一种基于行为分析的听力测试系统及检测方法与流程
1.本发明涉及听力检测技术领域,具体涉及一种基于行为分析的听力测试系统及检测方法。
背景技术:
2.听力损失会影响患者的听觉、言语发育,从而引起语言障碍。严重时会影响其社交能力、心理发展。因此,对于听力损失应尽量做到早诊断、早治疗、早康复。
3.听力损失的诊断主要通过给出一定频率和强度的声音刺激听觉系统以判断其听觉功能损失程度。听力测试有客观的听觉诱发电位检测和纯音听力测试,客观的电生理检测是通过仪器发出一定频率和强度的声音刺激听觉器官,然后收集听力损失者的大脑皮层电位,但由于脑电波信号复杂和干扰较大,且听觉诱发电位检测只能客观地反应听神经和大脑皮层的状况,因此听觉诱发电位检测所获得的结果不具有频率特性,不能获得听力损失者的听力损失准确量的数据。纯音听力测试是对整个听觉通路的测试(外耳—中耳—内耳—听神经),但纯音听力测试需要被测试对象配合,根据所测试的信号给出反馈,如:举手示意,按反馈按键测试人员收到反馈信号给出判定。
4.由于低龄儿童理解力、自我约束力有限,可能存在个别低龄儿童不配合进行纯音听力测试的评估。而测试过程十分依赖测试环境,例如测试场地的大小、测试设备的大小,场地的大小与测试设备大小的匹配度等;还有就是依赖被测试者的主观配合度,以及需要专业人员观察被测试者在听到声音时的动作反应、表情反应等,测试人员能力要求高。因此对低龄儿童进行纯音听力测试比较困难且测试效果不佳。
技术实现要素:
5.本发明的目的之一在于提供一种基于行为分析的听力测试系统,能够适用各种环境并提高对低龄儿童进行纯音听力测试的测试效果。
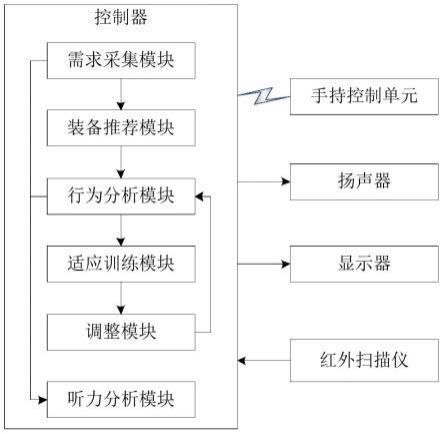
6.为了达到上述目的,提供了一种基于行为分析的听力测试系统,包括手持式控制单元、音频换能器、显示器、红外扫描仪和控制器;所述手持式控制单元包括对应音频换能器的音频模块和对应显示器的视觉展示模块,以及用于向音频模块和视觉展示模块或向音频换能器和显示器输入听令力检测指令的指令输入模块;所述控制器包括以下模块:
7.需求采集模块:用于获取被测试者的年龄数据和进行测试的场地数据;
8.装备推荐模块:用于根据被测试者的年龄数据和进行测试的场地数据,推荐适合的手持式控制单元或音频换能器与显示器的组合进行听力测试;
9.行为分析模块:用于在获取到指令输入模块的输入指令时,通过红外扫描仪扫描并获取被测试者的图像数据;还用于根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,还用于分析计算图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间;若满足,则判定被测试者听到声音,并记录声音的发声类型、发声频率和
发声强度,以及记录被测试者的实际反应时间和实际反应幅度;
10.听力分析模块:用于根据声音的发声类型、发声频率和发声强度,以及被测试者的实际反应时间和实际反应幅度进行数据汇总分析并生成听力图。
11.原理及优点:
12.1.手持式控制单元、音频换能器、显示器、需求采集模块和装备推荐模块的设置,其中手持式控制单元具备了对应音频换能器和显示器的功能,同时具备指令输入的功能。相当于音频换能器和显示器的缩小版,因此两种设备可以适用于不同的环境。例如,小巧的手持式控制单元适用于空间小的地方,而音频换能器和显示器需要较大的空间进行摆放,因此适用于空间较大的环境使用。若由人的主观因素进行选择,不确定性较高,反复尝试的话易浪费时间、人力、物力,因此存在一定的难度。而需求采集模块可先获取被测试者的年龄数据和进行测试的场地数据,再交由装备推荐模块基于年龄数据和场地数据这两种因素来智能推荐适合的设备进行听力测试,从而使得对应设备的选取完全交由系统推荐,设备选取更智能,避免由于人的主观因素带来的不确定性,而反复尝试,以至于浪费时间、人力、物力,而且操作更简单。
13.2.行为分析模块的设置,由于孩童在各个时间段的发育程度不同,就可能导致反应能力不一样,因此听到声音做出响应的动作反馈有快有慢,行为分析模块可以根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,从而避免后续判断失误,进而影响听力测试结果。再通过分析计算红外扫描仪采集的图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间,可高效率且高准确率的自动完成孩童的听力检测,测试人员能力要求低,因此对低龄儿童进行纯音听力测试更加容易且测试效果更佳。
