一种基于肌肉力量的糖尿病筛查方法及系统与流程
1.本发明涉及医学模型领域,具体地说是一种基于中国糖尿病风险评分联合心率、最大握力、起坐次数的糖尿病筛查方法及系统。
背景技术:
2.糖尿病大多起病隐匿,无早期特异症状,其诊断常延迟4~7年。如果不能有效管控血糖,很容易导致并发症,进而增加住院率和早期死亡率等,严重威胁生命健康,增加医疗费用和降低生活质量。糖尿病的低诊断率、诊断时的高并发症发生率更加强调了糖尿病筛查的重要意义,早筛查糖尿病有助于患者避免或者延缓严重并发症发生及发展。
3.中国2型糖尿病防治指南推荐纪立农等基于国家糖尿病和代谢综合征研究数据建立的中国糖尿病风险评分。中国糖尿病风险评分纳入年龄、性别、腰围、体重指数(body mass index,bmi)、收缩压(systolic blood pressure,sbp)和糖尿病家族史等变量。现有的糖尿病筛查模型大多围绕上述基本信息,使用各类算法如决策树算法、随机森林算法以及逻辑回归算法对已有数据进行监督训练,从而得到糖尿病筛查模型。
4.近年来,基于糖尿病危险因素、干预措施等方面的研究显示,糖尿病与遗传、行为、环境因素如缺乏体力活动、不健康的饮食习惯、肥胖等有关。但是,现有的糖尿病筛查模型大多关注中国糖尿病风险评分中的基本信息,如年龄、性别、腰围、bmi、收缩压等,而忽略了体力活动相关的信息。
技术实现要素:
5.本发明的目的在于提供一种基于肌肉力量的糖尿病筛查方法及系统,以解决现有糖尿病筛查模型大多关注中国糖尿病风险评分中的基本信息而导致模型对糖尿病筛查预测准确度不高的问题。
6.为实现上述目的,本发明采用如下技术方案:
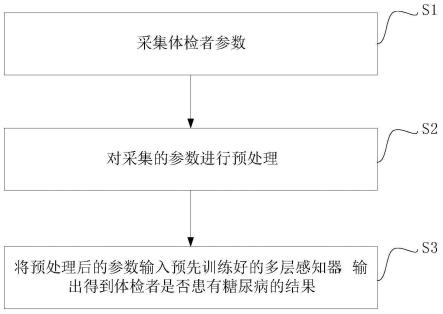
7.一方面,一种基于肌肉力量的糖尿病筛查方法,包括:
8.采集体检者参数,所述参数包括:民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围、心率、最大握力和起坐次数;
9.对采集的参数进行预处理;
10.将预处理后的参数输入预先训练好的多层感知器,输出得到体检者是否患有糖尿病的结果。
11.进一步地,所述对采集的参数进行预处理,包括:
12.对于最大握力、起坐次数、bmi、腰围,采用连续型变量归一化方法进行预处理;
13.对于民族、性别、糖尿病家族史,采用离散型变量独热编码进行预处理;
14.对于收缩压、年龄、心率先将其划分区间,映射为离散型变量,再用离散型变量独热编码进行预处理。
15.进一步地,对于最大握力、起坐次数、bmi、腰围,根据下式进行预处理:
[0016][0017]
其中,m
′
t
为第t个样本归一化处理后的变量数据,m
t
为第t个样本处理前的变量数据,min(m)为处理前变量数据的最小值,max(m)为处理前变量数据的最大值。
[0018]
进一步地,所述多层感知器包括输入层、隐藏层和输出层,所述输入层包含21个输入神经元,所述隐藏层层数为1,包含5个神经元,所述输出层包含1个神经元,所述隐藏层将输入转换成输出层使用的形式为:
[0019][0020]
其中,wj为隐藏节点j到输出层的输出权值,w0为输出层的偏差,gi为激活函数,h为隐藏节点总数,hj为隐藏层的值,其表达式为:
[0021][0022]
其中,v
ij
为输入节点i到隐藏层hj的权重,v
j0
为隐藏节点j的偏差,xi为输入变量。
[0023]
进一步地,所述多层感知器通过以下方法训练得到:
[0024]
获取样本集,每个样本包括民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围、心率、最大握力和起坐次数;
[0025]
对样本集中每个样本数据进行预处理;
[0026]
将预处理后的样本集划分为训练集和测试集,使用训练集对所述多层感知器进行训练,使其输出是否患有糖尿病的结果;
[0027]
使用测试集对所述多层感知器进行测试。
[0028]
另一方面,一种基于肌肉力量的糖尿病筛查系统,包括:
[0029]
采集模块,用于采集体检者参数,所述参数包括:民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围、心率、最大握力和起坐次数;
[0030]
数据预处理模块,用于对采集的参数进行预处理;
