一种肾脏纤维化预测模型的构建方法、系统、终端及介质
1.本发明涉及肾脏纤维化检测技术领域,尤其涉及一种肾脏纤维化预测模型的构建方法、系统、终端及介质。
背景技术:
2.慢性肾脏病(chronic kidney disease,ckd)是以肾脏结构异常或肾功能持续性恶化为主要病变特点的一大类疾病。肾脏纤维化是不同病因的ckd患者发展为终末期肾病所必经的共同的病理路径,是ckd病变恶性进展的独立危险因素之一,所以肾脏纤维化程度的早期诊断及准确分期,对于疾病诊断、病情评估、判断预后、指导临床治疗决策,防止、延缓、甚至最终逆转肾脏纤维化的发生、发展,从而改善ckd患者预后情况,具有重要的临床意义。
3.目前,对肾脏纤维化程度的检测,主要依赖于肾活检组织病理学检查、液体活检指标和常规超声检查等检查手段。其中,肾活检组织病理学检查属于有创性检查,难以多次重复动态观察以及进行纵向随访,且存在各种潜在的并发症(包括肾周血肿、感染以及动静脉瘘)等局限性。至于液体活检指标检查,传统的液体活检标志物对ckd病变的进展评估缺乏敏感性,而新颖的生物标志物在转化为临床应用之前,还需要在大型的人群队列以及长期研究中得到进一步验证。最后,当在常规超声检查中获得临床异常值的时候,则表明此时已处于ckd病变的晚期阶段,肾功能损害或肾脏纤维化程度也已经不可逆转,且敏感性有限,不能对肾脏损害程度进行定量分析,即缺乏有效的诊断标准。
技术实现要素:
4.本发明提供了一种肾脏纤维化预测模型的构建方法、系统、终端及介质,筛选出与肾脏纤维化相关联的特征参数,并获取各特征参数对应的回归系数,以提升模型的预测准确性。
5.为了解决上述技术问题,本发明实施例提供了一种肾脏纤维化程度检测模型及其构建方法,包括:
6.获取若干个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果,以作为样本数据集;
7.按照预设的划分比例,对所述样本数据集进行划分,以获得训练数据集和验证数据集;其中,所述训练数据集和所述验证数据集各自包括多个所述ckd 患者对应的所述人口学信息、所述共患病信息、所述液体活检指标、所述常规超声参数、所述右肾皮质弹性信息和所述肾脏纤维化程度病理金标准结果;
8.根据所述训练数据集,确定多个与肾脏纤维化相关联的特征参数;
9.通过多因素二元logistic回归分析法,结合所述训练数据集,获得截距项和所述训练数据集中各所述特征参数对应的回归系数,并根据所述截距项和各所述特征参数对应的回归系数,构建肾脏纤维化预测模型。
10.实施本发明实施例,根据训练数据集,确定多个与肾脏纤维化相关联的特征参数,以减少关联性较低的参数的影响,进而提升模型的预测准确性,并通过多因素二元logistic回归分析法,确定截距项和训练数据集中各特征参数对应的回归系数,即对各特征参数进行权重赋值,以进一步优化肾脏纤维化预测模型的准确性,使得肾脏纤维化预测模型能够为医护人员提供实时准确的肾脏纤维化预测结果,有助于医护人员根据实时的肾脏纤维化预测结果,适应性调整治疗方案。
11.作为优选方案,所述根据所述训练数据集,确定多个与肾脏纤维化相关联的特征参数,具体为:
12.通过lasso算法,对所述训练数据集中的各变量进行均方误差迭代计算,以绘制得到各所述变量对应的lasso系数剖面图;其中,所述人口学信息、所述共患病信息、所述液体活检指标和所述常规超声参数都各自包括至少两个所述变量,所述右肾皮质弹性信息包括的所述变量为swe值;
13.根据所述lasso系数剖面图,从所述训练数据集的所有所述变量中,选取多个具有非零系数的所述变量,作为与肾脏纤维化相关联的所述特征参数。
14.实施本发明实施例的优选方案,利用lasso算法,从样本数据集的所有变量中选取多个具有非零系数的变量,以剔除对肾脏纤维化预测贡献力度较小的变量,进而进一步提升模型的预测性能。
15.作为优选方案,所述通过多因素二元logistic回归分析法,结合所述训练数据集,获得截距项和所述训练数据集中各所述特征参数对应的回归系数,并根据所述截距项和各所述特征参数对应的回归系数,构建肾脏纤维化预测模型,具体为:
16.通过多因素二元logistic回归分析法,结合所述训练数据集中各所述ckd 患者对应的所有所述特征参数和各所述ckd患者对应的所述肾脏纤维化程度病理金标准结果,计算得到所述截距项和各所述特征参数对应的回归系数;
