一种阿尔兹海默症患者的脑电复杂度分析方法
1.本发明涉及生物电信号处理技术领域,具体指一种阿尔兹海默症患者的脑电复杂度分析方法。
背景技术:
2.在阿尔兹海默症(ad)引起的痴呆表现之前有临床前ad和轻度认知障碍(mci)两个阶段。而在临床前ad阶段中,患者没有表现出任何临床症状,但患者体内与ad相关的脑、血液和脑脊液等开始发生生理变化,这一阶段出现数年之后痴呆症才有可能表现出临床症状,在这个阶段检测ad的可能性将为治疗干预提供一个关键的机会,确的早期诊断还将有助于患者更长时间地保持独立性,并预防与精神疾病相关的症状,如抑郁症或精神病,从而降低与ad相关的个人和社会成本。此外,治疗ad症状的新药很可能在疾病的早期阶段,即在神经变性发生之前,其治疗的效果会更好。故相关的早期诊断ad技术在此背景下应运而生。
3.但直到今天,只有揭示了ad造成的结构性脑损伤特征,才有可能在患者死后做出明确的ad诊断。目前的诊断方法,例如神经学测试和医疗记录,该方法的准确率高达90%。同时,简易精神状态检查(mmse)是在实际的临床诊断中是最常用的认知能力测试工具,另外蒙特利尔认知评估(moca)和addenbrooke认知测验修订版也经常用于临床实践。神经学测试的其他例子有严重认知障碍量表、阿尔兹海默症评估认知量表、神经心理测试组合和严重认知障碍组合等。此外由于其他导致痴呆症的疾病,如血管性脑损伤、路易体疾病和帕金森病,在某些情况下也会出现与ad并存的情况,导致一些早期症状出现重叠,因此使用特定生物标志物的技术可以加强ad和这些疾病在早期阶段的鉴别诊断。
4.目前来说,预防是ad治疗研究中的主要目标。然而依靠神经学测试和医疗记录评估需要有经验的临床医生和漫长的治疗过程,这使得ad诊断耗时耗力,无法大规模推广和重现。为了应对这些缺点,在过去的几年里,关于ad生物标记物的使用、研究和开发有所增加,这些生物标志物在最近ad研究诊断标准中起着核心作用。相关研究中可将ad的生物标记分为三大类:a、t和n,其中前两类包括分别测量脑淀粉样变性和变态反应的生物标记物,例如淀粉样蛋白和tau示踪正电子发射断层扫描,以及acf142和p-tau的脑脊液浓度;n类包括两种疾病标记物,用于测量神经变性或神经损伤(如βt-tau、fdgpet和mri中的萎缩)。
5.研究发现,最常见的脑脊液生物标志物β
42
在ad患者中的值低于健康人。然而为了获取脑脊液样本,需要进行腰椎穿刺,这使得这项技术具有侵入性难以推广,从而阻碍了该项技术在日常临床实践中的应用。作为另一种选择,血液生物标记物,如血浆t-tau也在研究中,因为它们可以提供与脑脊液相似的信息,是一种侵入性更小、成本更高的技术。另外通过正电子发射计算机断层扫描、磁共振成像、计算机断层扫描等神经成像工具使临床医生能够在活体内研究ad引起的脑损伤范围。然而,一旦以当前这些神经成像技术的当前空间分辨率可以检测到与疾病相关的结构损伤时,此时的ad患者就已经很严重了,也就是说,此时的患者大脑的萎缩已经扩大了。此外,这些神经成像工具既昂贵又耗时,而且需要专家进行干预。此外,并不是所有的医院都能买得起mri和pet扫描仪,特别是在低收入和中等收
入国家或偏远地区,因此对患者来说既不舒服也不实用。因此综上所述,现有的脑脊液衍生生物标记物和神经成像技术是不切实际的,因为这些技术要么是有创的,要么是昂贵的。
6.虽然近几年国内已有通过检测阿尔兹海默症的脑电信号复杂度异常的相关方法去预测ad的疾病监测,例如通过多变量多尺度带权值排序熵去充分反应隐含于时间序列中的复杂度变化,但是其检测方法仍存在噪声对信号有无法避免的干扰等问题。
技术实现要素:
7.本发明根据现有技术的不足,提出一种阿尔兹海默症患者的脑电复杂度分析方法,可以用来在脑组织发生变化或行为症状出现之前评估ad进展引起的神经元退化。具有非侵入性、便携和更便宜等诸多优点。
8.为了解决上述技术问题,本发明的技术方案为:
9.一种阿尔兹海默症患者的脑电复杂度分析方法,包括如下步骤:
10.s1、采集受试者的脑电信号,所述受试者包括ad、mci和hoa三组;
11.s2、对采集的脑电信号进行预处理,通过独立分量分析法取出脑电信号的伪影,再对脑电信号进行带通滤波;
12.s3、对预处理后的脑电信号进行相关复杂度计算,分别通过lempel-ziv算法和模糊近似熵算法计算出相应的复杂度;
