基于AE和Transformer的运动想象脑电信号分类方法
基于ae和transformer的运动想象脑电信号分类方法
技术领域
1.本发明涉及脑电信号分类识别技术,具体公开基于ae和transformer的运动想象脑电信号分类方法,属于计算、推算或计数的技术领域。
背景技术:
2.2013年,美国政府公布了“脑研究计划”,该计划促进了脑神经科学的发展,自此脑-机接口(brain-computer interface,bci)进入研究员的视野,并在21世纪初达到空前的研究发展。bci系统使用特殊的脑电信号(electroencephalogram,eeg)采集设备,进而通过技术系统分类识别出eeg信号中所带有的人类思考特征,从而派生出对应的输出信息,实现人脑与外部控制设备的“对话”。
3.目前,bci研究主要分为几大领域,分别是eeg信号的采集、预处理、特征提取、特征识别与分类,其中,最为核心的是预处理、特征提取、特征识别与分类。eeg信号预处理需要克服采集eeg信号过程中不可避免的噪声,主要包括人体肌肉产生的肌电信号以及因为眼球的转动产生的伪迹。常见的eeg信号预处理技术为频率滤波或者阈值法。采用频率滤波进行eeg信号预处理时,能够有效地去除带内噪声,但是可能会直接滤除部分频带外的有用信号分量,丢失部分特征信息。采用阈值法进行eeg信号预处理时,未达到阈值的eeg信号均会保留,从而保存较为完整的特征信息,但是由于生物信号的非平稳性,很大可能会留下藏在生物信号里面的伪迹。
4.对运动想象eeg信号进行特征提取能有效捕获具有较为显著特征的向量矩阵,为提升分类准确率打下基础。常用的特征提取方法主要有:功率谱分析法(power spectral density,psd)、自适应自回归法(adaptive auto-regressive,aar)、独立分量分析(independent component analysis,ica)、共空间模型法(common spatial pattern,csp)。psd分析法直接将时域的eeg信号转换至频域中,从而直观地看到eeg信号的能量变化,但是该转换会损失eeg信号的时域信息,较为片面。aar模型法大多作用于平稳信号模型,虽然其计算过程较为简单,但是eeg信号的非平稳性使得aar技术也不是绝佳的选择。ica技术的核心是针对具有相互独立的信号频段提取独立分量,该技术用于eeg信号上,一般效果不甚理想。csp技术主要是对数据矩阵的协方差矩阵进行处理,找到使两个矩阵在空间中的方差最大化的方向,以分辨不同类的脑电特征,因此不需要对被试者脑电信号选择特定的频带进行特征提取,但是局限是能够分辨单一频段的脑电特征。
5.由于eeg信号数据一般较为庞大,因此eeg信号经过特征提取后得到的特征矩阵的维度较高,增加了后续eeg信号特征分类识别的难度,降低了系统的运行效率。所以一般在eeg信号特征分类之前会对数据进行降维处理。常见的代表性降维技术是主成分分析技术(principal component analysis,pca)和线性判别分析技术(latent dirichlet allocation,lda),然而这两大技术一般是线性的降维技术,用于非线性非平稳eeg信号的特征矩阵的降维处理,降维效果会大打折扣。随着人们对信息需求量的增加,非线性降维技术逐渐成为主流技术。自编码器利用了编码解码的原理,将高维度的数据用低维的中间隐
藏层近似表示,且保留了高维数据的特征信息,降维效果显著。
6.研究bci的最终目标是对eeg信号的特征矩阵进行分类识别,从而达到对人类脑信息的推测,为身体不便但脑未受损的人群带来福音。目前,eeg信号的分类技术主要包括线性回归、线性判别法、k-近邻法则、支持向量机(support vector machines,svm)等,其中,使用比较多的分类器是svm、knn,一般能得到较为满意的分类结果。
