一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读方法与流程
1.本发明涉及一种深度学习方法,具体的,是涉及一种基于最大最小熵的半监督领域自适应算法的产前胎儿监护智能判读方法,该方法用于对多中心产前胎儿监护数据进行智能分类判断。
背景技术:
2.胎心宫缩监护图(ctg)是胎儿产前健康监测的重要工具,可用于确定胎儿是否缺氧、确定是否需要对孕产妇通过剖腹产进行分娩。为避免产科医生判读胎心宫缩图(ctg) 的主观性,国内外的众多学者纷纷开始使用机器学习算法对产前胎儿监护智能分类判别进行研究。
3.然而,目前大多数研究针对单中心数据集训练得到的智能判读模型,在其他胎心宫缩监护图(ctg)数据集上泛化性能较差,因此基于机器学习的智能产前胎心监护在现实应用中效果并不理想。
4.同时,单中心研究每次构建模型时都需针对该中心收集大量标记样本,据研究表明,对样本进行标注所需花费时间是获取样本数据的10倍以上。并且,为保证判读的准确性,确定数据标签通常需要多位领域内专家多次标注,只有多位专家判读一致的样本才纳入建模的数据集。这使得构建单中心ctg数据集的人力代价与时间代价极高。
5.基于此,多中心的胎儿监护图(ctg)临床研究显得尤为重要。随着医疗设备和数据处理技术的发展,多中心胎儿监护图(ctg)临床研究广泛开展。大多数医疗机构拥有少量的标记样本和大量未标记样本,不足以构建高性能单中心智能判读模型。而半监督领域自适应算法,基于源域的大量标记样本,有效利用上述目标域已标注数据和未标注数据,构建智能分类判读模型,能够在新的胎儿监护图(ctg)数据集上获得较好的泛化性能。
6.总的来说,目前国内外使用的单中心产前胎儿监护判读模型泛化性能较差,构建所需的人力成本与时间成本较高,不适合多中心临床ctg数据。因此,如何利用目标域少量已标注数据和大量未标注数据,构建多中心胎心监护智能判读模型,提高不同ctg数据集中的泛化性能,成为本领域亟待解决的技术难题。
技术实现要素:
7.为了解决上述现有技术所存在的缺陷,本发明提供一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读方法。
8.本发明采用如下技术方案:一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读方法,该方法包括如下步骤:s1:获取包含胎心率信号和宫缩信号的原始ctg信号数据;s2:对所述胎心率信号和宫缩信号进行数据预处理;
s3:将所述信号数据集进行分段,实现信号的数据增强,同时截取等长信号,得到信号长度均为d的胎心率信号和宫缩信号,构建待分类的数据集;s4:将所述待分类的数据集输入已预先训练得到的面向多中心产前胎心监护信号的智能判读模型进行分类判别,所述产前胎儿监护智能判读模型包括特征提取器和分类器;将所述信号长度均为d的胎心率信号和宫缩信号输入特征提取器神经网络结构,经l2归一化处理之后得到输出向量;将所述的特征提取器输出的向量、k维权重向量w和温度系数t输入到分类器,输出向量;将所述的分类器输出向量输入到softmax层,得到k维向量,表示模型判别样本属于每个类别的概率p;对所述样本为正常类和样本为非正常类的概率分别设置对应的类别标签;对比所述样本为正常类和样本为非正常类的概率,选取较大概率所对应的类别标签作为分类判别结果。
9.优选的,所述s2步骤的预处理包括分别对胎心率信号和宫缩信号进行插值或删除处理。
10.优选的,所述s2步骤的预处理还包括对经插值或删除处理的胎心率信号进行标准化处理。
11.优选的,所述标准化处理包括计算胎心率信号的基线值,并使用经插值或删除处理的胎心率信号减去基线值,得到标准胎心率信号。
12.优选的,所述s3步骤的分段处理包括将经预处理的胎心率信号和宫缩信号进行同步滑动窗口分段,得到信号长度不少于p的胎心率信号和宫缩信号片段。
13.优选的,所述s4步骤的特征提取器为googlenet神经网络结构。
14.本发明具有如下有益效果:第一,本发明提供的产前胎儿监护智能判读模型,显著提高产前胎儿监护智能判读模型的泛化性能,在新的胎心宫缩图(ctg)数据集上也有较好的分类性能,更加适合医疗大数据背景下的多中心产前胎儿监护数据。
