一种基于数据驱动的肿瘤早筛靶向Panel和分类模型的动态优化方法与流程
一种基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化方法
技术领域
1.本技术涉及生信分析技术领域,具体涉及一种基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化方法及系统。
技术背景
2.2020年全球新发癌症病例1929万例,2020 年全球癌症死亡病例996万例。癌症不久将成为全球死亡的主要原因,虽然开发更加有效的治疗方案是有必要的,但是这也只能延长患者几个月的生存期,因此肿瘤早筛成为了必然的选择。肿瘤早筛不仅可以降低癌症死亡率,而且可以提高治疗的成功率,降低医疗成本和治疗难度,提高患者生命质量。
3.dna甲基化是一种重要的遗传表观修饰,参与许多生物过程和疾病。研究表明,早期阶段的癌症患者没有临床表现,但癌细胞的甲基化模式已经发生了异常改变,并且通过细胞凋亡或坏死后释放到血浆、尿液等体液中,成为血浆中细胞游离dna(cell-free dnas,cfdna) 中的一部分。随着全基因组甲基化测序(whole genome bisulfite sequencing,wgbs)技术的发展,目前已经能够在单碱基对分辨率下进行dna甲基化的全基因组测量,从而实现高精确度的甲基化水平分析。因此,理想情况下,基于cfdna甲基化的液体活检技术可以作为一种非侵入的肿瘤早筛工具。
4.目前主流的基于cfdna甲基化的肿瘤早筛技术存在以下的缺陷和不足:
5.1、传统的cfdna甲基化靶向panel设计一般在项目完成后就不再更改了,例如grail的 galleri等,或者只有在项目需要扩展功能时才会重新设计靶向panel,整个过程都无法实现靶向panel的动态调整,造成项目升级时需要消耗大量的时间和资源。另一方面,在前期设计靶向panel时,有限的肿瘤组织甲基化数据会限制筛选出来的靶向panel区域的精准性,造成靶向panel除了包含这批数据有效信息的区域外还可能会包含部分冗余的区域,此外也会遗漏一些这批数据中没有包含的重要区域。传统靶向panel设计方法不仅没有充分利用下游分析中的分类模型来对靶向panel区域进行优化,而且会由于靶向panel设计区域的限制导致下游数据分析中的性能瓶颈。
6.2、传统的cfdna甲基化数据在下游分析中,分类模型普遍采用机器学习模型,例如grail 的galleri采用的是逻辑回归模型,这会导致一个普遍存在的问题,即随着生产环境中数据的快速增长,特征多样性随之增加,但是分类模型的性能会面临退化现象,不再满足实际应用的需求。另外,当模型性能不佳需要优化时,分类模型面临着大量的重复训练工作,费时费力,无法进行增量学习限制了模型的泛化能力。同时,受制于上游分析中靶向panel设计区域的限制,分类模型的性能瓶颈普遍存在。
7.3、当泛癌早筛技术需要新增癌种时,传统的cfdna甲基化产品因为panel设计区域的限制需要重新设计panel,以便新panel包含新增癌种的异质性区域使下游分析中的分类模型能够区分新增癌种。这种panel设计思路会造成panel包含区域逐渐变大,随之而来的是生产成本的增加。除此之外,下游分析中分类模型也需要重新训练以便提高新分类模型
对新增癌种的分类性能,这个过程中需要消耗大量的时间、人力成本和服务器资源等。
8.综上所述,现有的基于cfdna甲基化的肿瘤早筛技术普通存在靶向panel优化难,分类模型泛化能力不足、新增癌种困难重重的特点。因此,本技术提出了一种基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化方法,可以轻松实现靶向panel和分类模型的良性互动,同时为泛癌早筛技术新增癌种提供了一种更为简单快捷的方式。
9.鉴于此,提出本技术。
技术实现要素:
10.为解决上述技术问题,本技术提出一种基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化方法,本方法可以实现基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化,一方面可以根据实时的靶向panel数据动态优化分类模型,另一方面也可以根据分类模型结果动态优化靶向panel。两者互惠互利,相辅相成,综合提高肿瘤早筛的准确率。
11.具体的,本技术提出如下技术方案:
12.本技术首先提供一种基于数据驱动的肿瘤早筛靶向panel和分类模型的构建方法,所述方法包括如下步骤:
13.1)组织样本收集:收集恶性肿瘤组织样本;
14.2)获得wgbs数据:wgbs测序得到相应wgbs数据;
15.3)设计初始靶向panel:
16.a、根据人类基因组上cpg位点的位置将其上下游区域划分为预选区域;
17.b、计算wgbs数据在预选区域上的统计量;
18.c、根据恶性肿瘤组织样本与其癌旁组织样本在预选区域内统计量差异程度挑选甲基化差异区域(dmr);
19.d、根据恶性肿瘤组织样本与健康人wbc样本在dmr上统计量的差异程度挑选显著的 dmr,显著dmr即为靶向panel设计区域;
20.4)构建初始分类模型:利用恶性肿瘤组织样本和健康人wbc样本的wgbs数据计算每个样本在显著dmr上的统计量,并据此训练分类模型得到初始分类模型;
21.5)收集cfdna样本:收集恶性肿瘤患者和健康人的cfdna样本;
22.6)获得靶向panel数据:对cfdna样本基于初始靶向panel进行测序,得到靶向panel 数据;
23.7)获得分类结果:利用步骤4)的初始分类模型对步骤6)的靶向panel数据进行测试,得到分类结果;
24.优选的,所述方法还包括:
25.8)验证模型性能:对产生分类结果的每个样本来源的个体进行相应癌种的常规筛查检查,获得该样本的真实标签;计算分类模型的真阴性率tnr、真阳性率tpr和或阳性预测值ppv。
26.进一步的,步骤1)中,所述肿瘤组织样本为恶性肿瘤组织样本。
27.进一步的,步骤4)中,所述上下游区域为上下游100bp区域;
28.进一步的,步骤4)中,所述统计量包括甲基化率;
29.进一步的,步骤4)中,所述训练为把每个样本的一组统计量作为该样本特征,对组织样本赋标签,利用样本的特征和标签训练分类模型得到初始分类模型。
30.进一步的,步骤4)中,所述分类模型的结构包括:
31.a、输入层,其网络结构为线性层;
32.b、标准层,包括4层,其网络结构为block结构,所述block结构是以残差结构为基础;
33.c、输出层,其网络结构为线性层和softmax层。
34.进一步的,所述block结构包含主干分支和次干分支,所述主干分支依次包含线性层、 bn层、relu层、线性层、bn层,次干分支包含池化层,两个分支数值相加汇总合并,最后再加relu层。
35.进一步优选的,所述分类模型的结构如下:首先是输入层,网络结构为线性层,输入维度为m,m为靶向panel上dmr的数量;其次为标准层,共有4层,网络结构为block结构;最后是输出层,网络结构为线性层和softmax层,输出维度为n,n为分类的类别数量,具体为需要进行分类的癌种的类别数量加上一个健康人的类别。该分类模型可以轻松通过修改模型的深度、输入维度和输出维度来提高模型的分类能力。
36.更进一步优选的,所述分类模型结构具体如下表所示:
37.网络层名网络层结构输入维度输出维度输入层线性层m10240标准层1block结构102405120标准层2block结构51202560标准层3block结构25601280标准层4block结构12801024输出层线性层+softmax1024n
38.本技术还提供一种基于数据驱动的肿瘤早筛靶向panel和分类模型的动态优化方法,所述方法包括上述步骤,并进一步包括如下步骤:
39.9)判断模型更新次数:判断步骤7)的分类模型对于每一批步骤6)的靶向panel数据学习的次数是否达到阈值n,所述阈值n是模型训练不收敛时终止迭代的条件,即模型训练不收敛时终止迭代轮数,迭代轮数越大,阈值n越大;