7.近几年,深度学习框架逐渐在bci系统领域中占有一席之地,如卷积神经网络、长短时记忆网络、生成对抗网络等方法,但现有的基于神经网络的深度学习方法大多只考虑了脑电信号中的局部特征而忽略了全局信息,于2018年提出的transformer能捕获全局信息,transformer模型,是一种强大的自然语言处理模型。transformer模型的本质是一种注意力机制模型且为单个模块,较为完美地考虑到全局特征,计算复杂度低于其它神经网络,且多层结构能够同时进行计算,加快计算效率。一种transformer引导卷积神经网络的脑电信号分类方法,通过神经网络与transformer交替的结构,弥补基于深度学习的神经网络忽略全局信息以及transformer不能很好利用脑电信号中局部特征的缺陷,虽然能够提升脑电信号分类的准确率,但分类的准确性依赖于卷积神经网络提取局部特征的准确性,另一方面,神经网络与transformer交替的计算过程复杂,影响脑电信号识别效率,该脑电信号分类的准确率及效率均有待提高。
8.综上,本发明旨在提出一种基于ae和transformer的运动想象脑电信号分类方法,以克服现有脑电信号分类技术的缺陷。
技术实现要素:
9.本发明的目的是针对背景技术的不足,提供基于ae和transformer的运动想象脑电信号分类方法,将transformer模块应用到eeg信号分类识别,采用ae自编码器对提取的特征信号进行降维处理,提升eeg信号分类识别的效率,利用自注意力机制提取特征矩阵内部的关联性,提升分类识别的准确率,实现通过简单的transformer分类器提升脑电信号分类准确率和效率的发明目的,解决现有基于transformer的脑电信号识别分类的准确率和效率有待提高的技术问题。
10.本发明为实现上述发明目的采用如下技术方案:
11.一种将transformer技术应用到运动想象eeg信号特征分类识别领域中,辅以ae自编码器进行降维的技术方案,具体包含以下顺序步骤:
12.fbcsp(filter bank common spatial pattern,滤波器组共空间模式)技术通过使用空间滤波器将信号分频段后进行分析,保证了分布在不同频段的重要特征信息都能被提取出来,其包括四个阶段:频率滤波、空间滤波、特征选择和特征分类。假设原始运动想象eeg信号在经过信号预处理后得到的数据频率范围是f1~f
n+1
hz,则通过频率滤波将训练和测试的eeg信号分成f1~f
2 f2~f
3 f3~f
4 ...... fn~f
n+1
共n个频段,随后通过空间滤波对每个频段的信号进行csp特征提取,提取相关特征矩阵,便于后续分类。
13.由于eeg信号的输入样本数据量较大,影响transformer模型的计算速率和分类准确率,所以引入ae自编码器对特征数据进行降维处理,从而降低数据的维度或数据量。ae自编码器本质是一种三层神经网络结构,整个编码器包括输入层、隐藏层和输出层三层,其中,输入层作为输入,经过编码过程输入到隐藏层中,然后经过解码过程传输到输出层中,
其中隐藏层包含原始输入的重要特征。该编码器的本质类似于pca,通过改变隐藏层中的权重参数,使得整个系统的输入与输出相同,从而实现自适应无监督的特征提取。
14.假设经过fbcsp特征提取后的特征矩阵数据为x∈[0,1]n,在编码阶段通过编码函数h=encoder(x)(h∈[0,1]m),就可以得到隐藏层h的输入。编码函数的定义如下:
[0015]
h=encoder(x)=g(wh·
x+b)
ꢀꢀ
(1)
[0016]
其中,wh∈rm×n表示的是连接输入层和隐藏层的权重矩阵,g(
·
)是激活函数,b∈[0,1]m是偏置向量,m为隐藏层输入节点的数目。
[0017]
在解码阶段,为了得到输出层y,将隐藏层h的输出作为解码函数y=decoder(h)的输入,解码函数的定义如下:
[0018]
y=decoder(h)=g(w'h·