15.第二,本发明提供的面向多中心产前胎儿监护数据的智能判读模型,充分利用源域和目标域的标记数据和未标记数据,对目标域已标注样本数量要求较小,同时保证了模型在目标域上较高的泛化性能。相比传统的单中心产前胎心监护智能判读模型,需要的标注样本数量更少,减少了智能判读模型构建过程中的标注代价。
16.第三,本发明不仅根据胎心率信号和宫缩信号的数据特点进行预处理,而且对预处理后的标准胎心率信号和宫缩信号进行滑动窗口分段处理,实现了数据增强,使得信号长度得到统一,进一步提高智能判读模型的分类判别性能。
附图说明
17.图1是本发明的面向多中心产前胎儿监护信号的智能判读方法的算法流程示意图。具体实施方法
18.为了使本发明的发明目的、技术方案以及有益效果更清楚,以下将结合说明书的附图以及具体实施例,对本发明进行进一步的说明。
19.本实施例采用两个不同的胎心率宫缩(ctg)信号数据集,分别作为源域数据和目标域数据。经过三轮产科医师根据第9版《妇产科学》教材的胎儿监护指南对胎心率宫缩信号与胎儿健康状态进行判读,判读结果一致则纳入研究。其中源域胎儿监护图(ctg)信号为医院中央站数据,2016年至2018年使用多床位无线探头胎监工作站srf618a pro采集,共1.6355万例,胎儿状态为正常类的有1.1998万例,非正常类的有0.4357万例。目标域胎儿监护图(ctg)信号为居家移动端数据,2018年至2020年使用远程胎儿监护仪srf618b1 采集,共3351例数据,胎儿状态为正常类的有2886例,非正常类的有465例。
20.实施例一本发明提供的一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读方法,该方法包括如下步骤:s1:获取包含胎心率信号和宫缩信号的原始ctg信号数据;s2:对所述胎心率信号和宫缩信号进行数据预处理;所述预处理包括分别对胎心率信号和宫缩信号进行插值或删除处理。所述预处理还包括对经插值或删除处理的胎心率信号进行标准化处理;所述标准化处理包括计算胎心率信号的基线值,并使用经插值或删除处理的胎心率信号减去基线值,得到标准胎心率信号;s3:将所述信号数据集进行分段,实现信号的数据增强,同时截取等长信号,得到信号长度均为d的胎心率信号和宫缩信号,构建待分类的数据集;其中,d为1125;所述分段处理包括将经过预处理的胎心率信号和宫缩信号进行同步滑动窗口分段。s4:将所述待分类的数据集输入已预先训练得到的面向多中心产前胎心监护信号的智能判读模型进行分类判别,参照图1所示,所述产前胎儿监护智能判读模型包括特征提取器和分类器;将所述信号长度均为d的胎心率信号和宫缩信号输入googlenet作为特征提取器的神经网络结构,经l2归一化处理之后得到输出向量;将所述的特征提取器输出的向量、k维权重向量w和温度系数t输入到分类器,输出向量;其中,k为2,即为模型分类数,表示正常类和非正常类,t为0.05;将所述的分类器输出向量输入到softmax层,得到k维向量,表示模型判别样本属于每个类别的概率p;对所述样本为正常类和样本为非正常类的概率分别设置对应的类别标签;对比所述样本为正常类和样本为非正常类的概率,选取较大概率所对应的类别标签作为分类判别结果。
21.根据本领域的公知常识,可以通过插值或者删除缺失段处理解决原始胎心率信号和宫缩信号的异常值和缺失值问题。而胎心率信号和宫缩信号具有一致性,对胎心率信号进行预处理时,可以对宫缩信号同步进行插值或删除处理。胎心率信号和宫缩压力信号的插值均选择中位数,插值后的序列波动较为平稳。
22.由于经过预处理后,原始ctg信号数据中信号长度不一,为此本发明通过对经预处
理的胎心率信号进行滑动窗口分段,舍弃信号长度少于15min(1125个点)的信号。
23.本发明通过采用极大值点间的距离进行滑动窗口分段。具体的,首先通过sg滤波(savitzky—golay)数字滤波器对经预处理的胎心率信号进行平滑降噪,信号的极值点对应的时间不发生改变;然后找出胎心率信号中所有的极大值点的集合,极大值点通过相邻两点的一阶差分来判断;再以信号长度10min作为一段进行窗口滑动处理,即以极大值点的集合中第一个点为终点,向前10min为第一段,接着开始滑动窗口,以下一个极值点为终点,向前10min作为新的一段,循环进行;再将滑动后的数据加上首尾,得到在信号上的滑动分段结果。
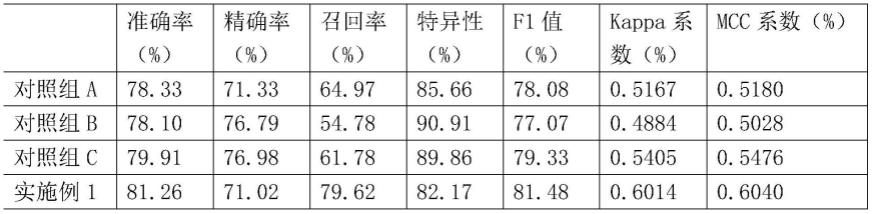