13.所述模糊近似熵算法计算复杂度的方法如下:
14.对于一个给定的n点时间序列{μ(i),i=1,2,...,n},m维向量的集合形成为xi=[μ(i),μ(i+1),...,μ(i+m-1)],i的范围从1到n-m+1;两个向量和之间的距离由下式定义,同时定义φm(r):
[0015][0016][0017]
则近似熵可定义为:
[0018][0019]
定义模糊近似熵,对于同一时间序列,{μ(i),i=1,2,...,n}通过以下方式形成一系列向量:
[0020][0021]
在给定r和n的情况下,两个向量之间的相似度由模糊函数确定:
[0022][0023]
与apen类似,将函数和φm定义为:
[0024]
[0025][0026]
最后,模糊近似熵fapen的估计值可以用以下公式表示:
[0027]
fapen(m,n,r,n)=φm(n,r)-φ
m+1
(n,r)
[0028]
其中嵌入维数m、数据长度n、容差r、和指数函数n;
[0029]
s4、对计算出的复杂度进行分析。
[0030]
作为优选,所述步骤s2-2中,带通滤波的具体方法如下:在全频段分析中,采用0.5-40hz带通滤波即得到全频段的被试者eeg信号;在多频段分析中,采用小波包算法分别提取eeg信号中的多个频段,δ频段(0.5-4hz),θ频段(4-8hz),α频段(8-13hz),β频段(13-30hz)。
[0031]
作为优选,所述步骤s3中,lempel-ziv算法计算复杂度的方法如下:
[0032]
设时间尺度为s,s取整数值且不超过时间序列长度,并将数据段拆分为1s的数据段;
[0033]
对eeg信号进行二值化处理,首先找出该脑电序列中信号的中间值m
*x
,之后使用这个中间值m
*x
与该脑电序列中的每个数据点进行大小比较判断,并且大于该中间值m
*x
取为1,小于中间值m
*x
取为0,便可得到一个二值化后的时间序列{s(i),i=1,2,...,n};
[0034]
假定s(s1,s2,...,sn)表示为一个以(0,1)数值的时间序列,在这个时间序列中s表示字母为si,数值仅为1和0,且该时间序列s的长度则为n,用subs(i,j)表示为时间序列s中的子字符串,表示为时间序列s中第i个字母和第j个字母之间的字符串组成,自然该字符串需要满足1≤i≤j≤n,另外用v(s)表示为时间序列s中的单词集合,该单词集和表示的是时间序列s中的子字符串出现的总集合,仿照s(s1,s2,...,sn)另外假定一个(0,1)时间序列q(q1,q2,...,qm),同时定义sqπ为时间序列s(s1,s2,...,sn)和q(q1,q2,...,qm)集合中去掉一个字符,即sqπ表示为sqπ=(s1,s2,...,sn,q1,q2,...,q
m-1
),同时v(s)定义可以得到,v(sqπ)表示为时间序列集合sqπ中不同子字符串的集合,定义c(n)为时间序列s的复杂度量,从而计算时间序列(s1,s2,...,sn)的复杂度;
[0035]
初始化为:c(n)=1、s=(s1)、q=(s1),则sqπ=(s1),假设如果q∈v(sqπ),那么时间序列q中的字符序列可以通过序列s复制得到,此时可以把要计算的时间序列的下一个字符连接到序列q,假设时,那么这时需要把时间序列q插入该字符,并将序列q级联到序列s中去,表示为s=sq,最后把序列q清空,这时候才把要计算的序列下一个字符连接到q中,此时时间序列s表示为s=(s1,s2),q=(s3),在计算中,每当时间序列q连接到时间序列s时,便需要执行一次c(n)加1操作,c(n)=c(n)+1,重复步骤直到序列q取到需要计算的时间序列s的最后一位;
[0036]
通过归一化处理c(n)。
[0037]
作为优选,所述归一化处理c(n)通的表达式如下:
[0038][0039]
lzc=c(n)/b(n)
[0040]
通过以上两个方程对得到的子串进行归一化处理,当n接近于∞时,b(n)表示为c
(n)的其中一个近似值,这里通过使用b(n)来对序列c(n)进行归一化操作,即可以获得一个与n完全无关的lempel-ziv复杂度lzc表达式。
[0041]
作为优选,所述步骤s4中的复杂度分析方法为lzc和模糊近似熵的特征分析。
[0042]