x+b')
ꢀꢀ
(2)
[0019]
其中,连接隐藏层和输出层的权重矩阵为w'h∈rn×m,偏置向量为b'∈[0,1]n。
[0020]
在模型的训练过程中,为使得每个输入信号与输出信号相同,则模型的目标函数如下:
[0021][0022]
其中,x
(j)
为输入ae自编码器的第j个特征向量,即,特征矩阵x∈[0,1]n的第j维向量,y
(j)
为第j个特征向量经ae自编码器后输出的特征向量。根据式(3)调整隐藏层的权重参数,输入隐藏层的特征向量满足式(3)时记为c,c即为x∈[0,1]n经过ae自编码器降维后的特征向量矩阵。
[0023]
假设经过ae自编码器降维后的特征向量矩阵为在经过维度转换后并利用正弦和余弦函数添加表征每个频段特征信号时序信息的位置编码,获得多头自注意力层的输入矩阵:
[0024][0025]
其中,每一行是一维特征矩阵,dinpput表示transformer输入特征矩阵的行数,dinpput《n,d
model
是transformer输出特征矩阵的列数。将输入矩阵x分别与预设的权重矩阵相乘得到查询向量q、键向量k和值向量v,有:
[0026][0027]
其中,权重矩阵wq、wk和wv均是d
model
×dmodel
的线性矩阵。此时,q、k、v本质仍是同一个矩阵,维数均是d
input
×dmodel
。设h是多头自注意力层的头数,将q、k、v分别投影h次,每次投影采用不同的权重矩阵,设第i次投影的权重矩阵为:
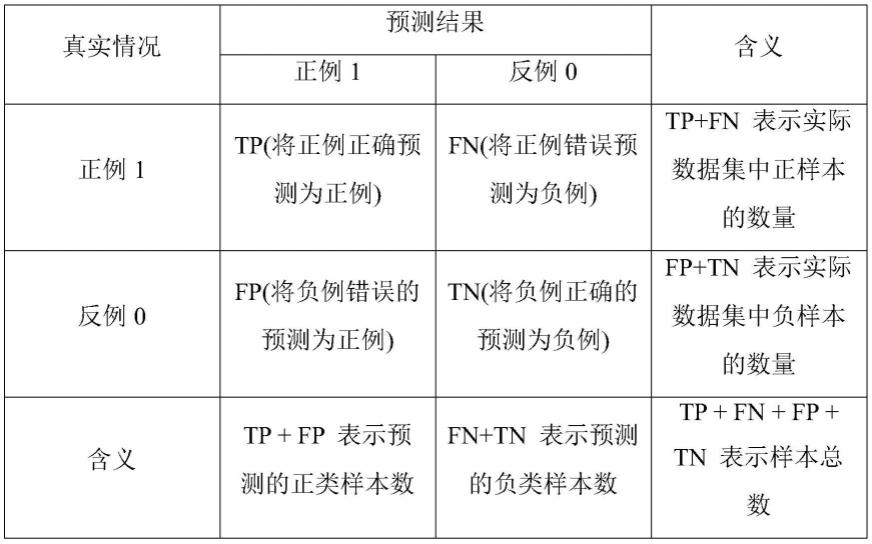
[0028][0029]dq
=dk=dv=d
model
/h
ꢀꢀ
(7)
[0030]
则第i次投影形成的一组查询向量qi、键向量ki和值向量vi为:
[0031][0032]
基于多头自注意力层对q、k、v进行投影的本质是将向量矩阵投影到不同的表示子空间。多头自注意力层的具体公式如下:
[0033][0034]
headi=attention(qi,ki,vi)
ꢀꢀ
(10)
[0035]
multihead(q,k,v)=concat(head1,...,headh)woꢀꢀ
(11)
[0036]
其中:softmax(
·
)表示softmax映射,concat是连接函数,为联合连接多头自注意力层的权重矩阵,hdv=d
model
。
[0037]
对于权重矩阵w
iq
、w
ik
、w
iv
和wo,内部参数是可以学习训练的,它经随机初始化后在反向传播或者反馈校验的时候不断更新修正。对于权重矩阵的参数修正,其修正思想类似于神经网络反馈修正的过程。首先确定网络的损失函数loss,并设置网络学习率η,则新的权重矩阵为:
[0038][0039]
在权重矩阵修正的过程中,损失函数loss的选取一般是均方损失或者是交叉熵损失,且对其求偏导并更新权重参数的过程常会利用优化器,如adam器和sgd器,从而进行反向修正。
[0040]
本发明采用上述技术方案,具有以下有益效果:
[0041]
(1)本发明将transformer技术应用到运动想象eeg信号分类识别中,打破了基于网络的深度学习运用到eeg领域中只能捕捉局部信号特征的局限,深入考虑了全局信号特征的影响,通过嵌入时序信息定位输入transformer分类器的每个特征数据的时序信息,以便充分考虑各频段特征向量时序信息对分类结果的影响;同时针对eeg信号的数据量大、信号维度高的问题,采用了ae自编码器进行数据降维处理,加快了系统运行的效率,提升了运动想象eeg信号分类的准确率。
[0042]
(2)本发明在分类识别过程中,以ae自编码器输入和输出误差最小时对应的编码矩阵为降维后的特征矩阵,基于transformer技术内部的多头自注意力层的特性,并行地计算将为后的特征矩阵的内部关联性,提升了运动想象eeg信号分类的准确率,同时多个编码器与译码器并行计算,提升网络的学习效率。