24.根据本领域的公知常识,基线(baseline)d的定义为10min内振幅稳定在5bpm 以内的胎心率均值。本发明通过对胎心率曲线的极值点进行聚类分析,从所有极值点中提取基线点,对基线点求平均得到胎心率信号的基线值。具体的,首先找出所有极值点的集合,对所有极值去中心化,然后采用k—means算法对得到的去中心化极值点进行聚类分析;标记区分得到结果的基线部分与非基线部分,再通过基线部分,对所有基线点的时间横坐标取均值tm,胎心率纵坐标取均值fm,分别作为该段胎心率信号的基线值(tm,fm);求出所有的胎心率分段基线值后进行基线拟合;将所有的基线值与胎心率曲线放在同一坐标系中进行数据拟合,数据拟合直接采用插值法,得到胎心率信号的基线值。
25.此外,本发明还可以通过使用经验模态分解(empirical mode decomposition, emd)处理,使得胎心率信号曲线更接近基线部分,减少极值点数量,有利于用极值点区分基线部分和非基线部分。
26.值得说明的是,本领域技术人员可以采用其他方法对获取的原始ctg信号数据进行预处理,或采取其他方法提取胎心率信号基线点,得到胎心率信号的基线值。
27.本发明的一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读模型包括特征提取器和分类器。googlenet特征提取器将所述信号长度均为d的胎心率信号和宫缩信号变为向量,并经过l2归一化处理输出。
28.分类器对所述的特征提取器输出的向量、k维权重向量w和温度系数t,进行计算,该层计算公式如下:softmax层根据分类器输出计算样本属于每个类别的概率p,计算公式如下:对比所述样本为正常类和样本为非正常类的概率后,选取较大概率所对应的类别标签可得到分类判别结果。
29.验证实例1为了验证googlenet神经网络结构对本发明的智能判读方法判别能力的影响。选取 alexnet、vgg和resnet三种神经网络结构作为特征提取器,设置对照组a、b、c,使用半监督领域自适应算法和同一ctg信号训练集、验证集训练模型后对比分析测试结果。验证实施例4对比分析实施例1和对照组a、b、c的准确率、精确率、召回率、特异性、f1值、kappa 系数、
mcc系数以及auc值,对比分析结果如表4所示。
30.上述对照组a采用的alexnet,共有8层结构,前5层为卷积层,后3层为全连接层,为了减少过拟合,在全连接层使用了dropout;对照组b采用的vgg,拥有13层卷积层和3层全连接层;对照组c采用的resnet是一种残差网络,通过子网络的堆叠构成一个深层网络;其余的方法步骤与实施例1保持一致。
31.表1各个特征提取器的性能对比分析结果表1的结果表明,对于最大最小熵半监督领域自适应算法,实施例1除了精确率以及特异性外都显著优于其他对照组,说明实施例1的智能判读模型的分类判别性能得到提高,可以有效识别非正常类,避免因错过治疗时机,对孕妇和胎儿的健康造成不可逆的伤害。
32.验证实例2采用如下的混淆矩阵验证本发明基于最大最小熵算法的多中心产前胎儿监护智能判读模型的判别能力,实施实例1的混淆矩阵如表2所示。预测/真实positivenegativepositivetp(truepositive)fp(falsepositive)negativefn(falsenegative)tn(truenegative)
33.表2实施例1的混淆矩阵预测/真实正常非正常正常82.52%20.38%非正常17.48%79.62%表2的结果表明,实施例1对于正常类样本的准确率最高,达到82.52%,非正常类样本的准确率达到79.62%,同时将真实的非正常类样本误判为正常类的概率为17.48%,将非正常类样本误判为正常类样本的可能性较低,可避免漏判,有利于孕妇得到及时的治疗。
34.验证实例3为了验证本发明对于多中心产前胎儿监护数据集的泛化性能,对googlenet从数据和方法两个角度进行实验,设置googlenet-t和googlenet-st两个对照组,分析使用领域自适应方法训练的模型和未使用领域自适应方法模型的性能,对比结果如表3所示。
35.上述的对照组googlenet-t在训练过程中只使用目标域有标签数据。上述对照组 googlenet-st在训练过程中使用源域所有数据和目标域的有标签数据,但不使用领域自适应方法。在输入数据集的划分上,将目标域数据划分为训练集:验证集:测试集=1:1:8,本组实验的验证集固定,并在同一测试集上进行分类判别,取输出概率最大值对应的标签作为输出结果,标签划分为正常类和非正常类。验证实施例1对比上述两个对照组的准确率、