17.将所述截距项和各所述特征参数作为待验证参数,并分别对各所述待验证参数进行统计学意义的验证;
18.利用通过验证的所有所述待验证参数、以及通过验证的所有所述待验证参数对应的所述回归系数,构建所述肾脏纤维化预测模型。
19.实施本发明实施例的优选方案,对经过多因素二元logistic回归分析得到的截距项和训练数据集中各特征参数对应的回归系数,进行统计学意义的验证,以避免不具备统计学意义的截距项或者特征参数对肾脏纤维化预测模型的准确性能造成负面影响。
20.作为优选方案,所述的一种肾脏纤维化预测模型的构建方法,还包括:
21.分别将所述训练数据集和所述验证数据集中各所述ckd患者对应的若干个与肾脏纤维化相关联的特征参数,输入至所述肾脏纤维化预测模型中,并分别输出所述训练数据集中各所述ckd患者出现中重度肾脏纤维化的第一概率值和所述验证数据集中各所述ckd患者出现中重度肾脏纤维化的第二概率值;
22.根据所述第一概率值、所述第二概率值、多个预设阈值、以及所述训练数据集和所述验证数据集中各所述ckd患者对应的所述肾脏纤维化程度病理金标准结果,确定所述第一概率值对应的第一受试者工作特征曲线和所述第二概率值对应的第二受试者工作特征曲线,并根据所述第一受试者工作特征曲线和所述第二受试者工作特征曲线,分析所述肾
脏纤维化预测模型的预测准确性。
23.实施本发明实施例的优选方案,通过训练数据集对应的第一受试者工作特征曲线和验证数据集对应的第二受试者工作特征曲线,体现肾脏纤维化预测模型对训练数据集和验证数据集的预测准确效果的差异,以体现肾脏纤维化预测模型的性能及泛化能力,并根据肾脏纤维化预测模型的预测准确效果与传统检测手段的精度的对比,分析肾脏纤维化预测模型的预测性能优化程度。
24.为了解决相同的技术问题,本发明实施例还提供了一种肾脏纤维化预测模型的构建系统,包括:
25.数据获取模块,用于获取若干个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果,以作为样本数据集;按照预设的划分比例,对所述样本数据集进行划分,以获得训练数据集和验证数据集;其中,所述训练数据集和所述验证数据集各自包括多个所述ckd患者对应的所述人口学信息、所述共患病信息、所述液体活检指标、所述常规超声参数、所述右肾皮质弹性信息和所述肾脏纤维化程度病理金标准结果;
26.数据筛选模块,用于根据所述训练数据集,确定多个与肾脏纤维化相关联的特征参数;
27.模型构建模块,用于通过多因素二元logistic回归分析法,结合所述训练数据集,获得截距项和所述训练数据集中各所述特征参数对应的回归系数,并根据所述截距项和各所述特征参数对应的回归系数,构建肾脏纤维化预测模型。
28.作为优选方案,所述数据筛选模块,具体包括:
29.绘图单元,用于通过lasso算法,对所述训练数据集中的各变量进行均方误差迭代计算,以绘制得到各所述变量对应的lasso系数剖面图;其中,所述人口学信息、所述共患病信息、所述液体活检指标和所述常规超声参数都各自包括至少两个所述变量,所述右肾皮质弹性信息包括的所述变量为swe值;
30.数据筛选单元,用于根据所述lasso系数剖面图,从所述训练数据集的所有所述变量中,选取多个具有非零系数的所述变量,作为与肾脏纤维化相关联的所述特征参数。
31.作为优选方案,所述模型构建模块,具体包括:
32.计算单元,用于通过多因素二元logistic回归分析法,结合所述训练数据集中各所述ckd患者对应的所有所述特征参数和各所述ckd患者对应的所述肾脏纤维化程度病理金标准结果,计算得到所述截距项和各所述特征参数对应的回归系数;
33.验证单元,用于将所述截距项和各所述特征参数作为待验证参数,并分别对各所述待验证参数进行统计学意义的验证;
34.模型构建单元,用于利用通过验证的所有所述待验证参数、以及通过验证的所有所述待验证参数对应的所述回归系数,构建所述肾脏纤维化预测模型。
35.作为优选方案,所述的一种肾脏纤维化预测模型的构建系统,还包括:
36.模型性能评估模块,用于分别将所述训练数据集和所述验证数据集中各所述ckd患者对应的若干个与肾脏纤维化相关联的特征参数,输入至所述肾脏纤维化预测模型中,并分别输出所述训练数据集中各所述ckd患者出现中重度肾脏纤维化的第一概率值和所述验证数据集中各所述ckd患者出现中重度肾脏纤维化的第二概率值;根据所述第一概率值、
