一种基于模拟退火算法的假结RNA结构预测方法与流程
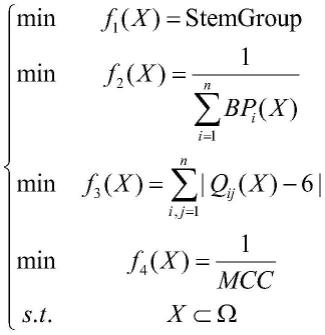
一种基于模拟退火算法的假结rna结构预测方法
技术领域
1.本发明涉及生物工程技术领域,特别涉及一种一种基于模拟退火算法的假结rna结构预测方法。
背景技术:
2.rna(脱氧核糖核酸)是生物系统内最为重要的分子之一,它在生物体内具备多种功能。在最初的生物中心法则中,rna被认为在表达遗传信息时作为蛋白质翻译,发挥了一部分短暂的作用。后来的研究发现,rna除了翻译蛋白质,还具有多种其它功能,如调控基因表达、转运rna、催化肽链形成和指导蛋白质合成等。随着科研工作者对rna研究的逐步深入,rna带给人们的形象也随之发生了变化。rna被认为不仅仅是dna到蛋白质之间的一种信息传递中介,它逐渐由功能单一的简单线性碱基序列,演变成种类多样、结构复杂、功能特异的生命核心物,同时rna在中心法则中,取得了与dna和蛋白质同样重要的地位。在rna结构预测算法的研究上,近些年来虽然衍生了许多新的算法,但是从根本上而言,还是在原先经典算法的基础上加以改进的结果。因此从预测效率的角度来看其时间复杂度和空间复杂度并未取得大的改进。目前rna二级结构预测的算法主要有比较序列分析和热力学最小自由能两种,由于比较序列分析法需要知道多个与之同源的序列及相应的二级结构信息因此相对于后者而言发展缓慢。当仅有一个rna序列或者序列为差异很小的rna小家族时,比较序列分析方法根本不适用。而后一种方法依据碱基配对和自由能分配规则,搜索有最小自由能量的二级结构。其基本假设是具有最小自由能量的rna二级结构是最稳定的,并且最接近真实的rna生物分子结构。以基于热力学的最小自由能算法是近年来rna二级结构预测算法的代表,并在此算法基础之上得到了很大的改进和演进,出现很多其他的算法。
3.由于生物信息学领域新的数据呈现指数增长,海量的序列数据信息使得最小自由能算法的发展极其迅速。由于rna分子具有降解速度快,难以结晶等特点,故通过x射线晶体衍射和nmr等实验方法去测定rna分子的立体结构很不容易。计算机技术的快速发展使得各种复杂的预测算法在计算机上得以实现由此带动各种rna预测算法的不断涌现。虽然现在各种各样的rna算法层出不穷,但是大多数是在原先经典算法的基础之上加以改进以求计算精度和时间复杂度等,没有真正解决问题的难点。如,对于rna二级结构预测问题有核磁共振、图形化暴力破解等传统物理方法可以较为准确的得到rna结构,然而其结构并不稳定,使得这些物理方法都会消耗巨大的资源和时间且得到的结果也未必是准确的结构。但是通过rna一级结构去预测其二级结构的过程是相当复杂的,其一,随着rna分子长度的增加,其预测难度将呈指数级提升,较长的rna分子十分难去预测;其二,在真实的rna结构中存在假结,这种假结结构预测准确度更低。当下rna二级结构主流的预测算法中,基于序列比较分析的算法需要大量的先验已知序列信息,如果信息不足其预测准确度不高;基于动态规划的算法计算成本较高;基于启发式算法,在有限的资源内,通过种群的寻优策略给出一个近似解决方案作为预测结果来预测rna二级结构,但是这种方式得到最小自由能的近似值往往会导致预测结果录入的是局部最优的结果。rna二级结构中茎区有时会形成一种
特殊的位置关系,称之为假结(pseudoknot)。假结作为一种特殊的结构,是实现结构功能的重要因素。但是因为碱基相互重叠的特性,生物信息计算对假结的预测难以奏效。预测包含假结的rna二级结构问题是np难的,但要分析rna的真实结构,对假结的准确预测是必须解决的问题。假结结构对rna分子起着十分重要的作用,假结的相关研究实验也变成了rna二级结构预测中的重中之重。
