一种基于深度嵌入聚类元学习的流行病预测方法
1.本发明涉及流行病预测技术领域,更具体的说是涉及一种基于深度嵌入聚类元学习的流行病预测方法。
背景技术:
2.目前,用于预测流感或其他时间序列数据的机器/深度学习主要分为两类。首先,一些研究人员专注于寻找有效的“特征”。例如,搜索引擎查询数据用于预测google flu trends1中的流感。twitter数据也用于其他研究论文。然而,这些模型通常受到来自互联网搜索等大量信息的不可靠来源的困扰。例如,谷歌的算法很容易过度拟合与流感无关的季节性术语,比如“高中篮球”。这个例子也证明了模型可解释性的重要性。其次,其他研究人员专注于寻找有效的“模型”,例如rf、gradient boosting、multilayer perceptron(mlp)、长短期记忆(lstm)、变压器(tfr)等。基于深度学习的方法,例如transformer因其准确性而受到更多关注,而它们中的大多数都因可解释性差而受苦。此外,统计模型和动态分析模型被认为是用于模拟流感感染模式的易于访问的工具,例如si、sis、sir模型及其变体。然而,它们的参数会发生变化,并且参数的近似是困难的,例如基本再生数r0、人口流动性等。defsi将深度神经网络方法与因果模型相结合,以解决高分辨率ili发病率预测。然而,这些模型中的大多数都严重依赖外部数据来提高准确性,例如经度和纬度以及气候信息
3.因此,提供一种基于深度嵌入聚类元学习的流行病预测方法,基于历史数据,针对疫情新爆发地区,利用少量初期数据,预测未来疫情发展情况是本领域技术人员亟需解决的问题。
技术实现要素:
4.有鉴于此,本发明提供了一种基于深度嵌入聚类元学习的流行病预测方法;利用多个地区疫情传播的时间序列片段学习细粒度的传播模式,并可将学习到的传播模式用于新爆发疫情且仅存在少量历史数据地区的未来预测,仅需要很少的领域知识去构建元学习任务,并具有很好的可解释性;采用基于maml的无监督元学习方法,将疾病传播模型从疫情传播稳定的地区迁移到疫情处于早期阶段的另一个地区。
5.为了实现上述目的,本发明采用如下技术方案:
6.一种基于深度嵌入聚类元学习的流行病预测方法,包括以下步骤:
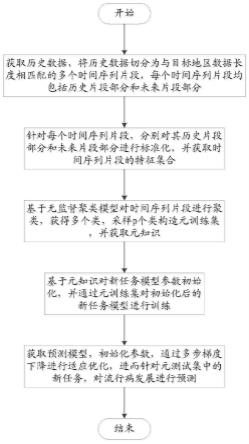
7.s1、获取历史数据,将历史数据切分为与目标地区数据长度相匹配的多个时间序列片段,每个时间序列片段均包括历史片段部分和未来片段部分;
8.s2、针对每个时间序列片段,分别对其历史片段部分和未来片段部分进行标准化,并获取时间序列片段的特征集合;
9.s3、基于无监督聚类模型对时间序列片段进行聚类,获得多个类,采样p个类构造元训练集,并获取元知识,基于元知识对新任务模型参数初始化,并通过元训练集对初始化后的新任务模型进行训练;
10.s4、获取预测模型,初始化参数,通过多步梯度下降进行适应优化,进而针对元测试集中的新任务,对流行病发展进行预测。
11.优选的,所述步骤s1具体包括:
12.获取目标地区i长度为t的已知历史时间序列信息xi,将时间序列信息xi切分为多个长度为ω+δt的时间序列片段集合
[0013][0014]
其中,m为地区的数量,ti为地区i的历史时序数据总长度,为地区i在时刻t的时间序列片段,为时间序列片段在t时刻前的ω个数据,即历史片段部分,其与目标地区i的已知观测数据对齐,为时间序列片段在t时刻后的δt个数据,即未来片段部分,与待预测数据对齐。
[0015]
优选的,所述步骤s2具体包括:
[0016]
s21、分别对历史片段部分和未来片段部分进行标准化:
[0017][0018][0019]
其中,分别为时间序列片段的历史片段部分和未来片段部分的均值,分别为时间序列片段的历史片段部分和未来片段部分的方差,将时间序列片段标准化到0和1之间;
[0020]
s22、对于时间序列片段基于cnn和rnn提取其序列局部特征和时序特征,时间序列片段中的历史片段部分对应已知数据的特征所在,因此时间序列的片段的嵌入表示仅从该部分特征中学习,将时间序列片段集合示仅从该部分特征中学习,将时间序列片段集合投影到嵌入空间z中,生成时间序列片段的特征集合
[0021][0022]
其中,ξ(
·
)为特征编码器,其由cnn和rnn两部分组成为cnn特征提取操作,用于提取时间序列片段的局部特征,为rnn特征提取操作,用于提取时间序列片段的时序特征,θc,θr分别为cnn模型参数和rnn模型参数。
[0023]
优选的,所述步骤s3具体包括:
[0024]
s31、对时间序列片段进行聚类,并学习他们的嵌入,基于深度聚类模型idec,采
用聚类损失来实现对给定输入进行聚类:
[0025][0026]
其中,q
ij
表示由学生t分布测量的时间序列片段zi与聚类中心μj的相似度,p
ij
是聚类的目标分布;
[0027]
按时间序列片段特征集合进行聚类,得到时间序列片段数据集合的一个划分每个聚类都是多个时间序列片段特征的集合,聚类操作定义为:
[0028][0029][0030]
其中,l为所有类别的总数,pi为第i个聚类簇,|pi|表示第i个聚类簇中元素的个数,z为pi中的元素,为l个类别的中心点,||
·
||为二范数;
[0031]
s32、采样p个聚类构建元训练任务集m