附图说明
[0043]
图1(a)、图1(b)为本发明实施例中eeg电极安装位置的示意图和实验范式图。
[0044]
图2为eeg信号分类识别的流程图。
[0045]
图3为采用fbcsp技术进行eeg信号特征提取的系统框架图。
[0046]
图4为knn、lda+knn、transformer、ae+transformer平均准确率的对比图。
[0047]
图5为knn、lda+knn、transformer、ae+transformer系统kappa系数的对比图。
[0048]
图6(a)至图6(d)为knn、lda+knn、transformer、ae+transformer系统的roc曲线
图。
具体实施方式
[0049]
下面结合附图对发明的技术方案进行详细说明。
[0050]
本发明将应用到运动想象eeg信号二分类的场景中,以bci竞赛2003数据ⅲ作为代表进行实施。10-20国际标准导联系统的eeg电极位置和bci竞赛2003数据ⅲ的实验范式过程图如图1所示。
[0051]
该数据集由奥地利graz科技大学bci实验中心提供,该数据集的受试者为一名25岁的正常女性,坐在有扶手的休闲椅上,通过观察正前方屏幕上左右方向的箭头指示来执行相应的左右手运动想象任务。该数据集由7组实验组成,每组实验进行40组试验,且7组实验均在同一天进行,中间间隔几分钟。整个数据集给出了280次试验,其中用于训练的有140组数据,用于测试的有140组数据,且各含有70组左手运动想象和右手运动想象。每次试验的整体时间是9s,具体试验内容如下:在试验开始的0-2s时间内,受试者平静且放松地坐于休闲椅上,并保持静息状态。在t=2s时,开始出现蜂鸣声这个听觉刺激且声音由低到高,代表试验正式开始,同时受试者正前方的屏幕上开始出现十字“+”符号,整个事件时间持续为1s。在t=3s时,受试者正前方的屏幕上随机出现向左或向右的指向箭头,且左右提示的顺序随机,同时要求受试者立即进行相应的左右手运动想象任务,直至9s试验结束。实验从10-20国际标准导联系统的c3、cz、c4三个采样通道采集脑电数据,其采样频率是128hz,并使用ag/agcl电极进行记录。数据集中的数据在保存前已通过带宽区间为[0.5hz,30hz]的带通滤波器进行滤波处理。
[0052]
具体实施的运动想象eeg信号分类识别的系统流程如图2所示。
[0053]
在运动想象eeg信号中,ers/erd现象主要发生在8-50hz频段范围内,因此可以让eeg信号通过通带为8-50hz的带通滤波器,同时还滤除了低频率的眼电信号和工频信号。由数据集的实验范式可知,t=3-9s为运动想象任务时间,t=3-3.5s为大脑反映时间,t=7-9为运动想象结束时间,所以对训练样本和测试样本中的所有数据进行8-50hz带通滤波后,截取出特征比较明显的3.5-7s时间段内的eeg信号数据作为新的训练和测试样本。
[0054]
(1)针对该数据集,fbcsp技术的具体实施如下:
[0055]
在特征提取阶段,采用fbcsp技术,使用八阶巴特沃斯滤波器将预处理后的eeg信号分段。将运动想象在8-48hz频段上的信号分成8-12hz、12-16hz、16-20hz、20-24hz、24-28hz、28-32hz、32-36hz、36-40hz、40-44hz和44-48hz十个频段,再对每个小频段的信号进行csp特征提取,最后得到特征矩阵,便于后续特征分类识别。fbcsp技术特征提取具体实施如图3所示。
[0056]
(2)ae自编码器进行降维的具体实施如下:
[0057]
在特征分类过程中,由于特征向量矩阵维度较高,需要捕捉输入数据最显著的特征,从而实现压缩数据,降低数据量,所以引入ae自编码器。在ae自编码器中,一些参数设置如下:在自编码器的降维阶段,将特征矩阵经过512维、256维,最后将数据压缩降至128维度,整个过程完成从输入层到隐藏层的变换。随后解码器利用较低维度的数据重构输入数据,将隐藏层的数据按照上述的维度参数逆向升维,使输出层结果与输入层结果相同,则可以说明隐藏层是输入层的128维低维矩阵,将其作为transformer网络的输入。