[0031]
预测模块,用于将预处理后的参数输入预先训练好的多层感知器,输出得到体检者是否患有糖尿病的结果。
[0032]
进一步地,所述数据预处理模块,包括:
[0033]
第一预处理模块,用于采用连续型变量归一化方法对最大握力、起坐次数、bmi、腰围进行预处理;
[0034]
第二预处理模块,用于采用离散型变量独热编码对民族、性别、糖尿病家族史进行预处理;
[0035]
第三预处理模块,用于将收缩压、年龄、心率划分区间,映射为离散型变量,再用离散型变量独热编码进行预处理。
[0036]
本发明具有以下有益效果及优点:
[0037]
1.本发明所需的指标都可以使用非侵入式方法采集,使得糖尿病的筛查更为普
适、经济、简便、易行;
[0038]
2.本发明在中国糖尿病风险评分的基础上,加入了心率、最大握力和起坐次数这三个反映体力活动情况和肌肉力量的指标,增加了模型对糖尿病筛查的准确度;
[0039]
3.本发明采用多层感知器自动提取输入变量的特征,减少了对医学先验知识的需求。
附图说明
[0040]
图1是本发明实施例的一种基于肌肉力量的糖尿病筛查方法流程图;
[0041]
图2是本发明中多层感知器模型的结构图;
[0042]
图3是加入心率、最大握力、起坐次数前后糖尿病筛查模型在测试集上的结果图;
[0043]
图4为本发明实施例的一种基于肌肉力量的糖尿病筛查系统框图。
具体实施方式
[0044]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出其它创造性劳动前提下所获得的所有其它所有实施例,都属于本发明保护的范围。
[0045]
如图1所示,一种基于肌肉力量的糖尿病筛查方法,包括以下步骤:
[0046]
步骤s1,采集体检者参数;
[0047]
需要采集的参数包括基本信息和额外信息。其中,基本信息包括:中国糖尿病风险评分所指定的指标,即民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围共7个指标;额外信息包括:心率、最大握力和起坐次数共3个指标。
[0048]
步骤s2,对采集的参数进行预处理;
[0049]
在本实施例中,数据预处理采用连续型变量归一化和离散型变量独热编码。
[0050]
对于10个输入变量,最大握力、起坐次数、bmi、腰围是连续型变量,采用连续型变量归一化方法进行预处理,使处理后的变量值均为-1到1之间的实数:
[0051][0052]
其中,m
′
t
为第t个样本归一化处理后的变量数据,m
t
为第t个样本处理前的变量数据,min(m)为处理前变量数据的最小值,max(m)为处理前变量数据的最大值。
[0053]
民族、性别、糖尿病家族史是离散型变量,可以采用离散型变量独热编码进行预处理。
[0054]
例如,对于民族,创建由0和1组成的新变量,以表示原始的分类值。比如民族包含“汉族”、“壮族”、“维吾尔族”、“哈萨克族”、“傣族”和“朝鲜族”,独热编码后:“汉族”为00000,“壮族”为00001,“维吾尔族”为00010,“哈萨克族”为00100,“傣族”为01000,“朝鲜族”为10000。
[0055]
收缩压、年龄、心率先将其划分区间,映射为离散型变量,再用所述的离散型变量独热编码进行预处理。
[0056]
比如,收缩压分为“120以下”、“120-140”、“140-160”、“160以上”,独热编码后:“120以下”为000,“120-140”为001,“140-160”为010,“160以上”为100。
[0057]
步骤s3,将预处理后的参数输入预先训练好的多层感知器,输出得到体检者是否患有糖尿病的结果。
[0058]
如图2所示为本发明实施例中糖尿病筛查模型的结构图,该模型基于多层感知器构建。
[0059]
多层感知器由输入层和输出层组成,输入层由许多接收输入的神经元组成,输出层向外部世界输出,在输入层和输出层之间存在一个隐藏层,它将输入转换成输出层。
[0060]
在本实施例中,将民族、性别、糖尿病家族史、收缩压、年龄、心率、最大握力、起坐次数、bmi、腰围共10个因素作为输入层,以是否为糖尿病为输出层建立多层感知器模型。
[0061]
其中,输入层包含21个输入神经元,隐藏层层数为1,包含5个神经元,输出层包含1个神经元。