所述第二概率值、多个预设阈值、以及所述训练数据集和所述验证数据集中各所述ckd患者对应的所述肾脏纤维化程度病理金标准结果,确定所述第一概率值对应的第一受试者工作特征曲线和所述第二概率值对应的第二受试者工作特征曲线,并根据所述第一受试者工作特征曲线和所述第二受试者工作特征曲线,分析所述肾脏纤维化预测模型的预测准确性。
37.为了解决相同的技术问题,本发明还提供了一种终端,包括处理器、存储器及存储于所述存储器内的计算机程序;其中,所述计算机程序能够被所述处理器执行,以实现所述的肾脏纤维化预测模型的构建方法。
38.为了解决相同的技术问题,本发明还提供了一种计算机可读存储介质,述计算机可读存储介质包括存储的计算机程序;其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行所述的肾脏纤维化预测模型的构建方法。
附图说明
39.图1:为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的流程示意图;
40.图2:为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的二项式偏差图;
41.图3:为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的 lasso系数剖面图;
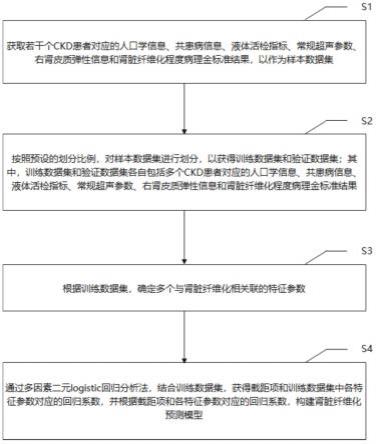
42.图4:为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的训练集roc曲线图;
43.图5:为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的验证集roc曲线图;
44.图6:为本发明实施例一提供的一种肾脏纤维化预测模型的构建系统的结构示意图。
具体实施方式
45.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
46.实施例一:
47.请参照图1,为本发明实施例一提供的一种肾脏纤维化预测模型的构建方法的流程示意图,该方法包括步骤s1至步骤s4,各步骤具体如下:
48.步骤s1,获取若干个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果,以作为样本数据集。
49.在本实施例中,获取被临床诊断为患有ckd的病例,以作为待检测病例,并对所有待检测病例的右肾依次进行二维剪切波弹性成像(twodimensional-shear wave elastography,2d-swe)检查和肾穿刺活检术检查,在检查过程中,剔除满足预设的剔除条件的待检测病例,并以筛选得到的待检测病例,作为步骤s1中所指的ckd患者。其中,剔除条
件为:
①
患有多囊肾、肾结石、肾积水或肾肿块而影响2d-swe数据采集;
②
在进行2d-swe检查的过程中无法根据指令控制呼吸而影响数据采集;
③
因肥胖、精神紧张等原因无法成功开展2d-swe检查;
④
肾穿刺活检病理组织切片达不到肾疾病病理诊断的标准,该标准为切片组织长度<10mm且肾小球数量<10个。
50.需要说明的是,当确定步骤s1中所指的ckd患者时,以所有ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果,作为样本数据集。其中,肾脏纤维化程度病理金标准结果是指基于2012年由美国国家肾脏病基金会制定并颁布的“肾脏病生存质量指导”指南,对ckd患者进行病理性检查得到的结果。
51.步骤s2,按照预设的划分比例,对样本数据集进行划分,以获得训练数据集和验证数据集;其中,训练数据集和验证数据集各自包括多个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果。
52.步骤s3,根据训练数据集,确定多个与肾脏纤维化相关联的特征参数。
53.作为优选方案,步骤s3包括步骤s31至步骤s32,各步骤具体如下:
54.步骤s31,通过lasso算法,对训练数据集中的各变量进行均方误差迭代计算,以绘制得到各变量对应的lasso系数剖面图;其中,人口学信息、共患病信息、液体活检指标和常规超声参数都各自包括至少两个变量,右肾皮质弹性信息包括的变量为swe值。