[0058]
(3)transformer模块进行特征分类识别的具体实施如下:
[0059]
将ae编码器降维后的特征向量矩阵送入分类器transformer模块中,并使用adam优化器,动态调整参数的学习率,使得参数趋于平稳,最后得到分类结果。在transformer模块的系统中,一些参数设置如下:整个发明使用torch框架,使用学习率为e-3
的adam优化器,实验epoch设置为200,丢弃率dropout设置为0.25,权重衰减系数设置为2.5e-2
。经过位置编码后的特征矩阵其中d
input
设置为6,d
model
设置为512。该特征矩阵与权重矩阵wq、wk和wv相乘得到查询向量q,键向量k和值向量v。wq、wk和wv均是512
×
512的线性矩阵。根据式(5)可以得到q、k、v,维数均是6
×
512。
[0060]
将q、k、v分别投影h次,h设置为8次。根据式(6)可以得到第i次投影的权重矩阵为w
iq
、w
ik
和w
iv
,三者均是512
×
64的矩阵。根据式(7)可以得到dq=dk=dv=64。根据式(8)可以得到第i次形成的一组查询向量qi、键向量ki和值向量vi,其维数是6
×
64。
[0061]
根据多头自注意力层的公式(9)、(10)和(11)可以得到最后的输出矩阵z=multihead(q,k,v),其维数是6
×
512。
[0062]
在实施的过程中,权重矩阵w
iq
、w
ik
、w
iv
和wo的内部参数是可以学习训练的。它经随机初始化后在反向传播或者反馈校验的时候不断更新修正。对于权重矩阵的参数修正,其修正思想类似于神经网络反馈修正的过程。首先确定网络的损失函数loss,并设置网络学习率η,则新的权重矩阵为:
[0063][0064]
在权重矩阵修正的过程中,损失函数loss的选取是联合均方和交叉熵整体作为损失函数,不断对权值进行修正。在对loss求偏导并更新权重参数的过程利用了优化器adam器,从而进行反向修正。利用损失函数计算每次迭代的前向计算结果和真实值的差距,并利用损失函数的倒数,沿着梯度最小的方向反向传播,修正前向计算的权重值。
[0065]
最后在transformer的解码阶段,特征向量矩阵采用了两个全连接层,将128维数据经过64维降至二维数据,通过含有两层全连接层和一个激活函数的前馈神经网络送入含有softmax函数的输出层,使得网络输出包含每类概率在内的二维输出矩阵,表示eeg信号预测为每个类的概率。
[0066]
本发明同时将特征向量矩阵加入lda+knn系统,比较两种系统的分类结果。
[0067]
(4)最终实施例性能分析:
[0068]
本发明使用以下两个评估标准。首先介绍模型评估的一些基本概念,即表1混淆矩阵所示:
[0069]
表1混淆矩阵
[0070][0071]
根据混淆矩阵中的定义,可以得到一种性能评估标准——分类准确率的定义。分类准确率本质是由识别正确的脑电数据样本数目与脑电数据总样本数目的比值,可以表示为:
[0072][0073]
于是,定义错误率err=1-acc,当每一类的样数目相同时,机会水平为acc0=1/n,其中,n表示运动想象任务的类别数目。,在本发明中,由于数据集是二分类,所以n的值为2,从而acc0=0.5。
[0074]
另外一种有用的性能评估方法是kappa系数,其数学表达式如下:
[0075][0076]
kappa系数的值域是[-1,1]。根据上式可知,与具体的每类样本个数和类别无关。若k=0认为是acc=acc0,即表示最后的结果对于每个样本分类的几率都是0.5。若k=1意味着是理想状态,每个样本的最后预测均是正确的。