40.当所述模型更新次数》阈值n时,包括如下10)-12)步骤:
41.10)加测组织样本wgbs:当所述模型更新次数大于阈值n,加测组织样本wgbs;
42.11)更新靶向panel:根据保留的显著dmr和加测获得的新增显著dmr更新靶向panel;
43.12)更新分类模型:将步骤2)的wgbs数据和步骤10)的加测组织样本wgbs产生的数据合并,基于步骤11)更新的靶向panel计算每个显著dmr上的统计量,并据此训练分类模型得到更新的分类模型;将更新的分类模型对步骤6)中靶向panel数据进行测试,获得分类结果。
44.进一步的,所述步骤10)中,所述加测具体为:对于分类模型在更新多次以后仍然不能正确区分的样本,对这些恶性肿瘤组织样本及其癌旁组织样本进一步进行wgbs测序以获得其完整的测序数据;
45.进一步的,所述步骤11)中,所述更新具体为:根据步骤3)靶向panel上的显著dmr 对分类模型影响的贡献度进行排序,选择对分类模型贡献度大的显著dmr作为保留的显著dmr;根据步骤10)加测的恶性肿瘤组织样本与其癌旁组织样本在预选区域内统计量的差异程度挑选出合适的dmr;并根据步骤3)初始靶向panel中显著dmr筛选原则挑选出显著 dmr作为新增显著dmr;合并保留的显著dmr和新增显著dmr组成更新的靶向panel。
46.进一步的,所述步骤12)中,所述训练为把每个样本的一组统计量作为该样本特征,对组织样本赋标签,利用样本的特征和标签训练分类模型得到初始模型。
47.当所述模型更新次数《阈值n时,包括如下13)步骤:
48.13)更新分类模型:步骤4)中分类模型对每一批步骤6)的靶向panel数据中分类错误的数据和步骤2)获得的wgbs数据合并进行学习,获得更新分类模型;更新分类模型对步骤6)中靶向panel数据进行重测试,获得分类结果。
49.本技术还提供一种基于数据驱动的肿瘤早筛分类模型,所述分类模型的结构包括:
50.a、输入层,其网络结构为线性层;
51.b、标准层,包括4层,其网络结构为block结构,所述block结构是以残差结构为基础;
52.c、输出层,其网络结构为线性层和softmax层;
53.进一步的,所述block结构包含主干分支和次干分支,所述主干分支依次包含线性层、 bn层、relu层、线性层、bn层,次干分支包含池化层,两个分支数值相加汇总合并,最后再加relu层。
54.进一步优选的,所述分类模型的结构如下:首先是输入层,网络结构为线性层,输入维度为m,m为靶向panel上dmr的数量;其次为标准层,共有4层,网络结构为block结构;最后是输出层,网络结构为线性层和softmax层,输出维度为n,n为分类的类别数量,具体为需要进行分类的癌种的类别数量加上一个健康人的类别。该分类模型可以轻松通过修改模型的深度、输入维度和输出维度来提高模型的分类能力。
55.更进一步优选的,所述分类模型结构具体如下表所示:
56.[0057][0058]
本技术还提供一种电子设备,包括:处理器和存储器;所述处理器和存储器相连,其中,所述存储器用于存储计算机程序,所述处理器用于调用所述计算机程序,以执行上述任一项所述的方法。
[0059]
本技术还提供一种计算机存储介质,所述计算机存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时,执行上述任一项所述的方法。
[0060]
本技术至少具有如下有益技术效果:
[0061]
1)本技术实现了一种基于数据驱动的肿瘤早筛靶向panel和分类模型动态优化的方法。一方面可以根据实时的靶向panel数据动态优化分类模型,另一方面也可以根据分类模型结果动态优化靶向panel。两者实现良性互动,互惠互利,相辅相成,综合提高肿瘤早筛的准确率。
[0062]