[0062]
其中隐藏层将输入转换成输出层可使用的形式为:
[0063][0064]
其中,wj为隐藏节点j到输出层的输出权值,w0为输出层的偏差,gi为激活函数,h为隐藏节点总数,hj为隐藏层的值,其表达式为:
[0065][0066]
其中,v
ij
为输入节点i到隐藏层hj的权重,v
j0
为隐藏节点j的偏差,xi为输入变量。
[0067]
在构建多层感知器模型后,对多层感知器模型进行训练,具体包括:
[0068]
步骤s301,获取样本数据集,每个样本包括民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围、心率、最大握力和起坐次数;
[0069]
步骤s302,对样本集中每个样本数据进行预处理;
[0070]
按照前述步骤s2的数据预处理方法,对每个样本中包含的数据进行预处理。
[0071]
步骤s303,将预处理后的数据集划分为训练集和测试集,使用训练集对所述多层感知器进行训练,使其输出是否患有糖尿病的结果;使用测试集对所述多层感知器进行测试。
[0072]
采用随机抽样的方法,将数据集按8:2的比例划分为训练集和测试集,训练集中的数据用于训练糖尿病筛查模型,测试集中的数据用于测试模型训练结果。
[0073]
训练完成后得到糖尿病筛查模型,使用训练好的糖尿病筛查模型,即可对糖尿病进行筛查。
[0074]
采集新样本的基本信息和额外信息,即待体检者的民族、性别、糖尿病家族史、收缩压、年龄、心率、最大握力、起坐次数、bmi、腰围后,将这些数据按照步骤2所述的预处理方法进行处理,将处理后的数据输入步骤3的糖尿病筛查模型,即可得到该样本是否为糖尿病的最终结果。
[0075]
如图3所示是加入心率、最大握力、起坐次数前后糖尿病筛查模型在测试集上的结果图,测试指标为曲线下面积(area undercurves,auc),其值越大说明筛查准确度越高,最
大值为1。
[0076]
由图3可以看出,仅使用基本信息建立的糖尿病筛查模型,auc值为0.754;在加入部分额外信息(心率)后,auc值有了明显提升;同时加入心率、最大握力和起坐次数这三个指标后,糖尿病筛查模型的auc值达到最高,为0.827。本发明在基本信息的基础上加入三个额外指标,明显地提升了糖尿病筛查模型地准确度。
[0077]
在另一实施例中,如图4所示,一种基于肌肉力量的糖尿病筛查系统,包括:
[0078]
采集模块,用于采集体检者参数,所述参数包括:民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围、心率、最大握力和起坐次数;
[0079]
数据预处理模块,用于对采集的参数进行预处理;
[0080]
预测模块,用于将预处理后的参数输入预先训练好的多层感知器,输出得到体检者是否患有糖尿病的结果。
[0081]
其中,数据预处理模块,包括:
[0082]
第一预处理模块,用于采用连续型变量归一化方法对最大握力、起坐次数、bmi、腰围进行预处理;
[0083]
第二预处理模块,用于采用离散型变量独热编码对民族、性别、糖尿病家族史进行预处理;
[0084]
第三预处理模块,用于将收缩压、年龄、心率划分区间,映射为离散型变量,再用离散型变量独热编码进行预处理。
[0085]
本发明根据中国糖尿病风险评分,采集基础指标民族、性别、糖尿病家族史、收缩压、年龄、bmi、腰围这7个指标,再采集心率、最大握力、起坐次数这3个额外指标,并对这10个指标进行数据预处理;然后基于多层感知器构建糖尿病筛查模型的结构,将数据集划分为训练集和测试集,使用训练集的数据进行训练,得到糖尿病筛查模型;最后将新数据输入糖尿病筛查模型,得到预测结果,判断是否患有糖尿病。
[0086]
本发明所需的指标都可以使用非侵入式方法采集,使得糖尿病的筛查更为普适、经济、简便、易行;在中国糖尿病风险评分的基础上加入了心率、最大握力、起坐次数这三个反映体力活动情况和肌肉力量的指标,增加了模型对糖尿病筛查的准确度;采用多层感知器自动提取输入变量的特征,减少了对医学先验知识的需求。
[0087]
以上已以较佳实施例公布了本发明,然其并非用以限制本发明,凡采取等同替换或等效变换的方案所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1