train
={d1,d2,
…
,d
p
}表示为p种传播模式,每个聚类di分为queryi和supporti两部分,并对应一个预测任务其中,supporti用于任务的学习适应,即用于基础学习器更新,queryi用于更新元学习器参数;
[0032]
采用最小均方误差作为预测损失:
[0033][0034]
其中,y为真实流行病确诊病例数,为模型预测结果。
[0035]
基学习器学习阶段,每个任务对应一个基学习器,基于supporti数据,基学习器计算损失利用梯度下降最小化损失,找到使损失最小化的最优参数集:
[0036][0037]
其中,θ'i为任务i的最优参数,θ为模型初始参数,α为超参数,为任务i的梯度;
[0038]
元学习阶段,使用queryi数据,基于基学习器学到的最优参数θ'i,元学习器计算相对于这些最优参数θ'i的梯度,更新随机初始化的参数θ,即元知识,使得θ调整到最佳数值,在该最佳数值状态下,应用到某地区未来疫情发展情况预测时,只需少量梯度更新,即可获得较好的预测效果:
[0039][0040]
其中,θ是模型初始参数,β是超参数,是任务在
queryi上获得的相对于参数θ'i的梯度。
[0041]
优选的,所述步骤s4具体包括:
[0042]
针对新的预测任务将其归属到最相近时序片段聚类中,并采样获得support
test
,基于学习到元知识θ,在support
test
进行梯度梯度下降学习,获得适应新任务的模型。
[0043][0044]
其中,θ'
test
为新任务的模型参数,θ为初始参数,即元知识,f
θ
为预测模型。
[0045]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于深度嵌入聚类元学习的流行病预测方法;利用多个地区疫情传播的时间序列片段学习细粒度的传播模式,并可将学习到的传播模式用于新爆发疫情且仅存在少量历史数据地区的未来预测,仅需要很少的领域知识去构建元学习任务,并具有很好的可解释性;采用基于maml的无监督元学习方法,将疾病传播模型从疫情传播稳定的地区迁移到疫情处于早期阶段的另一个地区。
附图说明
[0046]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0047]
图1附图为本发明提供的预测方法流程结构示意图。
[0048]
图2附图为本发明提供的模型框架结构示意图。
具体实施方式
[0049]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
本发明实施例公开了一种基于深度嵌入聚类元学习的流行病预测方法,包括以下步骤:
[0051]
s1、获取历史数据,将历史数据切分为与目标地区数据长度相匹配的多个时间序列片段,每个时间序列片段均包括历史片段部分和未来片段部分;
[0052]
s2、针对每个时间序列片段,分别对其历史片段部分和未来片段部分进行标准化,并获取时间序列片段的特征集合;
[0053]
s3、基于无监督聚类模型对时间序列片段进行聚类,获得多个类,采样p个类构造元训练集,并获取元知识,基于元知识对新任务模型参数初始化,并通过元训练集对初始化后的新任务模型进行训练;
[0054]
s4、获取预测模型,初始化参数,通过多步梯度下降进行适应优化,进而针对元测试集中的新任务,对流行病发展进行预测。
[0055]
为进一步优化上述技术方案,,步骤s1具体包括:
[0056]
获取目标地区i长度为t的已知历史时间序列信息xi,将时间序列信息xi切分为多个长度为ω+δt的时间序列片段集合
[0057][0058]
其中,m为地区的数量,ti为地区i的历史时序数据总长度,为地区i在时刻t的时间序列片段,为时间序列片段在t时刻前的ω个数据,即历史片段部分,其与目标地区i的已知观测数据对齐,为时间序列片段在t时刻后的δt个数据,即未来片段部分,与待预测数据对齐。
[0059]
优选的,步骤s2具体包括:
[0060]
s21、分别对历史片段部分和未来片段部分进行标准化:
[0061][0062][0063]
其中,分别为时间序列片段的历史片段部分和未来片段部分的均值,分别为时间序列片段的历史片段部分和未来片段部分的方差,将时间序列片段标准化到0和1之间;
[0064]
s22、对于时间序列片段基于cnn和rnn提取其序列局部特征和时序特征,时间序列片段中的历史片段部分对应已知数据的特征所在,因此时间序列的片段的嵌入表示仅从该部分特征中学习,将时间序列片段集合中学习,将时间序列片段集合投影到嵌入空间z中,生成时间序列片段的特征集合
[0065][0066]
其中,ξ(
·
)为特征编码器,其由cnn和rnn两部分组成为cnn特征提取操作,用于提取时间序列片段的局部特征,为rnn特征提取操作,用于提取时间序列片段的时序特征,θc,θr分别为cnn模型参数和rnn模型参数。
[0067]
为进一步优化上述技术方案,,步骤s3具体包括:
[0068]
s31、对时间序列片段进行聚类,并学习他们的嵌入,基于深度聚类模型idec,采用聚类损失来实现对给定输入进行聚类:
[0069][0070]
其中,q
ij
表示由学生t分布测量的时间序列片段zi与聚类中心μj的相似度,p