14.进一步,所述发声类型:纯音、窄带噪声、白噪声;所述发声频率包括0.5/1/2/3/4khz;所述发声强度为0-80db hl。便于提高听力测试效果。
15.进一步,所述控制器还包括以下模块:
16.适应训练模块:用于在正式进行听力测试前,生成随机视频指令和随机音频指令,并将随机视频指令和随机音频指令输入至音频模块和视觉展示模块或音频换能器和显示器;所述随机视频指令的执行位于随机音频指令之前,所述随机视频指令和随机音频指令单一执行。
17.适应训练模块的设置,在正式进行听力测试前,生成随机视频指令和随机音频指令,以便让低龄儿童进行适应性训练,调动低龄儿童的兴趣并吸引注意力,从而利于后续正式的听力测试,进而提高听力测试效果。
18.进一步,所述行为分析模块:还用于获取被测试者在训练时的图像数据,并分析计算图像数据中被测试者的脸部表情和转头动作的训练反应时间、训练反应幅度;
19.所述控制器还包括以下模块:
20.调整模块:用于根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调。
21.调整模块的设置,根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调,以便于找到合适的区间值,从而提高听力测试效果。
22.本发明的目的之二在于提供一种基于行为分析的听力检测方法,包括以下步骤:
23.需求采集步骤:获取被测试者的年龄数据和进行测试的场地数据;
24.装备推荐步骤:根据被测试者的年龄数据和进行测试的场地数据,推荐适合的手持式控制单元或音频换能器与显示器的组合进行听力测试;
25.行为分析步骤:在获取到指令输入模块的输入指令时,通过红外扫描仪扫描并获取被测试者的图像数据;再根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,再分析计算图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间;若满足,则判定被测试者听到声音,并记录声音的发声类型、发声频率和发声强度,以及记录被测试者的实际反应时间和实际反应幅度;
26.听力分析步骤:根据声音的发声类型、发声频率和发声强度,以及被测试者的实际反应时间和实际反应幅度进行数据汇总分析并生成听力图。
27.原理及优点:
28.1.手持式控制单元、音频换能器、显示器、需求采集步骤和装备推荐步骤块地设置,其中手持式控制单元具备了对应音频换能器和显示器的功能,同时具备指令输入的功能。相当于音频换能器和显示器的缩小版,因此两种设备可以适用于不同的环境。例如,小巧的手持式控制单元适用于空间小的地方,而音频换能器和显示器需要较大的空间进行摆放,因此适用于空间较大的环境使用。若由人的主观因素进行选择,不确定性较高,反复尝试的话易浪费时间、人力、物力,因此存在一定的难度。而在需求采集步骤中,可先获取被测试者的年龄数据和进行测试的场地数据,再在装备推荐步骤中,基于年龄数据和场地数据这两种因素来智能推荐适合的设备进行听力测试,从而使得对应设备的选取完全交由系统推荐,设备选取更智能,避免由于人的主观因素带来的不确定性,而反复尝试,以至于浪费时间、人力、物力,而且操作更简单。
29.2.行为分析步骤的设置,由于孩童在各个时间段的发育程度不同,就可能导致反应能力不一样,因此听到声音做出响应的动作反馈有快有慢,行为分析模块可以根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,从而避免后续判断失误,进而影响听力测试结果。再通过分析计算红外扫描仪采集的图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间,可高效率且高准确率的自动完成孩童的听力检测,测试人员能力要求低,因此对低龄儿童进行纯音听力测试更加容易且测试效果更佳。
