脑区(梭状回左脑区,ffg.l),该组是以55号脑区为种子点。
[0041]
ad-emci组相似度前十挖掘到的连通脑区形成的社区,如表4-2所示:
[0042]
表4-2 ad-emci组挖掘到的连通脑区形成的社区
[0043][0044][0045]
从表4-2里面可以看到前三组挖掘到的连通脑区是完全相同的,而其他几组也都拥有相同的脑区。可以看到有三个相同的社区,但其实他们的初始脑区是不同的,如图3是编号为1社区的脑区连接过程,如图4是编号为2社区的脑区连接过程,这里本文可以看到社区1的初始脑区为58脑区(中央后回右脑区,pocg.r),其先与27号脑区(回直肌左脑区,rec.l)连接,然后再返回58号脑区(中央后回右脑区,pocg.r)与28号脑区连接,28号脑区(回直肌右脑区,rec.r)与57号脑区(中央后回左脑区,pocg.l)连接后又与27号脑区(回直肌左脑区,rec.l)连接。社区2的初始脑区为57脑区(中央后回左脑区,pocg.l),它先与28号脑区(回直肌右脑区,rec.r)连接,随后28号脑区又与58号脑区(中央后回右脑区,pocg.r)连接,接着58号脑区(中央后回右脑区,pocg.r)与27号脑区(回直肌左脑区,rec.l)连接,27号脑区业余57号脑区(中央后回左脑区,pocg.l)连接。
[0046]
前三组挖掘到的连通脑区形成的社区如图5所示。
[0047]
因此该对照组获得的相似度最大的挖掘到的连通脑区为第27个脑区(回直肌左脑区,rec.l),第28个脑区(回直肌右脑区,rec.r),第57个脑区(中央后回左脑区,pocg.l),第58个脑区(中央后回右脑区,pocg.r)。
[0048]
ad组与lmci组相似度前十挖掘到的连通脑区形成的社区,如表4-3所示:
[0049]
表4-3 ad-lmci组挖掘到的连通脑区形成的社区
[0050][0051][0052]
从表4-3里面可以看到,每一组社区都与其他社区有相同的脑区,但第七组与第四组的脑区互不相同,这是因为初始脑区不相同,在寻找连接的过程中,部分脑区之间相似度较高而导致最终产生的社区中有部分脑区是相同的。
[0053]
第一个社区形成的网络,第二个社区形成的网络,第三个社区形成的网络可如图6中所示,因此该对照组获得的相似度最大的挖掘到的连通脑区为第20个脑区(补充运动区右脑区,sma.r),第21个脑区(嗅皮质左脑区,olf.l),第23个脑区(内侧额上回左脑区,sfgmed.l),第31个脑区(前扣带和旁扣带脑回右脑区,acg.l),第40个脑区(杏仁核右脑区,phg.r),第48个脑区(枕上回右脑区,ling.r),该组的种子点为31脑区。
[0054]
脑网络社区分析
[0055]
由表4-1得到的十组社区中,重复的脑区有:17号脑区(中央沟盖左脑区),29号脑区(脑岛左脑区),43号脑区(距状裂周围皮层左脑区),44号脑区(距状裂周围皮层右脑区),45号脑区(楔叶左脑区),46号脑区(楔叶右脑区),47号脑区(舌回左脑区),48号脑区(舌回右脑区),49号脑区(枕上回左脑区),51号脑区(枕中回左脑区),55号脑区(梭状回左脑区),56号脑区(梭状回右脑区),57号脑区(中央后回左脑区),80号脑区(颞横回右脑区)。这些脑区如表4-4对分析与ad有关的脑区有很大的帮助。
[0056]
表4-4在ad-cn组十个社区中挖掘到的重复脑区
[0057][0058]
由表4-2得到的十组社区中,重复的脑区有:1号脑区(中央前回左脑区),10号脑区(眶部额中回右脑区),15号脑右脑区区(眶部额下回左脑区),25号脑区(眶内额上回左脑区),26号脑区(眶内额上回右脑区),27号脑区(回直肌左脑区),28号脑区(回直肌右脑区),33号脑区(内侧和旁扣带脑回左脑区),57号脑区(中央后回左脑区),58号脑区(中央后回右脑区),86号脑区(颞中回右脑区)。这些脑区如表4-5对分析与ad有关的脑区有很大的帮助。
[0059]
表4-5在ad-emci组十个社区中挖掘到的重复脑区
[0060][0061]