55.步骤s32,根据lasso系数剖面图,从训练数据集的所有变量中,选取多个具有非零系数的变量,作为与肾脏纤维化相关联的特征参数。
56.在本实施例中,人口学信息、共患病信息、液体活检指标、常规超声参数和右肾皮质弹性信息应当包括但不限于以下变量:人口学信息包括性别、年龄和体质量指数;共患病信息包括是否罹患疾病的信息,疾病包括糖尿病、高血压患病情况和心脑血管疾病;液体活检指标包括总胆固醇、血清尿素氮、血清肌酐、血清尿酸、血清白蛋白、血清葡萄糖、尿蛋白肌酐比、尿白蛋白肌酐比和估算的肾小球滤过率(estimated glomerular filtration rate,egfr值);常规超声参数包括肾脏长轴、肾实质厚度、肾脏血流阻力指数;右肾皮质弹性信息包括swe值。
57.需要说明的是,为了提升模型的预测性能,避免模型出现过拟合现象,本发明采用机器学习中的最小绝对收缩选择算子(least absolute shrinkage andselection operator,lasso)算法,对swe值、人口学信息、共患病信息、液体活检指标和常规超声参数所包括的所有变量进行筛选,以寻找对肾脏纤维化的预测结果具有最强解释力的变量集合。其中,变量筛选的具体流程为:
①
通过lasso算法的十折交叉验证,迭代计算最小交叉验证-均方误差λ
min
,并获取在最小均方误差标准λ
min
的1个标准误差(即1-se标准)下的最优正则化参数λ
.1se
,进而构建对应的log(λ)序列;其中,请参见图2,为关于上述所有变量的二项式偏差图,其纵坐标轴为二项式偏差(binomial deviance),其双坐标轴分别为参数λ对应的log(λ)、以及变量个数k,且所获取的λ
.1se
为0.089,因此 log(λ
.1se
)为-2.412;另外地,十折交叉验证是指将样本数据集随机分为十份,利用其中九份进行训练而另外一份用作测试验证,且该过程可以重复10次,每次用于测试验证的数据不同;
②
请参见图3,依据log(λ)序列,绘制本数据集中各变量的lasso系数剖面图,并选取当log(λ)=log(λ
.1se
)=-2.412
时具有非零系数的3个变量——egfr值、高血压患病情况和swe值,以作为与肾脏纤维化相关联的特征参数;其中,lasso系数剖面图的纵坐标轴为系数(ccoefficients),其双坐标轴分别为参数λ对应的log(λ)、以及变量个数k。另外地,若患有高血压,则高血压患病情况为1,若不患高血压,则高血压患病情况为0。基于此,多个与肾脏纤维化相关联的特征参数分别为egfr值、高血压患病情况和swe值。
58.步骤s4,通过多因素二元logistic回归分析法,结合训练数据集,获得截距项和训练数据集中各特征参数对应的回归系数,并根据截距项和各特征参数对应的回归系数,构建肾脏纤维化预测模型。
59.作为优选方案,步骤s4包括步骤s41至步骤s43,各步骤具体如下:
60.步骤s41,通过多因素二元logistic回归分析法,结合训练数据集中各ckd 患者对应的所有特征参数和各ckd患者对应的肾脏纤维化程度病理金标准结果,计算得到截距项和各特征参数对应的回归系数。
61.在本实施例中,通过多因素二元logistic回归分析法,根据训练数据集中各ckd患者对应的egfr值、高血压患病情况、swe值和肾脏纤维化程度病理金标准结果,计算得到截距项β1、egfr值对应的回归系数β2、高血压患病情况对应的回归系数β3和swe值对应的回归系数β4。
62.步骤s42,将截距项和各特征参数作为待验证参数,并分别对各待验证参数进行统计学意义的验证。
63.步骤s43,利用通过验证的所有待验证参数、以及通过验证的所有待验证参数对应的回归系数,构建肾脏纤维化预测模型。
64.需要说明的是,对各待验证参数进行统计学意义的验证的具体流程为:分别计算β1、β2、β3和β4各自对应的统计学p值,当统计学p值小于0.05时,表明对应的回归系数或者截距项具有统计学意义,即通过统计学意义的验证。
65.在本实施例中,β1、β2、β3和β4都通过统计学意义的验证,则基于β1、β2、β3和β4,构建得到对应的肾脏纤维化预测模型。其中,肾脏纤维化预测模型的表达形式请参照式(1),当需要对某患者进行肾脏纤维化预测时,则将该患者对应的egfr值、高血压患病情况、swe值输入至肾脏纤维化预测模型,以获得对应的出现中重度肾脏纤维化的概率值。
