基于可解释自编码器的多组学与表型关联挖掘方法
1.本发明属于生物信息技术领域,具体涉及一种基于可解释自编码器的多组学与表型关联挖掘方法。
背景技术:
2.随着近年来高通量测序技术成本的降低和效率的提升,生物科学家们产出了大量不同类型的人体组学数据,这使得基于多组学分析的各种应用成为可能。相比传统基于单一组学的分析方法,多组学分析能从更深刻的视角对人体生理系统的运行进行准确地分析。此外,近年来,深度学习算法凭借其预测性能和捕获非线性和层次特征的能力,已经成为多组学数据分析中最有前途的方法之一。因此,基于深度学习的多组学分析方法在近年来已经成为了生物信息研究领域的一种重要分支,其中组学与人体表型关联模式探究更是领域内的热点。
3.表型一般指表现型,是有机体可被观察到的结构和功能方面的特性,如形态和行为方面的特征、疾病亚型和药物反应等。在生物医学研究中结合多组学可以从分子层面分析表型,并可以依此实现挖掘表型相关的生物标记物、探究人体微观调节机制、发现新型靶向药物和制定精准医疗方案等。因此,目前已经有大量的学者从事多组学表型关联的深度学习研究,并取得了大量的进展。例如,zhang等人提出了一种深度潜在空间融合(deep latent space fusion,dlsf)方法,在样本潜在空间中学习一致流形,整合多组数据进行疾病亚型识别;sun等人提出了整合多维数据的多模态深度神经网络(multimodal deep neural network,mdnnmd),该网络集成了拷贝数变异、基因表达和临床数据,利用全连接神经网络计算各个组学评分并在后期进行整合,最后实现了乳腺癌亚型的诊断;arya等人提出了一种基于随机森林分类器的封闭式专注深度学习模型,该模型利用多模态数据产生信息特征,增强乳腺癌预后预测性能。
4.然而,以上述方法为代表的当前大部分基于深度学习的多组学与表型关联研究在深度学习部分缺乏可解释性,因此通常会在深度学习模块之外添加一些统计分析机制以实现生物通路或基因级别的解释。虽然这些统计分析机制的有效性已经在过去的研究中被多次证明,但是这种方法与深度学习模块大部分是完全割裂的,即研究中最重要的深度学习部分依然是一个黑箱,只是作为一个预测器,并不能从该模型的角度对预测结果进行解释。
技术实现要素:
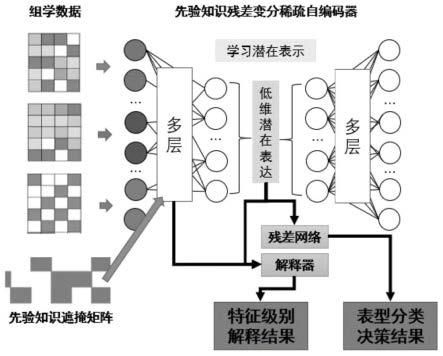
5.为了解决上述所提到的问题,本发明提出了一种基于可解释自编码器的多组学与表型关联挖掘方法。可解释自编码器更具体地又可称为可解释残差变分稀疏自编码器,由先验知识残差变分稀疏编码器、解码器和解释性分析模块三者组成。本发明首先搭建先验知识残差稀疏编码器,该编码器可利用先验知识,将高维多组学特征编码为蕴含所有组学隐含关联的低维潜在表达。其次构造解码器将低维潜在表达重新生成高维特征,根据该高维特征与原多组学特征的差异建立损失函数,为后续整个自编码器的训练奠定基础。然后,
在上述基础上增加基于加性特征归因的解释性分析模块,建立完整的可解释残差变分稀疏自编码器。再次,以低维表达为输入,建立残差神经网络,完成下游的分类或回归任务。最后,对可解释残差变分稀疏自编码器和残差神经网络分别进行训练,训练后的整个模型框架即可实现多组学与表型关联挖掘,其输入为多组学数据与先验知识,输出为神经元解释性评分和下游分类或回归任务的结果。
6.为了达到上述目的,本发明的具体技术方案如下:
7.一种基于可解释自编码器的多组学与表型关联挖掘方法,步骤如下:
8.步骤(1)构造先验知识残差变分稀疏编码器
9.多组学高维数据是冗余且充满噪声的,需经过预处理降维的方式才能可靠地进行表型与组学关联挖掘的工作。本发明采用了先验知识与稀疏编码结合的形式将多组学高维数据进行变分编码,并添加残差连接改善整个自编码器模型的训练难度。先验知识残差变分稀疏编码器的输入为多组学数据和先验知识遮掩矩阵,输出为多组学数据的编码。具体如下:
10.首先,由先验知识遮掩矩阵基于全连接网络编码器,搭建稀疏编码器结构。在编码器上一层与下一层的连接中,传统的自编码器采用全连接的形式进行连接,如下式:
11.y=f(w
t
x+b)
ꢀꢀꢀ
(1)
12.其中y为下一层的输出向量,x为上一层的输入向量,w为神经网络该层权重矩阵,b为偏置向量,f为激活函数。本发明在公式(1)的基础上引入了先验知识遮掩矩阵m。m为一个稀疏矩阵,其中的元素取值为0或1,在具有生物先验知识的信号通路中,取值为0则该条信号通路尚未打通,两者尚无已普及的联系,取值为1时说明目前现有知识通路是有联系的。引入m之后本发明将公式(1)改进为下式:
13.y=f((m*w)
t
x+b)
ꢀꢀꢀ
(2)
14.经过公式(2)的处理,全连接编码器在本发明中被改进为先验知识稀疏编码器。
15.其次,在上面的基础上添加隐空间概率分布机制,以构建先验知识变分稀疏编码器。该编码器与传统的全连接编码器不同,其先学习均值向量μ和方差向量σ,再由均值和方差结合高斯分布生成低维潜在表达z,具体如下式:
16.z=u+σ∈
ꢀꢀꢀ
(3)
17.∈为从高斯分布n(0,i)中采样的一个随机向量,i为单位矩阵。
18.最后,在上述基础上添加多重残差连接机制,构造先验知识残差变分稀疏编码器。设编码器共有n层,本发明在总输入到第一层输出,第一层输出到第二层输出,依此直至第n-2层输出到n-1层输出之间各添加残差连接机制。对于每一次残差连接,其原理基于下式:
[0019][0020]
代表残差模块的输出,x
l
为残差模块的输入,x
lws
为恒等映射,ws为匹配输入和输出维度的一个线性映射,f为需要学习的残差映射。
[0021]
通过上述过程即可建立本发明所提出的先验知识残差变分稀疏编码器。
[0022]
步骤(2)构建解码器与先验知识残差变分稀疏自编码器。
[0023]
解码器输入为步骤(1)输出的多组学数据的编码,输出为重构特征x
out
。将解码器与步骤(1)建立的编码器耦合即可构建先验知识残差变分稀疏自编码器,经过训练后输出
多组学的低维潜在表达,可为后续多组学与表型关联决策奠定基础。具体如下:
[0024]
首先,建立全连接的解码器,解码器基于公式(1)的全连接网络构建,层数以及每层的节点数量与编码器相同,但是节点之间的连接不采用遮掩矩阵,各层之间也无残差连接机制。
[0025]
其次,将解码器与步骤(1)的编码器进行耦合,构建先验知识残差变分稀疏自编码器。最后,对该自编码器进行训练。训练的损失函数如下式:
[0026]
loss=||x
in-x
out
||2+kl[n(u,σ),n(0,i)]
ꢀꢀꢀ
(5)
[0027][0028]
x
in
为自编码器的输入,即多组学数据,kl为散度函数,p(x)和q(x)两个不同的任意多项式,n为高斯函数。自编码器基于公式(5)和(6)进行训练,该训练与步骤(3)解释器一起进行,并依此实现自编码器深度学习模型的可解释性。此外,训练完成后的多组学低维潜在表达可作为步骤(4)的输入进行多组学与表型的分类决策。
[0029]
步骤(3)基于加性特征归因的解释器构造
[0030]
设f
原
是要解释的模型(自编码器),g是解释模型,关注一个局部特征x
局
,g使用一个简化的特征x
局
′
通过映射函数使得x
局
=h(x
局
′
),从而确保g(x
局
′
)≈f
原
(h(x
局
′
))。加性特征归因解释其为二元变量的线性函数,如下式:
[0031][0032]
其中m代表简化的特征数量,αi表示特征的效应值,将所有的特征效应值相加即可得到g(x
局
′
),使g(x
局
′
)逼近f
原
(h(x
局
′
))即可通过解释模型对f
原
中的每一个特征进行解释。换言之,基于加性特征归因的解释器目的是构造一个足够接近f
原
的g,并通过公式(7)中的特征效应值α对特征的重要性进行解释,即计算α是解释器的最终目标。
[0033]
本发明通过最小化目标函数ω计算α,目标函数如下式:
[0034][0035]
其中表示核函数,τ(g)为正则项,l为平方损失函数。上式的意义为,g对f
原
的逼近是通过简化在输入空间中核函数加权的一组样本损失l而进行的。最小化ω后,g和f
原
实现了拟合,并通过计算出特征效应值α,从而实现对各个特征的解释。
[0036]
步骤(4)构建残差网络
[0037]
残差网络的输入为步骤(2)训练完成的多组学低维潜在表达输出为表型分类决策结果。本发明使用的残差网络为一维残差网络,该残差网络由多个输入和输出维度不同的残差块组成。更具体地,每个残差块由两个卷积块顺序连接以及残差连接构成,残差连接源头是第一个卷积块的输入,目的是第二个卷积块输出,连接方式基于公式(4)。再加上池化层、四个残差网络模块、全局平局池化层以及全连接层共同组成残差网络,该残差网络经过训练即可实现表型分类决策。