2)本技术提出来一种基于残差结构的分类模型对癌种进行区分。面对日益增长的数据和泛癌早筛需要新增癌种的需求,该模型可以轻松实现增量学习,具有简单易用,可扩展,泛化能力好等特点。
[0063]
3)本技术可以快速实现泛癌早筛中新增癌种的功能,本技术只需要取得新增癌种的恶性肿瘤及其癌旁的组织样本,然后增加分类模型的类别即可实现,即可以通过流1-13步骤开始,通过快速迭代来实现靶向panel的筛选和分类模型对新增癌种的识别,全程实现增量学习,减少了人为筛选靶向panel和重新训练模型的过程,节省了人力物力财力,从而实现更广泛意义上的泛癌早筛。
附图说明
[0064]
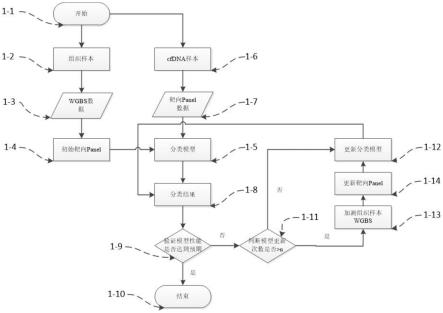
图1、本技术方法流程图;
[0065]
图2、本技术block结构图。
具体实施方式
[0066]
下面将结合实施例对本技术的实施方案进行详细描述,但是本领域技术人员将会理解,下列实施例仅用于说明本技术,而不应视为限制本技术的范围。实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市场购买获得的常规产品。
[0067]
部分术语定义
[0068]
除非在下文中另有定义,本技术具体实施方式中所用的所有技术术语和科学术语的含义意图与本领域技术人员通常所理解的相同。虽然相信以下术语对于本领域技术人员很好理解,但仍然阐述以下定义以更好地解释本技术。
[0069]
如本技术中所使用,在提及单数形式名词时使用的不定冠词或定冠词例如“一个”或“一种”,“所述”,包括该名词的复数形式。
[0070]
如本技术中所使用,术语“包括”、“包含”、“具有”、“含有”或“涉及”为包含性的(inclusive) 或开放式的,且不排除其它未列举的元素或方法步骤。术语“由
…
组成”被认为是术语“包含”的优选实施方案。如果在下文中某一组被定义为包含至少一定数目的实施方案,这也应被理解为揭示了一个优选地仅由这些实施方案组成的组。
[0071]
本技术中的术语“大约”表示本领域技术人员能够理解的仍可保证论及特征的技术效果的准确度区间。该术语通常表示偏离指示数值的
±
10%,优选
±
5%。
[0072]
此外,说明书和权利要求书中的术语第一、第二、第三、(a)、(b)、(c)以及诸如此类,是用于区分相似的元素,不是描述顺序或时间次序必须的。应理解,如此应用的术语在适当的环境下可互换,并且本技术描述的实施方案能以不同于本技术描述或举例说明的其它顺序实施。
[0073]
以上术语或定义仅仅是为了帮助理解本技术而提供。这些定义不应被理解为具有小于本领域技术人员所理解的范围。
[0074]
下面结合具体实施例来阐述本技术。
[0075]
实施例1本技术肿瘤早筛靶向panel和分类模型的构建
[0076]
本技术方法流程如图1所示,本技术具体执行流程如下:
[0077]
1-1、开始:流程开始。
[0078]
1-2、组织样本:因为肿瘤组织样本中甲基化信号与健康人的差异更大,也更有利于靶向 panel的设计,所以收集恶性肿瘤的组织样本作为实验组,例如肺癌的组织样本、肝癌的组织样本等。此外,收集相应恶性肿瘤的癌旁组织样本作为对照组,例如肺癌癌旁的组织样本、肝癌癌旁的组织样本等。另外,收集健康人的白细胞样本(white blood cell,wbc)作为背景组。
[0079]
1-3、wgbs数据:对1-2中收集的恶性肿瘤的组织样本、相应的恶性肿瘤癌旁组织样本和健康人的wbc样本进行wgbs测序,得到相应的wgbs数据。
[0080]
1-4、初始靶向panel:首先,根据人类基因组上的cpg位点的位置将其上下100bp区域划分为一个预选区域,如果相邻预选区域有重叠则划分为同一预选区域。其次,计算1-3w gbs数据在预选区域上的统计量,例如计算预选区域内的甲基化率等。然后,根据恶性肿瘤组织样本与其癌旁组织样本在预选区域内统计量的差异程度挑选出合适的甲基化差异区域 (differential methylation region,dmr)。最后,根据恶性肿瘤组织样本与健康人的wbc样本在dmr上统计量的差异程度挑选出显著dmr,主要目的是为之后检测cfdna样本时,模型能够去除cfdna中wbc的背景噪音,提高恶性肿瘤组织在cfdna中的信号强度。在挑选显著dmr时总体原则有两点:一个是dmr在健康人wbc样本上的背景噪音很小,而且是稳定的、可控的,另一个是dmr很容易区分不同癌种。最终本技术通过以上方法筛选得到12830个显著dmr,这些显著dmr即为靶向panel设计的区域。