66.logit(y)=β1+β2*egfr值+β3*患有高血压+β4*swe值
67.(1)
68.其中,y为ckd患者出现中重度肾脏纤维化的概率值。
69.作为优选方案,一种肾脏纤维化预测模型的构建方法,还包括步骤s5至步骤s6,各步骤具体如下:
70.步骤s5,分别将训练数据集和验证数据集中各ckd患者对应的若干个与肾脏纤维化相关联的特征参数,输入至肾脏纤维化预测模型中,并分别输出训练数据集中各所述ckd患者出现中重度肾脏纤维化的第一概率值和验证数据集中各ckd患者出现中重度肾脏纤维化的第二概率值。
71.步骤s6,根据第一概率值、第二概率值、多个预设阈值、以及训练数据集和验证数据集中各ckd患者对应的肾脏纤维化程度病理金标准结果,确定第一概率值对应的第一受试者工作特征曲线和第二概率值对应的第二受试者工作特征曲线,并根据第一受试者工作
特征曲线和第二受试者工作特征曲线,分析肾脏纤维化预测模型的预测准确性。
72.在本实施例中,对于同一个模型、同一个训练数据集,设置不同的预设阈值,并结合训练数据集中各ckd患者对应的肾脏纤维化程度病理金标准结果和各ckd患者出现中重度肾脏纤维化的第一概率值,计算得到各预设阈值对应的模型灵敏度(true positive rate,tpr)和特异度(true negative rate,tnr),然后以(1-tnr)为横坐标、以tpr为纵坐标,建立训练数据集对应的第一受试者工作特征(receiver operating characteristic,roc)曲线,其对应的训练集roc曲线图请参见图4。同样地,对于同一个模型、同一个验证数据集,设置不同的预设阈值,并结合验证数据集中各ckd患者对应的肾脏纤维化程度病理金标准结果和各ckd患者出现中重度肾脏纤维化的第二概率值,计算得到各预设阈值对应的模型灵敏度(true positive rate,tpr)和特异度(true negativerate,tnr),然后以(1-tnr)为横坐标、以tpr为纵坐标,建立验证数据集对应的第二受试者工作特征(receiver operating characteristic,roc)曲线,其对应的验证集roc曲线图请参见图5。接着,通过训练集roc曲线图和验证集roc曲线图,确定第一roc曲线对应的roc曲线下面积(area under the curve, auc)为0.94,第二roc曲线对应的auc值为0.84,并根据各自对应的auc值,直观评估肾脏纤维化预测模型对于各数据集的预测准确性。
73.请参照图6,为本发明实施例一提供的一种肾脏纤维化预测模型的构建系统的结构示意图,肾脏纤维化预测模型的构建系统包括数据获取模块1、数据筛选模块2和模型构建模块3,各模块具体如下:
74.数据获取模块1,用于获取若干个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果,以作为样本数据集;按照预设的划分比例,对样本数据集进行划分,以获得训练数据集和验证数据集;其中,训练数据集和验证数据集各自包括多个ckd患者对应的人口学信息、共患病信息、液体活检指标、常规超声参数、右肾皮质弹性信息和肾脏纤维化程度病理金标准结果;
75.数据筛选模块2,用于根据训练数据集,确定多个与肾脏纤维化相关联的特征参数;
76.模型构建模块3,用于通过多因素二元logistic回归分析法,结合训练数据集,获得截距项和训练数据集中各特征参数对应的回归系数,并根据截距项和各特征参数对应的回归系数,构建肾脏纤维化预测模型。
77.作为优选方案,数据筛选模块2,具体包括绘图单元和数据筛选单元,各单元具体如下:
78.绘图单元,用于通过lasso算法,对训练数据集中的各变量进行均方误差迭代计算,以绘制得到各变量对应的lasso系数剖面图;其中,人口学信息、共患病信息、液体活检指标和常规超声参数都各自包括至少两个变量,右肾皮质弹性信息包括的变量为swe值;
79.数据筛选单元,用于根据lasso系数剖面图,从训练数据集的所有变量中,选取多个具有非零系数的变量,作为与肾脏纤维化相关联的特征参数。
80.作为优选方案,模型构建模块3,具体包括计算单元、验证单元和模型构建单元,各单元具体如下:
81.计算单元,用于通过多因素二元logistic回归分析法,结合训练数据集中各ckd患者对应的所有特征参数和各ckd患者对应的肾脏纤维化程度病理金标准结果,计算得到截