4.由于rna是一种强柔性的分子体系,其势函数的维数巨大、表达式本身性态差,存在极多局部极小点,使得模型计算较为复杂,数值计算缓慢且困难。为了得到结构稳定的rna结构,解决rna结构预测中数值计算的难点,本发明针对rna最大互补碱基对和最小分组两个优化目标,提出了一种基于模拟退火算法的假结rna结构预测算法。经典模拟退火算法的主要特点是在搜索的过程中,不仅接受优化解,也以一定的概率接受恶化解,这样就容易陷入局部最优解。本发明针对假结rna结构预测模型中目标函数的多极值多变量的特点,给出了模拟退火算法的新解产生方式,模拟退火算法进行改进。并通过非支配排序和拥挤距离排序来保证迭代点不断向pareto前沿收敛,直到算法迭代到最大次数从而输出结果集,算法具有更好的计算效率。
技术实现要素:
5.为了克服现有技术的不足,本发明结合最优化技术,提出了一种基于模拟退火算法的假结rna结构预测方法,有效得到问题最优解,预测效率较高,收敛性较好,弥补了现有方法的缺陷。
6.本发明的技术方案为:一种基于模拟退火算法的假结rna结构预测方法,所述假结rna结构预测方法涉及rna二级结构及其自由能,所述rna二级结构包含一种梯子结构,所述rna二级结构的自由能能根据近邻热力学参数计算出来,随着rna序列长度的增加,二级结构候选解的数量也呈指数量级增加,所述梯子结构指的是一组依次连续匹配的核苷酸,形成一种梯子状的结构,这种结构被认为是rna二级结构中的稳定结构梯子结构的预测可以决定几乎整个rna的二级结构,对于带假结rna二级结构的预测用到生物信息学中的评价参数:敏感性se和特异性sp,预测结果中,敏感性指的是正确碱基数占实际碱基数的百分比,而特异性是指在预测结果的所有碱基中正确预测的碱基所占百分比,马休兹相互作用系数mcc是通过比对天然结构与预测结构而计算出来的值,它兼顾了敏感性与特异性,最小值为-1,表示预测结构与天然结构碱基配对相似度为0;最大值为1,表示预测结构与天然结构相似度为1。
7.对假结rna二级结构进行预测,建立一个多目标最优化模型p:
8.(p)
ꢀꢀꢀ
9.其中:
10.ω是以茎区pair为变量的决策空间,
11.x是一个或则多个茎区组成的茎区集合pairs,
12.i表示rna序列第i个碱基的序列,
13.xi表示该碱基的配对号,在算法中被看作一个个体,
14.f1(x)用于评价rna二级结构中茎区结构的数量,stemgroup为茎区数量,用来评价rna二级结构配对碱基对的数量,即总的碱基配对数,
[0015][0016]qij
(x)=m(class(xi),class(xj))+p(distance(xi,xj))+k是每个碱基对的匹配得分,其中class()是类型运算符,输出该碱基类型。distance()是距离运算符,输出这两个碱基的相对距离,k是常系数,m(class(xi),class(xj))是匹配类型得分,p(distance(xi,xj))是匹配距离得分。
[0017]
用于刻画马休兹相互作用系数,具体衡量公式如下:
[0018][0019]
其中,tn表示正确预测的不配对的碱基的个数。tp(true positive)表示预测结果中正确的碱基对个数,fp(false positive)表示预测结果中不存在于实际结构中的碱基对数,fn(false negative)表示没有预测出的碱基对个数。
[0020]
模型转化
[0021]
由于多目标最优化模型(p)中三个目标是相互冲突的,一个是取最小,而另一是取最大。为了更有利于理论分析与数值计算,本发明令最大。为了更有利于理论分析与数值计算,本发明令则多目标最优化模型(p)可转化为:
[0022]
(p1)
ꢀꢀꢀ
[0023]
显然,通过这种处理,其目标空间中的三个目标都是最小化问题,模型更适合于数值计算。
[0024]
算法设计
[0025]
离散优化问题是数学规划和运筹学中最有意义,但也是较困难的领域之一。本发
明的多目标最优化模型(p1)的设计变量是离散的,是离散多目标优化问题最显著的特点,也是离散优化问题的难点所在。当求解复杂的离散优化问题时,在给定的有限计算资源和时间内我们无法求解出最优解,因此可以采用次优解来近似替代最优解的思想为解决此类问题提供了一个可行思路。目前主流采用启发式类的算法进行求解该类问题,比如模拟退火、遗传和多目标模拟退火算法等。由于rna自然折叠结构到自身最小自由能状态的过程与退火过程非常类似,因此,采用模拟退火算法成为了解决该问题的首选。为解决(p1)的计算难点,本发明设计蛋白质rna结构预测的模拟退火算法,包括以下步骤:
[0026]
第一步:用区间分半法确定初始温度t
max
,每一温度下迭代次数l
max
,邻域规模因子scale,温度下降因子dt;
[0027]
第二步:构建适应函数f(x)=f1(x)f2(x)f3(x)f4(x)
[0028]
第三步:利用随机数发生器随机产生初始解xu,xd是x的上下界。计算适应函数值fun0=f(x0);
[0029]
第四步:判断是否满足终止条件(一般采取两种准则:一个是给定终止温度;另一个是连续多次降温,能量函数值不再下降),若满足则结束;否则,令t:=t*dt,l:=1,转第五步;
[0030]
第五步:从{1,2,
…
,n}中随机选取一个数r,使x0中第r个变量产生随机扰动:rand为-1到1之间一个随机数,是x0中第r个变量的上界和下界,scale是邻域规模因子(一般在0.2到0.5之间)。如果xr超出上下边界,进行边界处理,从而得到一个新解x=(x1,x2,...,xn),计算新解的适应值函数值fun=f(x);
[0031]
step5计算目标函数差df=fun-fun0,根据metropolis法则,判断是否接受新解。
[0032]
若接受,令x0:=x,fun0=fun;否则,x0:=x0,fun0=fun0;
[0033]
step6若满足l》l
max
,转第四步,否则l=l+1,转第五步。
[0034]
本发明有益效果
[0035]
设计一种基于启发式算法的rna结构预测方法,其有益效果如下:
[0036]
第一,对rna结构预测建立了多目标最优化模型,把一个具有冲突目标的多目标最优化问题,转变为无冲突目标的多目标最优化问题,简化了问题,更容易进行数值计算。第二,本发明设计出的模拟退火算法可以更好的避免局部最优解的陷阱,降低了算法的复杂度,可以得到问题的全局最优解。第三,利用梯子结构和马休兹相互作用系数,使得模型能更好的预测具有假结rna结构。
具体实施方式:
[0037]
本发明涉及一种基于模拟退火算法的假结rna结构预测方法,所述假结rna结构预测方法涉及rna二级结构及其自由能,所述rna二级结构包含一种梯子结构,所述rna二级结构的自由能能根据近邻热力学参数计算出来,随着rna序列长度的增加,二级结构候选解的数量也呈指数量级增加,所述梯子结构指的是一组依次连续匹配的核苷酸,形成一种梯子状的结构,这种结构被认为是rna二级结构中的稳定结构梯子结构的预测可以决定几乎整个rna的二级结构。因为很显然,rna的二级结构描述的就是碱基配对的信息,碱基只包含匹配或者不匹配两种可能。如果预测出了rna中所有的梯子结构,那么等于预测出了几乎所有
的匹配情况。梯子结构由一系列依次匹配的碱基对构成,梯子结构的得分将简单的由每个碱基对的得分累加而成,得分接近于6则可视为梯子结构越稳定。目前非假结rna二级结构的预测方法已经相对比较成熟,在算法性能上也有了很大提升,但对于带假结rna二级结构的预测发展比较缓慢,主要的原因是假结种类复杂多样。对于rna结构预测的性能指标,经常会用到生物信息学中的评价参数:敏感性(se)和特异性(sp)。预测结果中,敏感性指的是正确碱基数占实际碱基数的百分比,而特异性是指在预测结果的所有碱基中正确预测的碱基所占百分比。马休兹相互作用系数mcc(matthews correlation coefficient)是通过比对天然结构与预测结构而计算出来的值,它兼顾了敏感性与特异性,最小值为-1,表示预测结构与天然结构碱基配对相似度为0;最大值为1,表示预测结构与天然结构相似度为1。
[0038]
因此,本项目对假结rna二级结构进行预测,建立如下多目标最优化模型(p):
[0039]
(p)
ꢀꢀꢀ
[0040]
其中:
[0041]