精确率、召回率、特异性、f1值、kappa系数、mcc系数以及auc值。
36.准确率即正确率(accuracy),是深度学习中最常见的评判指标。精确率 (precision)表示被预测为正类的数据中预测正确的正类数据占比。召回率(recall)表示,实际为正类的数据中预测正确的正类数据占比。特异性(specificity)表示实际为负类的数据中预测正确的负类数据占比。所述精确率、召回率以及特异性涉及的正类为本发明的非正常类,负类为本发明的正常类。
37.f1值(f1-score)表示考虑精确率和召回率的综合性指标,当数据存在不平衡现象时,f1值更加具代表性。kappa系数表示描述判断一致性的指标,其数值越大表示一致性,水平越高。mcc系数(matthews correlation coefficient),马修斯相关系数,是衡量二分类器模型质量中信息最丰富的关键指标。
38.此外,验证实施例1引入接受者操作特性曲线(receiver operatingcharacteristic curve,roc)来评价深度学习模型的性能。为了衡量roc的结果,将roc 的面积定义为auc值(area under curve),取值范围为[0,1]。当auc的取值越大时,表示模型的分类效果越好。
[0039]
表3本发明的最大最小熵半监督领域自适应的泛化性能分析结果表3的结果表明,实施例1的准确率、精确率、召回率、f1值均高于只使用googlenet 学习分类,分别使用目标域有标签数据和同时使用源域、目标域有标签数据的两种情况。 googlenet-st和实施例1均使用了源域和目标域的有标签训练数据,不同的是,实施例1使用了半监督领域自适应算法,表现出比较明显的优势,在召回率方面体现尤为明显,有10.83%的优势。在胎心监护的临床应用中,较低的召回率意味着模型容易将非正常类判别为正常类,可能导致医师的漏判和误判,使孕妇未能得到及时的治疗,对孕妇和胎儿的健康造成严重的危害。综合各项评价指标,实施例1具有最好的泛化性能,可以为产科医护人员提供多中心产前胎儿监护的辅助决策。
[0040]
验证实例4为了验证本发明对多中心产前胎儿监护的判别能力,选取半监督领域自适应领域广泛使用的两种方法,dcnn(deep convolutional neural networks)域适应算法以及最小熵算法,使用同一ctg信号训练集和验证集训练模型后对比分析测试结果。
[0041]
上述的dcnn域适应算法对dcnn特征描述符添加l2约束,最小熵算法使用标准熵最小化有标签和目标域无标签的数据。验证实例2对比实施例1和上述两个半监督领域自适应模型的准确率、精确率、召回率、特异性、f1值、kappa系数、mcc系数以及auc值,对比分析结果如表4所示。
[0042]
表4各个半监督领域自适应模型与实施例1的性能对比分析结果
表4的结果表明,实施例1在综合指标如f1值、kappa系数、mcc系数和auc值上占有优势。同时在召回率上优势比较明显,这意味着模型不容易将非正常类判别为正常类,可以避免漏判和误判,在胎心监护的临床应用中具有重要意义。综合多项评价指标,实施例1的判读性能较优,更加适合胎心监护智能判读的临床应用。
[0043]
综上所述,本发明的一种基于最大最小熵半监督领域自适应的多中心胎心监护智能判读方法,首先对信号进行预处理,再利用滑动窗口进行数据增强,缓解数据不平衡问题并统一信号长度。其次,基于最大最小熵算法,利用源域大量已标注数据、目标域少量已标注数据和大量未标注数据,构建智能判读模型,所得模型在目标域数据上表现较好。对比传统的单中心智能判读模型,本发明有效解决训练集与测试集分布不同的问题,充分利用目标域已标注样本和未标注样本,在新的ctg数据集有更好的泛化性能,更适合医疗大数据背景下产前胎儿监护数据多中心分布的现实情况,减少了模型构建过程中的标注代价,辅助产科医护人员进行胎儿状态判断。同时,模型将非正常类样本错分为正常类样本的可能性更小,可以有效避免漏诊,在胎心监护的临床应用中具有重要价值。
[0044]
以上所述仅为本发明的优选实施例,但本发明的创造并不限于实施例,熟悉本领域的技术人员在本发明所公开的范围内,根据本技术方案的构思加以等同变形或者替换,均包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1