30.进一步,所述发声类型:纯音、窄带噪声、白噪声;所述发声频率包括0.5/1/2/3/4khz;所述发声强度为0-80db hl。便于提高听力测试效果。
31.进一步,所述控制器还包括以下模块:
32.适应训练步骤:在正式进行听力测试前,生成随机视频指令和随机音频指令,并将随机视频指令和随机音频指令输入至音频模块和视觉展示模块或音频换能器和显示器;所述随机视频指令的执行位于随机音频指令之前,所述随机视频指令和随机音频指令单一执行。
33.适应训练步骤的设置,在正式进行听力测试前,生成随机视频指令和随机音频指令,以便让低龄儿童进行适应性训练,调动低龄儿童的兴趣并吸引注意力,从而利于后续正式的听力测试,进而提高听力测试效果。
34.进一步,所述行为分析步骤中再获取被测试者在训练时的图像数据,并分析计算图像数据中被测试者的脸部表情和转头动作的训练反应时间、训练反应幅度;
35.所述方法还包括以下步骤:
36.调整步骤:根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调。
37.调整步骤的设置,能够根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调,以便于找到合适的区间值,从而提高听力测试效果。
附图说明
38.图1为本发明实施例一种基于行为分析的听力测试系统的逻辑框图;
39.图2为听力测试系统各个硬件的架构框图;
40.图3为手持式控制单元的轴侧图;
41.图4为图3中手持式控制单元的后视图;
42.图5为两组音频换能器和显示器按东北方和西北方向安装时的位置示意图;
43.图6两组音频换能器和显示器按正东方和正西方向安装时的位置示意图。
具体实施方式
44.下面通过具体实施方式进一步详细说明:
45.说明书附图中的附图标记包括:头部1、手柄部2、type-c接口3、按键功能指示灯4、操作按钮5、耳机接口6、扬声器7、光激励指示灯8。
46.实施例
47.一种基于行为分析的听力测试系统,基本如图1-图6所示:包括手持式控制单元、音频换能器、显示器、红外扫描仪和控制器等软件、硬件设备。所述音频换能器和显示器搭配设置,设有两组且相对于被测试者中心轴线一左一右分别设置。本实施例中,两组音频换能器和显示器分别设置在被测试者的东北方和西北方向(以被测试者的面朝方面为北方),具体如图5所示。在其他实施例中,两组音频换能器和显示器分别设置在被测试者的正东方和正西方向(以被测试者的面朝方面为北方),如图6所示。方位被限制左右相对的两个方向,从而可以让被测试者在听到声音时的面部表情或头部动作的幅度更大,更有利于后续的分析。
48.所述音频换能器采用扬声器,而显示器则选用常规的27寸的液晶显示器。扬声器具体采用大头式的扬声器,液晶显示器的底座直接设置在扬声器上表面即可,而液晶显示器和扬声器通过有线的方式连接到控制器的输出端,而控制器采用常规的51单片机、微控制器mcu或stem32单片机,主要进行数据传输、数据缓存、信号的数模转换等。
49.所述红外扫描仪设置在被测试者的面对方向;用于记录被测试者受扬声器所发出的不同的频率和强度声音影响时的面部表情和头部动作。与控制器的输入端电连接,采集的数据向传递给控制器。
50.如图3、图4所示,所述手持式控制单元包括外壳和微控制器,所述外壳为锤子状包括头部1和手柄部2。所述头部1的前侧面上设有扬声器7,所述手柄部2后侧面上设有若干操作按钮5。扬声器7和若干操作按钮5分别设置在外壳的前后两侧面上,方便操作。扬声器7作
为声音输出设备,与微控制器的输出端电连接,而若干操作按钮5的部分作为扬声器7控制信号的输入设备,与微控制器的输入端电连接。
51.所述操作按钮5的控制功能包括发声启停、发声类型、发声频率、发声强度。因此包括发声启停操作按钮5、发声类型选择按钮、发声频率调节按钮、发声强度调节按钮,发声频率调节按钮、发声强度调节按钮采用竖直滑动式调节按钮或旋钮式调节按钮。本实施例中,采用竖直滑动式调节按钮,发声类型:包括纯音、窄带噪声、白噪声;发声频率:0.5/1/2/3/4khz;发声强度:0-80db hl。
52.所述手柄部2上与操作按钮5的同侧面且位于操作按钮5的上方,设有用于提示操作按钮5的各个控制功能是否开启的按键功能指示灯4。开启了显示绿色,没开不显色。