作为优选,所述lzc和模糊近似熵的特征分析方法如下:
[0043]
s4-1、在计算所有被试者三个组别的fapen和lzc数值时,测算出每个被试者每个通道的平均脑电复杂性,然后以取被试者所有通道的eeg信号的lzc和fapen的平均数值作为每个被试者的最终的lzc和fapen值;
[0044]
s4-2、对全频段以及四个频段下ad、mci和hoa三组受试者的脑电复杂度进行比对分析。
[0045]
作为优选,所述步骤s4-1中每个被试者每个通道的平均脑电复杂性的测算时,将所有的数据段拆分为1s的多个数据段,每个数据段作为一个通道去计算平均脑电复杂性。
[0046]
本发明具有以下的特点和有益效果:
[0047]
采用上述技术方案,证实全频段的复杂性特征可能不适合量化ad引起的脑电图变化,同时三组被试者在多频段的表现更加多元一些,且在delta、theta和alpha频段三组之间具有显著性差异。这表明多频段的复杂性特征可能更适合于量化ad引起的脑电图变化,这为未来利用脑电信号进行ad诊断提供更好的理论基础。
[0048]
同时,本发明不仅表明了基于脑电复杂度的测量为检测ad提供了一种潜在的有用方法,而且说明从eeg信号的多频段中提取复杂性度量是获得稳健生物标志物的重要一步。并且,提供了同时利用lempel-ziv和模糊近似熵两种复杂度测量方法,是一种高效且准确的阿尔兹海默症患者的脑电复杂度分析方法。
[0049]
数据结果表明,结合模糊近似熵(fapen)和lempel-ziv复杂度(lzc)两种不同非线性动力学方法量化阿尔兹海默症对被试者脑电复杂性影响,是一种高效且准确的阿尔兹海默症患者的脑电复杂度分析方法。并且从多频段中提取的delta、theta和alpha频段去作为复杂度度量的主要频段,从而只需要使用少量的脑电通道、数据量以及特定的频段,便可以实现良好的脑电复杂度的检测与分析,为检测ad提供了一种潜在的有用方法,表明从eeg信号的多频段中提取复杂性度量是获得稳健生物标志物的重要一步。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
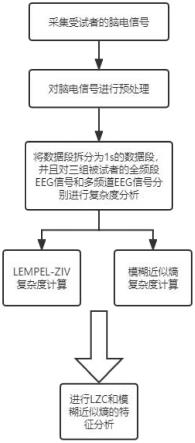
[0051]
图1为本发明实施例的方法流程图。
[0052]
图2为脑电信号中不同的伪影的时域分析图,其中
[0053]
(a)为脑电信号中眼动造成的干扰分量;
[0054]
(b)为脑电信号中肌肉造成的干扰分量;
[0055]
(c)为脑电信号中心电造成的干扰分量;
[0056]
(d)为脑电信号中工频电源造成的干扰分量。
[0057]
图3为复杂度分析的总体过程示意图。
[0058]
图4为lzc算法原理图。
具体实施方式
[0059]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0060]
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”等的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
[0061]
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以通过具体情况理解上述术语在本发明中的具体含义。
[0062]
本发明提供了一种阿尔兹海默症患者的脑电复杂度分析方法,如图1所示,包括如下步骤:
[0063]
s1、采集受试者的脑电信号,所述受试者包括ad、mci和hoa三组。
[0064]
具体的,招募被试者56名,其中ad患者(n=21,15名男性)和遗忘型mci患者(n=15,9名男性)以及年龄相匹配的认知正常老年人作为对照组(n=20,12名男性)。所选取的对照组被试者健康状况正常,每个被试者均无明显认知障碍,并且被试者没有证据表明他们有痴呆或其他神经心理障碍。
[0065]
在采集过程中患者被指示保持清醒和放松,记录每个被试者的静息态eeg信号。记录的总长度为5分钟,其中前10s为被试者熟悉环境的时间,所采集的数据不计入最后的数据分析中。当被试者出现意识不集中时,数据采集人员会提醒被试者,以提高注意力。根据本次研究的需要,我们在59个脑电通道中最后选择19通道的脑电信号,分别为:fp1、fp2、fz、f3、f4、f7、cz、c3、c4、f8、t7、t8、pz、p3、p4、p8、p7、o1和o2电极。这19个通道的脑电通道便可以在一定程度上代表了被试者的整体的静息态脑电表现。