由表4-3得到的十组社区中,重复的脑区有:1号脑区(中央前回左脑区),6号脑区(眶部额上回右脑区),9号脑区(眶部额中回左脑区),10号脑区(眶部额中回右脑区),14号脑区(三角部额下回右脑区),16号脑区(眶部额下回右脑区),20号脑区(补充运动区右脑区),21号脑区(嗅皮质左脑区),23号脑区(嗅皮质右脑区),30号脑区(脑岛右脑区),31号脑区(前扣带和旁扣带脑回左脑区),36号脑区(后扣带回),40号脑区(海马旁回右脑区),45号脑区(楔叶左脑区),48号脑区(舌回右脑区),57号脑区(中央后回左脑区),58号脑区(中央后回右脑区),75号脑区(豆状苍白球左脑区)。这些脑区如表4-6对分析与ad有关的脑区有很大的帮助。
[0062]
表4-6在ad-lmci组十个社区中挖掘到的重复脑区
[0063][0064]
将以上从各对照组的不同社区中获得的重叠脑区挑选出来,这些脑区有1号脑区(中央前回左脑区),该脑区种子点为(-38.65,-5.68,50.94),10号脑区(眶部额中回右脑区),该脑区种子点为(33.18,52.59,-10.73),45号脑区(楔叶左脑区),该脑区种子点为(-5.93,-80.13,27.22),48号脑区(舌回右脑区),该脑区种子点为(16.29,-66.93,-3.87),57号脑区(中央后回左脑区),该脑区种子点为(-42.46,-22.63,48.92),58号脑区(中央后回右脑区),该脑区种子点为(41.43,-25.49,52.55)。这些脑区的损坏都可能是导致ad的关键原因,如图7,是这些与ad密切相关的脑区所在大脑的位置。
[0065]
模块度是newman提出来的。他先后发表了很多与社区划分相关的论文,其中论文里包括2002年发表的著名的gn算法,和2004发表的fast newman(fb)算法,模块度就是fb算法中提出的。在2006年的时候newman重新定义了模块度,使其适用于spectral optimizationalgorithms。早期的算法不能够很好的确认什么样的社区划分是最优的。模块度这个概念就是为了定义一个对于社区划分结果优劣的评判。
[0066]
q就是模块度如公式4.7,模块度越大则表明社区划分的准确度就越高。q值的范围在[-0.5,1),本文中q值处于0.3至0.7之间则说明聚类的效果非常好,而超过0.7的可能性几乎没有。
[0067][0068]
假设有x个节点,每个节点都代表一个输入,并且将这些输入的脑区划分为了n个
社区,节点彼此之间一共有m个连接。其中a和b是x的任意两个节点,当两个节点直接相连时a
ab
=1,否则a
ab
=0。ka代表的是节点a的度,度是图论的基础知识,从一个节点出发有几个边,则节点的度是多少。这里的2m就是整个图中的度(每个节点都要计算一次度,那么每条边要对应两个节点,则该值要乘以2)。用来判断节点a和b是否在同一个社区内,在同一个社区内不在同一个社区的话
[0069]
将三组相似度最高的社区作为1号社区,通过各脑区与1号社区中的脑区以直接或间接的方式连接的脑区,可视为2号社区。如图8为各组q值的大小,q值越大,则反应社区划分的精准度越高。
[0070]
如图8可以看到,各对照组的q值均在0.3到0.7之间,因此得到社区划分的精准度较高。
[0071]
对于数据集的具体分析如下:
[0072]
实验所用数据来源为adni的数据库(https://adni.loni.usc.edu),研究数据涉及同一被试的模态信息,为静息态核磁共振数据(rs-fmri)数据,图像和数据档案(ida)是神经成像实验室的一部分,也被称为loi,它在神经科学的研究方面有广泛的历史。它通过对各种影像进行分析来揭示大脑结构以及功能活动规律。随着计算机性能的不断提升,ida或许将成为一种用于探索脑发育、疾病发生等问题的重要工具。该实验室从上世纪90年代末开始管理来自多中心研究的神经影像学数据,从而导致ida的开发。国际开发协会从2002年以来一直在不断运作,目前已有80多项研究的数据可供查阅。如图9,图10为adni数据库里的未经处理的脑影像。
[0073]
实验所用数据均来自adni数据库,研究数据涉及同一被试的模态信息,为静息态核磁共振数据(rs-fmri)数据,将其分为三个研究组:ad组与cn组,ad组与emci组,ad组与lmci组。
[0074]
mni是一个基于脑区分割和神经解剖基础上进行的神经科学实验平台,主要用于对不同类型脑功能区在大脑皮层中分布情况以及与疾病之间关系的研究。目前已广泛应用于临床科研领域。aal模板共116个区域,但只有90个属于脑,其余26个属于小脑结构,研究较少,aal模板如图11所示。