53.所述头部1上与扬声器7的同侧面设有光激励指示灯8,光激励指示灯8设有3-5个,且设置在扬声器7的圆形轮廓面上。所述操作按钮5还包括用于启闭光激励指示灯8的光激励控制按钮。
54.所述微控制器设置在外壳内,所述外壳内还设有无线通信模块、电池和存储模块。其中微控制器采用微控制器mcu,具体设置在外壳的头部1。而无线通信模块包括wifi和蓝牙通信。可采用其中一种,或两者都设置,本实施例中两者都设置,以适用多种智能设备之间的无线连接。存储模块采用大容量的可插拔的内存卡。而电池设置在手柄部2内。
55.所述微控制器通过无线通信模块远程连接到控制器,由控制器再通过有线的方式连接到红外扫描仪,红外扫描仪可采用现有的智能红外扫描装置,搭配现有的动作表情识别算法,例如基于cnn的神经网络算法,利用人体红外热成像实现智能动作表情识别分析,判断扫描的图像中被测试者是否有面部表情或头部动作,或识别面部表情或头部动作的具体类别。可直接将动作表情的识别结果发到控制器。在本实施例中,红外扫描仪采用普通的红外扫描仪,而基于cnn的神经网络算法直接设置在控制器中,由控制器进行分析处理。
56.所述微控制器还通过控制器电连接两组扬声器和显示器。所述操作按钮5还包括左右外接扬声器控制按钮和左右显示器控制按钮,如图1中的l声、r声、l图、r图。
57.所述外壳侧面设有数据传输接口,所述数据传输接口通过微处理器电连接手柄部2中设置的电池和存储模块;例如现阶段十分成熟且应用广泛的type-c接口3。所述外壳侧面设有耳机接口6,例如最为常用的3.5mm耳机接口6,可插入入耳式耳机使用。
58.如图1所示,在软件方面,所述控制器包括以下模块:
59.需求采集模块:用于获取被测试者的年龄数据和进行测试的场地数据;场地数据主要为测试场地的长度和宽度。其获取方式直接连接测试者的智能手机,而测试场地的长度和宽度由测试者丈量或步量,精度误差要求10-20cm即可。
60.装备推荐模块:用于根据被测试者的年龄数据和进行测试的场地数据,推荐适合的手持式控制单元或音频换能器与显示器的组合进行听力测试;其中,场地数据为主要判断因素,控制器中设置有数据库,数据库中保存有历史经验数据统计表,通过输入场地数据,以查找的方式从历史经验数据统计表中确认手持式控制单元或音频换能器与显示器的组合进行听力测试。当都符合时,以年龄数据作为二次筛选的条件,各个年龄的孩童好奇心不同,而不同大小的设备对各个年龄孩童的吸引力就不同,基于此进行二次筛选,以确定最合适的设备进行听力测试。
61.行为分析模块:用于在获取到指令输入模块的输入指令时,通过红外扫描仪扫描
并获取被测试者的图像数据;还用于根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,还用于分析计算图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间;若满足,则判定被测试者听到声音,并记录声音的发声类型、发声频率和发声强度,以及记录被测试者的实际反应时间和实际反应幅度;
62.适应训练模块:用于在正式进行听力测试前,生成随机视频指令和随机音频指令,并将随机视频指令和随机音频指令输入至音频模块和视觉展示模块或音频换能器和显示器;所述随机视频指令的执行位于随机音频指令之前,所述随机视频指令和随机音频指令单一执行。
63.所述行为分析模块:还用于获取被测试者在训练时的图像数据,并分析计算图像数据中被测试者的脸部表情和转头动作的训练反应时间、训练反应幅度;
64.调整模块:用于根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调。
65.听力分析模块:用于根据声音的发声类型、发声频率和发声强度,以及被测试者的实际反应时间和实际反应幅度进行数据汇总分析并生成听力图。
66.一种基于行为分析的听力检测方法,用于上述系统的装置,包括以下步骤:
67.需求采集步骤:获取被测试者的年龄数据和进行测试的场地数据;场地数据主要为测试场地的长宽数据。
68.装备推荐步骤:根据被测试者的年龄数据和进行测试的场地数据,推荐适合的手持式控制单元或音频换能器与显示器的组合进行听力测试;