ω是以茎区pair为变量的决策空间,
[0042]
x是一个或则多个茎区组成的茎区集合pairs,
[0043]
i表示rna序列第i个碱基的序列,
[0044]
xi表示该碱基的配对号,在算法中被看作一个个体,f1(x)用于评价rna二级结构中茎区结构的数量,stemgroup为茎区数量,用来评价rna二级结构配对碱基对的数量,即总的碱基配对数,
[0045][0046]qij
(x)=m(class(xi),class(xj))+p(distance(xi,xj))+k是每个碱基对的匹配得分,其中class()是类型运算符,输出该碱基类型。distance()是距离运算符,输出这两个碱基的相对距离,k是常系数,m(class(xi),class(xj))是匹配类型得分,p(distance(xi,xj))是匹配距离得分。
[0047]
用于刻画马休兹相互作用系数,具体衡量公式如下:
[0048][0049]
其中,tn(true negative)表示正确预测的不配对的碱基的个数。tp(true positive)表示预测结果中正确的碱基对个数,fp(false positive)表示预测结果中不存在于实际结构中的碱基对数,fn(false negative)表示没有预测出的碱基对个数。
[0050]
二、模型转化
[0051]
由于多目标最优化模型(p)中三个目标是相互冲突的,一个是取最小,而另一是取最大。为了更有利于理论分析与数值计算,本发明令最大。为了更有利于理论分析与数值计算,本发明令则多目标最优化模型(p)可转化为:
[0052]
(p1)
ꢀꢀꢀ
[0053]
显然,通过这种处理,其目标空间中的三个目标都是最小化问题,模型更适合于数值计算。
[0054]
三、算法设计
[0055]
离散优化问题是数学规划和运筹学中最有意义,但也是较困难的领域之一。本发明的多目标最优化模型(p1)的设计变量是离散的,是离散多目标优化问题最显著的特点,也是离散优化问题的难点所在。当求解复杂的离散优化问题时,在给定的有限计算资源和时间内我们无法求解出最优解,因此可以采用次优解来近似替代最优解的思想为解决此类问题提供了一个可行思路。目前主流采用启发式类的算法进行求解该类问题,比如模拟退火、遗传和多目标模拟退火算法等。由于rna自然折叠结构到自身最小自由能状态的过程与退火过程非常类似,因此,采用模拟退火算法成为了解决该问题的首选。为解决(p1)的计算难点,本发明设计蛋白质rna结构预测的模拟退火算法,包括以下步骤:
[0056]
第一步:用区间分半法确定初始温度t
max
,每一温度下迭代次数l
max
,邻域规模因子scale,温度下降因子dt;
[0057]
第二步:构建适应函数f(x)=f1(x)f2(x)f3(x)f4(x)
[0058]
第三步:利用随机数发生器随机产生初始解xu,xd是x的上下界。计算适应函数值fun0=f(x0);
[0059]
第四步:判断是否满足终止条件(一般采取两种准则:一个是给定终止温度;另一个是连续多次降温,能量函数值不再下降),若满足则结束;否则,令t:=t*dt,l:=1,转第五步;
[0060]
第五步:从{1,2,
…
,n}中随机选取一个数r,使x0中第r个变量产生随机扰动:rand为-1到1之间一个随机数,是x0中第r个变量的上界和下界,scale是邻域规模因子(一般在0.2到0.5之间)。如果xr超出上下边界,进行边界处理,从而得到一个新解x=(x1,x2,...,xn),计算新解的适应值函数值fun=f(x);
[0061]
step5计算目标函数差df=fun-fun0,根据metropolis法则,判断是否接受新解。
[0062]
若接受,令x0:=x,fun0=fun;否则,x0:=x0,fun0=fun0;
[0063]
step6若满足l》l
max
,转第四步,否则l=l+1,转第五步。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1