[0066]
s2、对采集的脑电信号进行预处理,通过独立分量分析法取出脑电信号的伪影,再对脑电信号进行带通滤波。
[0067]
具体的,首先通过小波变换对原始eeg信号进行滤波消噪,然后通过基于emd和快速独立分量分析(fastica)相结合的emd-fastica方法对eeg信号进行眨眼、心电等生理伪影去除。
[0068]
本实施例中,以去除眨眼类型为例,首先将emd应用于受影响最大的通道(fp1、fp2通道),以提取眨眼伪影作为模板。然后,这个提取的眨眼模板将与其他受污染的eeg通道一起作为输入到fastica,以便将眨眼与其他通道分开。整个过程,如图2所示,分别对(a)眼
动、(b)肌肉、(c)心电、(d)工频电源所造成的干扰分量进行伪影去除。
[0069]
带通滤波的具体方法如下,如图3所示,现将获得的数据段拆分为1s的数据段,并且对ad、mci、hoa三组被试者的全频段eeg信号,以及多频段eeg信号的复杂性变化分别进行分析。采用0.5-40hz带通滤波即得到全频段的被试者eeg信号;在多频段分析中,采用小波包算法分别提取eeg信号中的多个频段,δ频段(0.5-4hz),θ频段(4-8hz),α频段(8-13hz),β频段(13-30hz)。
[0070]
s3、对预处理后的脑电信号进行相关复杂度计算,分别通过lempel-ziv算法和模糊近似熵算法计算出相应的复杂度。
[0071]
进一步的,如图4所示,lempel-ziv算法计算复杂度的方法如下:
[0072]
设时间尺度为s,s取整数值且不超过时间序列长度,并将数据段拆分为1s的数据段;
[0073]
对eeg信号进行二值化处理,首先找出该脑电序列中信号的中间值m
*x
,之后使用这个中间值m
*x
与该脑电序列中的每个数据点进行大小比较判断,并且大于该中间值m
*x
取为1,小于中间值m
*x
取为0,便可得到一个二值化后的时间序列{s(i),i=1,2,...,n};
[0074]
假定s(s1,s2,...,sn)表示为一个以(0,1)数值的时间序列,在这个时间序列中s表示字母为si,数值仅为1和0,且该时间序列s的长度则为n,用subs(i,j)表示为时间序列s中的子字符串,表示为时间序列s中第i个字母和第j个字母之间的字符串组成,自然该字符串需要满足1≤i≤j≤n,另外用v(s)表示为时间序列s中的单词集合,该单词集和表示的是时间序列s中的子字符串出现的总集合,仿照s(s1,s2,...,sn)另外假定一个(0,1)时间序列q(q1,q2,...,qm),同时定义sqπ为时间序列s(s1,s2,...,sn)和q(q1,q2,...,qm)集合中去掉一个字符,即sqπ表示为sqπ=(s1,s2,...,sn,q1,q2,...,q
m-1
),同时v(s)定义可以得到,v(sqπ)表示为时间序列集合sqπ中不同子字符串的集合,定义c(n)为时间序列s的复杂度量,从而计算时间序列(s1,s2,...,sn)的复杂度;
[0075]
初始化为:c(n)=1、s=(s1)、q=(s1),则sqπ=(s1),假设如果q∈v(sqπ),那么时间序列q中的字符序列可以通过序列s复制得到,此时可以把要计算的时间序列的下一个字符连接到序列q,假设时,那么这时需要把时间序列q插入该字符,并将序列q级联到序列s中去,表示为s=sq,最后把序列q清空,这时候才把要计算的序列下一个字符连接到q中,此时时间序列s表示为s=(s1,s2),q=(s3),在计算中,每当时间序列q连接到时间序列s时,便需要执行一次c(n)加1操作,c(n)=c(n)+1,重复步骤直到序列q取到需要计算的时间序列s的最后一位;
[0076]
通过归一化处理c(n),所述归一化处理c(n)通的表达式如下:
[0077][0078]
lzc=c(n)/b(n)
[0079]
通过以上两个方程对得到的子串进行归一化处理,当n接近于∞时,b(n)表示为c(n)的其中一个近似值,这里通过使用b(n)来对序列c(n)进行归一化操作,即可以获得一个与n完全无关的lempel-ziv复杂度lzc表达式。