69.行为分析步骤:在获取到指令输入模块的输入指令时,通过红外扫描仪扫描并获取被测试者的图像数据;再根据被测试者的年龄数据匹配听到声音时进行动作反馈的反应时间区间和动作反应幅度区间,再分析计算图像数据中被测试者的脸部表情和转头动作的实际反应时间、实际反应幅度,以及判断是否满足匹配的反应时间区间和动作反应幅度区间;若满足,则判定被测试者听到声音,并记录声音的发声类型、发声频率和发声强度,以及记录被测试者的实际反应时间和实际反应幅度;
70.适应训练步骤:在正式进行听力测试前,生成随机视频指令和随机音频指令,并将随机视频指令和随机音频指令输入至音频模块和视觉展示模块或音频换能器和显示器;所述随机视频指令的执行位于随机音频指令之前,所述随机视频指令和随机音频指令单一执行。
71.所述行为分析步骤:再获取被测试者在训练时的图像数据,并分析计算图像数据中被测试者的脸部表情和转头动作的训练反应时间、训练反应幅度;
72.调整步骤:根据训练反应时间、训练反应幅度对反应时间区间和动作反应幅度区间进行微调。
73.听力分析步骤:根据声音的发声类型、发声频率和发声强度,以及被测试者的实际反应时间和实际反应幅度进行数据汇总分析并生成听力图,例如听阈图。
74.具体实施过程如下:
75.一、确定选用手持式控制单元时,执行适应训练模块,测试人员通过手持式控制单元的操作按钮5给出声音信号、光信号,控制器收到声音信号、光信号生成随机视频指令和
随机音频指令。随机视频指令(即随机灯光控制指令)先给到光激励指示灯8,多个光激励指示灯8随机发光亮起熄灭,以提起被测试者的注意力;再将随机音频指令给到扬声器7,测试人员将手持式听力测试装置在距被测试者的耳朵200mm平行处左边或左边给声,以吸引注意力并进行听力测试,其中发声类型、发声频率和发声强度会随机变化。光信号发出的同时还需将动作表情检测信号分配给红外扫描仪。
76.正式测试开始,测试人员将手持式听力测试装置在距被测试者的耳朵200mm平行处左边或左边给声,当手持式听力测试装置给出声音,被测试者基于本能会做出寻找声音的反馈。若有寻找声音的反馈,则表示被测试者听到声音,若未做出寻找声音的反馈则表示没到听到。
77.寻找声音的反馈数据通过红外扫描仪来获取,例如红外扫描装置在手持式控制单元给出声音后开始扫描被测试者面部表情和头部动作,当被测试者的面部表情或头部动作被识别到(即满足匹配的反应时间区间和动作反应幅度区间),则认为被测试者听到声音。当被测试者的面部表情或头部动作未被识别到(即不满足匹配的反应时间区间和/或动作反应幅度区间),则认为被测试者没听到声音。
78.测试完成后,红外扫描仪的数据传递给控制器,控制器再根据发声类型、发声频率和发声强度进行自动分析计算,以得到被测试者最终的听力测量结果,例如听阈图。
79.二、确定选用扬声器与显示器的组合时,执行适应训练模块,测试人员通过手持式控制单元的操作按钮5给出声音信号、光信号。控制器收到声音信号、光信号生成随机视频指令和随机音频指令。随机视频指令先给到显示器,随机显示动画,以提起被测试者的注意力,随后关闭;再将随机音频指令给到扬声器,以吸引注意力并进行听力测试,其中发声类型、发声频率和发声强度会随机变化。光信号发出的同时还需将动作表情检测信号分配给红外扫描仪。
80.正式测试开始,测试人员通过手持式控制单元给出声音,被测试者基于本能会做出寻找声音的反馈。若有寻找声音的反馈,则表示被测试者听到声音,若未做出寻找声音的反馈则表示没到听到。
81.寻找声音的反馈数据通过红外扫描仪来获取,例如红外扫描装置在手持式控制单元给出声音后开始扫描被测试者面部表情和头部动作,当被测试者的面部表情或头部动作被识别到(即满足匹配的反应时间区间和动作反应幅度区间),则认为被测试者听到声音。当被测试者的面部表情或头部动作未被识别到即不满足匹配的反应时间区间和/或动作反应幅度区间),则认为被测试者没听到声音。
82.测试完成后,红外扫描仪的数据传递给控制器,控制器进行自动分析计算,以得到被测试者最终的听力测量结果,例如听阈图。本方案能高效率且高准确率的自动完成孩童的听力检测,测试人员能力要求低,因此对低龄儿童进行纯音听力测试更加容易且测试效果更佳。
83.以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障
碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1