ij
是聚类的目标分布;
[0071]
按时间序列片段特征集合进行聚类,得到时间序列片段数据集合的一个划分每个聚类都是多个时间序列片段特征的集合,聚类操作定义为:
[0072][0073][0074]
其中,l为所有类别的总数,pi为第i个聚类簇,|pi|表示第i个聚类簇中元素的个数,z为pi中的元素,为l个类别的中心点,||
·
||为二范数;
[0075]
s32、采样p个聚类构建元训练任务集m
train
={d1,d2,
…
,d
p
}表示为p种传播模式,每个聚类di分为queryi和supporti两部分,并对应一个预测任务其中,supporti用于任务的学习适应,即用于基础学习器更新,queryi用于更新元学习器参数;
[0076]
采用最小均方误差作为预测损失:
[0077][0078]
其中,y为真实流行病确诊病例数,为模型预测结果。
[0079]
基学习器学习阶段,每个任务对应一个基学习器,基于supporti数据,基学习器计算损失利用梯度下降最小化损失,找到使损失最小化的最优参数集:
[0080][0081]
其中,θ'i为任务i的最优参数,θ为模型初始参数,α为超参数,为任务i的梯度;
[0082]
元学习阶段,使用queryi数据,基于基学习器学到的最优参数θ'i,元学习器计算相对于这些最优参数θ'i的梯度,更新随机初始化的参数θ,即元知识,使得θ调整到最佳数值,在该最佳数值状态下,应用到某地区未来疫情发展情况预测时,只需少量梯度更新,即可获得较好的预测效果:
[0083][0084]
其中,θ是模型初始参数,β是超参数,是任务在queryi上获得的相对于参数θ'i的梯度。
[0085]
为进一步优化上述技术方案,步骤s4具体包括:
[0086]
针对新的预测任务将其归属到最相近时序片段聚类中,并采样获得support
test
,基于学习到元知识θ,在support
test
进行梯度梯度下降学习,获得适应新任务的模型。
[0087][0088]
其中,θ'
test
为新任务的模型参数,θ为初始参数,即元知识,f
θ
为预测模型。
[0089]
评价指标:我们采用均方根误差和皮尔逊相关系数作为度量。rmse值越低越好,而pcc值越高越好。
[0090]
对比方法:
[0091]
–
ar:标准自回归模型
[0092]
–
lstm:使用lstm单元的循环神经网络(rnn)
[0093]
–
tpa-lstm:基于注意力的lstm模型(shih,s.y.,sun,f.k.,lee,h.y.:temporal pattern attention for multivariate time series forecasting.machine learning(2019))
[0094]
–
st-gcn[20]:时空图神经网络
[0095]
–
cnnrnn-res:一种结合cnn、rnn和残差链接进行流行病学预测的深度学习模型(yu,b.,yin,h.,zhu,z.:spatio-temporal graph convolutional networks:a deep learning framework for traffic forecasting.arxiv preprint arxiv:1709.04875(2017))
[0096]
–
saiflu-net:基于自我注意的流感预测模型(jung,s.,moon,j.,park,s.,hwang,e.:self-attention-based deep learning network forregional influenza forecasting.ieee jbhi(2021))
[0097]
–
cola-gnn:一种结合cnn、rnn和gcn进行流行病预测的深度学习模型(deng,s.,wang,s.,rangwala,h.,wang,l.,ning,y.:cola-gnn:cross-location attention based graph neural networks for long-term ili prediction.in:proc.of cikm(2020))
[0098]
不同方法在三个数据集上的rmse和pcc性能,horizon=3,5,10,15。粗体表示每列的最佳结果,下划线表示次优。*表示结果在相应的参考文献中报告
[0099][0100]
我们在短期(范围《10)和长期(范围≥10)设置中评估每个模型。流感数据集如表所示。总体趋势是预测精度随着预测范围的增加而下降,因为范围越大,问题越难。不同数据集之间rmse的巨大差异是由于数据集的规模和方差。
[0101]
我们观察到我们的方法在大多数任务上都优于其他模型。我们的方法在流感预测任务中的rmse分别比最佳基线低5.6%。在流感预测任务中,大多数基于深度学习的模型比统计模型(ha和ar)表现更好,因为它们努力处理时间序列背后的非线性特征和复杂模式。
[0102]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0103]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1