距项和各特征参数对应的回归系数;
82.验证单元,用于将截距项和各特征参数作为待验证参数,并分别对各待验证参数进行统计学意义的验证;
83.模型构建单元,用于利用通过验证的所有待验证参数、以及通过验证的所有待验证参数对应的回归系数,构建肾脏纤维化预测模型。
84.作为优选方案,请参照图6,一种肾脏纤维化预测模型的构建系统,还包括:
85.模型性能评估模块4,用于分别将训练数据集和验证数据集中各ckd患者对应的若干个与肾脏纤维化相关联的特征参数,输入至肾脏纤维化预测模型中,并分别输出训练数据集中各所述ckd患者出现中重度肾脏纤维化的第一概率值和验证数据集中各ckd患者出现中重度肾脏纤维化的第二概率值;根据第一概率值、第二概率值、多个预设阈值、以及训练数据集和验证数据集中各ckd患者对应的肾脏纤维化程度病理金标准结果,确定第一概率值对应的第一受试者工作特征曲线和第二概率值对应的第二受试者工作特征曲线,并根据第一受试者工作特征曲线和第二受试者工作特征曲线,分析肾脏纤维化预测模型的预测准确性。
86.所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
87.另外地,本发明实施例还提供了一种终端,包括处理器、存储器及存储于所述存储器内的计算机程序;其中,所述计算机程序能够被所述处理器执行,以实现实施例一所述的肾脏纤维化预测模型的构建方法。
88.优选地,所述计算机程序可以被分割成一个或多个模块/单元(如计算机程序、计算机程序),所述一个或者多个模块/单元被存储在所述存储器中,并由所述处理器执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述终端中的执行过程。
89.所述处理器可以是中央处理单元(central processing unit,cpu),还可以是其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现成可编程门阵列(field-programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,通用处理器可以是微处理器,或者所述处理器也可以是任何常规的处理器,所述处理器是所述终端的控制中心,利用各种接口和线路连接所述终端的各个部分。
90.所述存储器主要包括程序存储区和数据存储区,其中,程序存储区可存储操作系统、至少一个功能所需的应用程序等,数据存储区可存储相关数据等。此外,所述存储器可以是高速随机存取存储器,还可以是非易失性存储器,例如插接式硬盘,智能存储卡(smart media card,smc)、安全数字(secure digital, sd)卡和闪存卡(flash card)等,或所述存储器也可以是其他易失性固态存储器件。
91.另外地,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行实施例一所述的肾脏纤维化预测模型的构建方法。
92.相比于现有技术,本发明实施例具有如下有益效果:
93.本发明提出一种肾脏纤维化预测模型的构建方法、系统、终端及介质,利用实时获
取的样本数据集,确定多个与肾脏纤维化相关联的特征参数,并通过多因素二元logistic回归分析法,确定截距项和训练数据集中各特征参数对应的回归系数,即对各特征参数进行权重赋值,以综合提升肾脏纤维化预测模型的预测准确性,进而使得模型能够为医护人员提供实时准确的肾脏纤维化预测结果。
94.进一步地,利用lasso算法,从样本数据集的所有变量中选取多个具有非零系数的变量,以剔除对肾脏纤维化预测贡献力度较小的变量,进而提升模型的预测性能。同时,对截距项和训练数据集中各特征参数对应的回归系数进行统计学意义的验证,以避免不具备统计学意义的截距项或者特征参数对模型的性能造成负面影响。
95.以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步的详细说明,应当理解,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围。特别指出,对于本领域技术人员来说,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1