[0038]
综上所述,本发明输入为先验知识遮掩矩阵m与多组学数据,输出为组学特征级别的解释性和表型分类决策结果,这两种输出即实现了多组学与表型的可解释关联挖掘。
[0039]
本发明的有益效果:本发明致力于提高组学-表型关联挖掘的准确性、可靠性和可解释性。一方面,通过先验知识残差变分稀疏自编码器融合了多种组学数据与先验知识,通过基于先验知识的多组学整合以及提出的自编码器自身性质,提高了表型分类决策的准确性和抗噪性;另一方面,通过引入解释器对特征进行效应值,实现了整体深度学习模型分类决策结果的特征级别可解释性,避免了传统深度学习的“黑盒”问题,从解释层面提高了模型的可靠性。
附图说明
[0040]
图1是本发明的整体框架图。
[0041]
图2是本发明的可解释残差变分自动编码器构造图。
[0042]
图3是本发明的工作流程图。
具体实施方式
[0043]
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
[0044]
本发明的基于可解释自编码器的多组学与表型关联挖掘方法整体框架如图1所示,输入为多组学数据与先验知识遮掩矩阵,输出为特征级别解释结果和表型分类决策结果。整体框架大致可分为三部分:构建先验知识残差变分稀疏自编码器、构造解释器、建立残差网络。每个部分具体功能如下:
[0045]
(1)先验知识残差变分稀疏自编码器。其输入为多组学数据与先验知识遮掩矩阵,经过训练后输出符合多组学隐空间概率分布的多组学的低维潜在表达,潜在表达可为后续多组学与表型关联决策奠定基础。此外,该自编码器的训练还可与解释器进行耦合,为特征级别的解释建立根基。
[0046]
(2)解释器。解释器基于加性特征归因的方法与自编码器及残差网络进行耦合,在残差网络实现表型分类决策的同时,通过效应值计算给出各个特征对表型分类的影响程度,并依此得到特征级别的可解释性。
[0047]
(3)残差网络。本发明构造一个深度残差神经网络,输入为自编码器输出的多组学低维表达,输出为表型分类决策结果。
[0048]
下面以乳腺癌多组学与表型关联挖掘为例,结合流程图3对本发明的具体实施方式进行详细阐述。特别指出,本实施例的实施场景为乳腺癌多组学与表型关联挖掘,所论述的具体实施方案仅用于说明本发明的实现方式,而不限制本发明的范围。本样例所用数据源自美国癌症基因组图谱,共包括三种不同类型的组学数据(dna甲基化、mrna和mirna),共600个样本,每个样本表型可被分为五种类别之一(basal-like、her2、luminal a、luminal b和normal-like)。
[0049]
(1)建立先验知识残差变分稀疏自编码器。如图2所示,首先参考公式(2)基于先验知识遮掩矩阵和乳腺癌多组学数据(dna甲基化、mrna和mirna,特征维度分别为20106、20156和823),稀疏化编码器各层节点的连接结构,并结合公式(4)建立残差连接。其次,基于公式(3)将编码器的输出处理为隐空间概率分布的低维潜在表达。其次,构建全连接解码器,与编码器耦合搭建完整的先验知识残差变分稀疏自编码器。最后,对应图3中模型训练步骤,基于公式(5)和公式(6)进行训练,生成低维潜在表达,并与解释器进行耦合。
[0050]
本步骤编码器层数为5层,节点数分别为41085、16368、4096、1024和512。解码器层数和节点数量与编码器一致。
[0051]
(2)基于公式(7)和公式(8)建立解释器,解释器与残差网络、低维潜在表达以及自编码器进行耦合,进行特征水平的解释。
[0052]
(3)建立18层的残差网络,基于(1)的512维潜在表达对乳腺癌亚型进行分类预测。
[0053]
完成上述工作后,对于每一个样本,由步骤(3)可得到该样本的乳腺癌表型分类结果(五种类别之一),由步骤(2)可对输入特征的重要性进行排序,从而量化各特征对分类结果所产生的影响强弱,在特征级别上实现结果的可解释。完成了样本分类与特征重要性排序,在本发明中即实现了乳腺癌多组学与表型的可解释关联挖掘。在实施样例中,整体模型对样本的分类准确率超过了83%,且由特征重要性排序结果亦可在特征级别上寻找与乳腺癌相关的潜在生物标志物(如amy1a、col11a2、tmem207)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1