[0077]
roc的全称是receiver operating characteristic曲线,也是二分类的分类器性能优劣的方法之一,它包含两个重要的公式如下:
[0078][0079]
系统实验一共有两个输入,其一为数据集中真实的样本,另一个为通过系统输出的每个样本判为正类的概率。将概率由大至小排序,并设为阈值,大于该阈值则预测样本为正类,反之小于该阈值则预测样本为负类。计算每个样本的tpr值和fpr值,并绘制曲线。在roc曲线图中,每个坐标点的横坐标是计算过的对应的fpr值,纵坐标是对应点计算后的tpr值。横坐标fpr越大,则表示预测正类中实际负类越多;纵坐标tpr越大,则表示预测正类中实际正类越多。
[0080]
auc作为衡量优劣的标准之一,其实质是roc曲线下的面积,其值域为[0,1]。当auc的值越来越靠近1时,roc曲线的整个趋势也是越来越上凸,即越来越靠近点(0,1)。
[0081]
图4给出了对bci竞赛2003数据ⅲ的eeg信号进行预处理和fbcsp特征提取以后,knn、lda+knn、transformer和ae+transformer四种不同技术系统的分类准确率图。由图4可以看出transformer模型系统得到的分类准确率为89.36%,比同等条件下的knn技术提高了2.58%,可见transformer模型整体结果优于knn技术。同时,由于transformer模块内部结构复杂度较高,所以提前使用ae自编码器对经过fbcsp技术的特征向量进行降维处理,整个ae+transformer系统提高了1.94%的分类准确率,说明了降维方法也能提高系统的分类准确率,从而优化整个系统。
[0082]
图5给出了对bci竞赛2003数据ⅲ的eeg信号进行预处理和fbcsp特征提取以后,knn、lda+knn、transformer和ae+transformer四种不同技术系统的kappa系数图表。由图5可以看出transformer模型系统得到的kappa系数为0.7871,比同等条件下的knn技术提高了0.0514,辅证了transformer模型整体结果优于knn技术的结论。同时,为了减少特征向量矩阵的数据量,采用ae自编码器对经过fbcsp技术的特征向量进行降维处理,使得整个ae+transformer系统的kappa系数提升至0.8298,同样也证明了降维方法也能提高系统的分类准确率,从而优化整个系统。
[0083]
图6给出了对bci竞赛2003数据ⅲ的eeg信号进行预处理和fbcsp特征提取以后,knn、lda+knn、transformer和ae+transformer四种不同技术系统的roc曲线图。从roc曲线可以看出,lda+knn系统得到的auc值为0.93,比未经过降维处理的knn系统提高了0.01;同时ae+transformer系统得到的auc值为0.96,比未经过降维处理的transformer系统提高了0.02;并且transformer系统比knn系统整体提升了0.02-0.03,auc值越大说明分类器越好。再从整个roc曲线趋势来看,从knn系统至ae+transformer模型,曲线越来越靠近坐标轴的左上方,辅助说明ae+transformer系统能够提高分类效果,可以进一步应用到其他类型的运动想象脑电信号分类中。
[0084]
(5)结论:
[0085]
提出了一种基于深度学习自注意力机制的运动想象eeg信号分类识别的实施方案,提升了二分类的分类准确率。所提的方案是将transformer技术应用到eeg领域中,并利用ae自编码器进行降维,该方案相较于现有的技术,如lda技术降维加上knn分类的组合,无论是准确率acc、kappa系数还是roc曲线,都能够说明ae+transformer技术的先进性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1