[0080]
通过以上的步骤,我们就可以把(s1,s2,...,sn)分为c(n)不同的子串,即表示为序列(s1,s2,...,sn)的复杂度。
[0081]
进一步的,所述模糊近似熵算法计算复杂度的方法如下:
[0082]
对于一个给定的n点时间序列{μ(i),i=1,2,...,n},m维向量的集合形成为xi=[μ(i),μ(i+1),...,μ(i+m-1)],i的范围从1到n-m+1;两个向量和之间的距离由下式定义,同时定义φm(r):
[0083][0084][0085]
则近似熵可定义为:
[0086][0087]
定义模糊近似熵,对于同一时间序列,{μ(i),i=1,2,...,n}通过以下方式形成一系列向量:
[0088][0089]
在给定r和n的情况下,两个向量之间的相似度由模糊函数确定:
[0090][0091]
与apen类似,将函数和φm定义为:
[0092][0093][0094]
最后,模糊近似熵fapen的估计值可以用以下公式表示:
[0095]
fapen(m,n,r,n)=φm(n,r)-φ
m+1
(n,r)
[0096]
确定参数,进行计算。在计算熵之前需要确定四个参数,即嵌入维数m、数据长度n、容差r、和指数函数n的中的梯度,与参数r相比,m和n对熵值计算的影响都相对较小,因此设置为固定值。本实施例中,将参数m设为2。这里的相似性度量的边界宽度用公差r表示,小的r值会受到噪声的显著影响,而大的r值会导致有用信息的丢失,因此0.1≤r≤0.25在许多研究中被推荐。梯度n是fapen中的一个新参数,作为向量之间相似度的权值。当n趋于无穷大时,指数函数μ(d,r,n)=exp(-(d/r)n)退化为heaviside函数,其中靠近边界点的信息丢失严重。因此,n应该是小的正整数,如2和3。
[0097]
s4、对计算出的复杂度进行分析为lzc和模糊近似熵的特征分析。
[0098]
具体的,所述lzc和模糊近似熵的特征分析方法如下:
[0099]
s4-1、在计算所有被试者不同组别(ad、mci、hoa)的fapen和lzc数值时,测算出每个被试者每个通道的平均脑电复杂性(1s),然后以取被试者所有通道的eeg信号的lzc和fapen的平均数值作为每个被试者的最终的lzc和fapen值,每个被试者每个通道的平均脑电复杂性的测算时,将所有的数据段拆分为1s的多个数据段,每个数据段作为一个通道去计算平均脑电复杂性。
[0100]
s4-2、对全频段以及四个频段下的脑电复杂度进行分析。
[0101]
在全频段eeg信号的复杂性分析中发现,ad患者在特定脑电频段和特定脑电通道上的复杂性指标明显低于其他两组的被试者。虽然ad组、mci组的复杂性相比于hoa组较低,但三组被试者在绝大多脑电通道上都不具有显著性差异。然后在多频段的复杂性分析中发现,ad组、mci组和hoa组被试者在四个脑电图频段的lzc生物标志物之间的差异性比全频段eeg信号的差异更大,特别是在delta、theta和alpha频段,这似乎表明使用从频段派生的生物标志物在检测ad方面比使用全频段eeg信号更好。因为ad患者和正常被试者从某个频段获得的复杂性度量与从整个信号得出的复杂性度量相比有更大的差异,这是一个好的生物标记物的一个理想属性。这意味着可能只使用少量的脑电通道和特定的频带,便可以提供检测ad的最佳生物标志物。在可用通道数量和数据量有限的情况下,可以利用这一点来实现良好的性能。
[0102]
综上,相对于其他复杂度分析方法,本方法提出的结合模糊近似熵(fapen)和lempel-ziv复杂度(lzc)两种不同非线性动力学方法量化阿尔兹海默症对被试者脑电复杂性影响,并从多频段中提取的delta、theta和alpha频段去作为复杂度度量的主要频段,从而只需要使用少量的脑电通道、数据量以及特定的频段,便可以实现良好的脑电复杂度的检测与分析,为检测ad提供了一种潜在的有用方法,表明从eeg信号的多频段中提取复杂性度量是获得稳健生物标志物的重要一步。
[0103]
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式包括部件进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1