[0081]
1-5、分类模型:利用恶性肿瘤组织样本和健康人wbc样本的wgbs数据计算每个样本在显著dmr上的统计量,即可以把每个样本的一组统计量作为该样本的特征。设计恶性肿瘤组织样本的标签为1,健康人wbc样本的标签为0,当有多个类型的恶性肿瘤组织样本时,标签依次为1、2、3等阿拉伯数字。然后,利用样本的特征和标签训练分类模型得到初始模型。
[0082]
1-6、cfdna样本:收集恶性肿瘤患者和健康人的cfdna样本。
[0083]
1-7、靶向panel数据:对cfdna样本基于靶向panel进行测序,得到靶向panel数据。
[0084]
1-8、分类结果:利用1-5中的初始模型对1-6cfdna样本产生的1-7靶向panel数据进行测试,得到分类结果。
[0085]
1-9、验证模型性能是否达到预期:对产生1-8分类结果的每个样本来源的个体进行相应癌种的常规筛查检查,获得该样本的真实标签。然后计算分类模型的真阴性率(true negati ve rate,tnr),真阳性率(true positive rate,tpr),阳性预测值(positive predictive v alue,ppv)等。
[0086]
模型预期的标准主要有两点:一是要确保分类模型的特异性高,即在置信度95%的条件下,tnr要到达99%,因为较低的tnr可以减少在相应癌种筛查人群中的误检率,从而减少临床实施时不必要的诊断检查;二是在标准一的条件下尽可能的提高敏感性(即tpr)和阳性预测值(即ppv)。敏感性的提高会帮助分类模型从相应癌种筛查人群中检测出更多的可疑癌症患者。此外,虽然分类模型可分癌种的增加会降低分类模型的敏感性,但是也会帮助分类模型从相应癌种筛查人群中检测出更多相对数量的可疑癌症患者。ppv的提高会降低相应癌种筛查人群中的漏检率,从而降低从相应癌种筛查人群中遗漏可疑癌症患者的可能性。当分类模型性能达到预期时则跳转至1-10结束,否则跳转至1-11判断模型更新次数是否》n。
[0087]
1-10、结束:结束整个流程。
[0088]
实施例2、本技术模型的动态优化
[0089]
基于上述模型,本实施例对其进行动态优化。
[0090]
1-11、判断模型更新次数(模型迭代次数)是否》n:判断1-8分类模型对于每一批1-6cfd na产生的1-7靶向panel数据学习的次数是否达到阈值n次,阈值n与cfdna的数据量有关,数据量越大,阈值n越大,目的是让分类模型更充分的学习数据中的信息以便获得更好的性能表现。如果模型更新次数小于阈值n,则跳转至1-12更新分类模型,否则跳转至1-13 加测组织样本wgbs。
[0091]
1-12、更新分类模型:对于由1-11跳转来的数据,分类模型对于每一批1-6cfdna产生的1-7靶向panel数据中分类模型分类错误的数据和1-3wgbs数据合并进行学习,以提高其分类性能。然后更新的分类模型对1-7靶向panel数据进行重新测试,得到1-8分类结果。对于由1-14跳转来的数据,首先,将1-3wgbs数据和1-13加测组织样本wgbs产生的数据合并,基于更新的靶向panel计算每个显著dmr上的统计量,得到每个样本一组统计量作为该样本的特征。设计恶性肿瘤组织样本的标签为1,健康人wbc样本的标签为0,当有多个类型的恶性肿瘤组织样本时,标签依次为1、2、3等阿拉伯数字。然后,利用样本的特征和标签训练分类模型即得到更新的模型。将更新的模型对1-7靶向panel数据进行测试,对于这部分样本中在某些显著dmr区域没有数据可以计算统计量的情形,可以默认按照零进行填充。最后得到1-8分类结果。