[0075]
从功能连接矩阵中分别得到四组人员的最短路径,再通过公式3.7得到它们每组的平均最短路径,如图12所示ad、cn、emci、lmci组关于最短路径的小提琴图对照。
[0076]
ad组的最短路径平均值为0.38,cn组的最短路径平均值为0.36,emci组的最短路径平均值为0.33,lmci组的最短路径平均值为0.35。ad组的最短路径长度超过了健康对照组,最短路径长度体现的是2个节点的信息传递的平均效率,距离最短路径越近该功能脑网络的信息传递效率也越好,表明了ad功能脑网络的信息传递的平均效率远小于健康对照组。
[0077]
聚类系数c一般被用作表征大脑网络中局部脑区信息处理效率的指标。再通过公式3.9来获得各组平均的聚类系数。如图12ad、cn、emci、lmci组关于聚类系数的小提琴图对照。
[0078]
ad组的聚类系数平均值为0.091,cn组的聚类系数平均值为0.1,emci组的聚类系数平均值为0.096,lmci组的聚类系数平均值为0.097。ad组的聚类系数低于健康对照组的
聚类系数,而聚类系数的作用是分析信息的整合能力,所以说前者用于分析功能性脑网络信息的整合能力下降,并且emci组与lmci组的聚类系数也低于cn组的聚类系数,因此有认知障碍的患者用于分析功能性脑网络信息的能力也下降了。并且有部分阿尔兹海默症患者,轻度认知障碍患者与晚期认知障碍患者的聚类系数相对较低,可以看出患病的脑网络局部脑区信息处理效率下降了。
[0079]“小世界”属性是由最短路径的值除以聚类系数的值,其平均值如公式3.10,如图13ad、cn、emci、lmci组关于小世界属性的小提琴图对照。
[0080]
ad组的“小世界”属性平均值为0.13,cn组的“小世界”属性平均值为0.16,emci组的“小世界”属性平均值为0.13,lmci组的“小世界”属性平均值为0.12。实验表明,在0.1-0.28的稀疏范围内,它们都具有“小世界”属性,因此ad组、emci组、lmci组、cn组都具有“小世界”属性。ad组、emci组、lmci组的“小世界”属性均低于cn组即健康对照组,如图3-6。总的来说,与健康对照组相比较,ad患者的异常的“小世界”属性可能是导致ad患者认知能力下降的原因之一。
[0081]
由图14清晰可见ad组与cn组有明显差异的脑区:楔叶(cuneus,cun),梭状回(fusiform gyrus,ffg),这两个脑区可能是导致阿尔兹海默症患者与常人不同的原因之一,接下来主要看看这两个脑区负责的主要功能,即导致常人患上阿尔兹海默症的脑区缺陷。
[0082]
图15清晰可见ad组与emci组有明显差异的脑区:回直肌(gyrus rectus,rec),中央后回(postcentral gyrus,pocg)。
[0083]
由图16清晰可见ad组与lmci组有明显差异的脑区:补充运动区(supplementary motor area,sma),嗅皮质(olfactory cortex,olf),内侧额上回(superior frontal gyrus,medial,sfgmed),前扣带和旁扣带脑回(anterior cingulate and paracingulate gyri,acg),海马旁回(parahippocampal gyrus,phg),舌回(lingual gyrus,ling)。
[0084]
在三个对照组中对十个社区用社区发现算法进行挖掘,获得了多个重复脑区,并再次进行对此筛选,将它们的重复脑区挑选出来,如图17是经过多次挑选后得到的脑区。
[0085]
这些脑区有1号脑区(中央前回左脑区),10号脑区(眶部额中回右脑区),45号脑区(楔叶左脑区),48号脑区(舌回右脑区),57号脑区(中央后回左脑区),58号脑区(中央后回右脑区)。这些脑区的损坏都可能是导致ad的关键原因。其中45号脑区即楔叶脑区在对ad-cn组差异脑区分析中出现过,48号脑区即舌回脑区在ad-lmci组差异脑区分析中出现过,57号脑区即中央后回脑区在ad-emci组差异脑区分析中出现过。
[0086]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1