[0092]
1-13、加测组织样本wgbs:对于那些分类模型在更新多次以后仍然不能正确区分的样本,可能是因为靶向panel设计区域的限制导致某些样本的可区分特征被遗漏了,这时候需要对这些患者的恶性肿瘤组织及其癌旁组织进行wgbs测序以获得其完整的测序数据。
[0093]
1-14、更新靶向panel:首先,根据原来靶向panel上的显著dmr对分类模型影响的贡献度进行排序,按照一定比列选择对分类模型贡献度大的显著dmr作为保留的显著dmr。
其次,根据1-13加测的恶性肿瘤组织样本与其癌旁组织样本在预选区域内统计量的差异程度挑选出合适的显著dmr。然后计算其与健康人的wbc样本在显著dmr上统计量的差异程度,根据1-4初始靶向panel中显著dmr筛选的两个原则挑选出显著的甲基化差异区域作为新增显著dmr。最后,合并保留的显著dmr和新增显著dmr组成更新的靶向panel。最后跳转至1-12更新分类模型。
[0094]
整个流程通过多轮迭代就可以实现基于数据驱动的靶向panel和分类模型的最优化。
[0095]
实施例3、本技术构建的分类模型
[0096]
通过上述方法,构建出的分类模型,具体如下表。
[0097]
分类模型结构表:
[0098]
网络层名网络层结构输入维度输出维度输入层线性层m10240标准层1block结构102405120标准层2block结构51202560标准层3block结构25601280标准层4block结构12801024输出层线性层+softmax1024n
[0099]
如表1所示,分类模型的结构如下:首先是输入层,网络结构为线性层,输入维度为m, m为靶向panel上dmr的数量,在本方法里为12830维,输出维度为10240维。其次为标准层,共有4层,网络结构为block结构,如图2所示,输入维度依次为10240、5120、2560、 1280,输出维度依次为5120、2560、1280、1024。最后是输出层,网络结构为线性层和softm ax层,输入维度为1024,输出维度为n,n为分类的类别数量,具体为需要进行分类的癌种的类别数量加上一个健康人的类别。该分类模型可以轻松通过修改模型的深度、输入维度和输出维度来提高模型的分类能力。
[0100]
如图2所示,block结构是以残差结构为基础设计而成的。因为随着癌种的增加和样本的增加,模型需要训练样本数据量暴增,这时候就需要提高分类模型的深度来提高模型的分类性能以实现对数据更好的学习,而残差结构可以很好的解决分类模型的深度增大而导致的退化问题,从而保证分类模型性能的稳定性。block结构主要包含两个分支,主干分支依次包含线性层、batch normalization(bn)层、relu层、线性层、bn层,次干分支包含一个池化层,然后两个分支数值相加汇总合并,最后再加一个relu层即可。
[0101]
实施例3、本技术的方法用于新增癌种
[0102]
对于原本的泛癌早筛技术需要新增癌种的情形,本技术上述方法抛弃了原先重新设计靶向panel、重新训练分类模型的传统流程,实现了动态优化靶向panel和分类模型。
[0103]
本技术只需要取得新增癌种的恶性肿瘤及其癌旁的组织样本,然后增加分类模型的类别即可实现,即可以通过图1流程图中1-13步骤开始,通过快速迭代来实现靶向panel的筛选和分类模型对新增癌种的识别,全程实现增量学习,减少了人为筛选靶向panel和重新训练模型的过程,节省了人力物力财力。
[0104]
最后应说明的是:以上各实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述各实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依
然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1