一种用于深度学习判别模型训练的功能多肽数据库的制作方法
1.本发明涉及数据库领域,具体而言,涉及一种用于深度学习判别模型训练的功能多肽数据库。
背景技术:
2.多肽是一种由肽键将氨基酸序列结合而成的化合物,是一种从生命的起初就伴随机体的重要营养物质。作为蛋白质的水解产物,多肽具有非常广的功能意义。尽管多肽分子量小,但它便于被人类吸收,因此常作为营养物质被广泛用于食物,营养食品,临床医药,调控机体的免疫系统,在机体中发挥抗氧化,抗炎修复,抗菌,抗癌以及抗病毒等功能;不同的氨基酸序列及表达量会决定多肽的功能及价值,在当前,天然界已知的功能多肽数以万计,来源非常广泛,从最原始的细菌到植物以及到高等生物都有。
3.目前从事研究多肽功能预测算法的研究人员大多数训练的机器学习模型,深度学习模型主要用于判别多肽是否具有某种单一的功能;目前尚未有系统性训练多分类的深度学习模型用于判别多肽是否具有某一特定的生物功能;深度学习是一种数据驱动的方法,训练的模型的准确度十分依赖训练数据集;然而,针对这些多种多样,序列相似性低又功能复杂的生物大分子,目前尚未有一个系统性的智能判别方法将多肽序列的多样性和其活性功能直接联系到一起。
4.如何发明一种用于深度学习判别模型训练的功能多肽数据库来改善这些问题,成为了本领域技术人员亟待解决的问题。
技术实现要素:
5.为了弥补以上不足,本发明提供了一种用于深度学习判别模型训练的功能多肽数据库,旨在改善尚未有一个系统性的智能判别方法将多肽序列的多样性和其活性功能直接联系到一起问题。
6.本发明是这样实现的:
7.本发明提供一种用于深度学习判别模型训练的功能多肽数据库,包括数据库建立步骤以及数据库,数据库建立步骤如下:
8.互联网检索相关的多肽数据集信息,汇集29个标注功能的多肽数据源;
9.将积累的已标注功能多肽数据集分类成七份,得到七个功能肽库;
10.将收集得到的七个功能子库汇集到一个csv文件中,并利用python pandas保存到一个data frame表格中,对每个多肽保存序列,标注功能以及数据源;
11.利用bio sql将多肽库存为通用的sql格式;
12.利用ncbi本地版的makeblastdb将多肽库转化blastpdb,用来比对未知功能的多肽序列;
13.使用本地版的深度学习蛋白结构预测工具alphafold2对序列库中的每条多肽进行结构预测,并将预测的每条序列5个结构模型的pdb保存到一个af2db结构数据库;
14.用上述步骤建立的数据库训练深度学习多肽功能判别模型。
15.优选的,多肽数据源可直接点击下载多肽序列,或需要根据网页格式编写适应的爬虫脚本抓取多肽序列。
16.优选的,七个功能肽库如下:抗氧化肽库,抗炎修复肽库,抗癌肽库,抗病毒肽库,抗菌肽库,神经肽库以及免疫原肽库。
17.优选的,将积累的已标注功能多肽数据集分类成七份,得到七个功能肽库;对每一个功能肽库,排查重复序列(库频》1),并将只含有20种天然氨基酸残基的多肽序列进行保存。
18.优选的,使用本地版的深度学习蛋白结构预测工具alphafold2对序列库中的每条多肽进行结构预测,并将预测的每条序列5个结构模型的pdb保存到一个af2db结构数据库,预测使用方法为:gor方法;gor方法将蛋白质序列当作一连串的信息值来处理,该方法不仅考虑了被预测位置本身氨基酸残基种类的影响,而且考虑了相邻残基种类对该位置构象的影响。
19.优选的,数据库包括:
20.数据收集模块:用于通过检索互联网检索相关的多肽数据集信息,共汇集了29个标注功能的多肽数据源;
21.数据汇交模块:用于将积累的已标注功能多肽数据集进行分类,总共分为七类,并对每一个功能肽库,排查重复序列(库频》1),并只保留只含有20种天然氨基酸残基的多肽序列;
22.数据存储模块:用于将收集得到的七个功能子库汇集到一个csv文件中,并利用python pandas保存到一个dataframe表格中,对每个多肽保存序列,标注功能以及数据源;
23.数据应用模块:包括将这个功能多肽库用于训练深度学习多肽功能判别模型,基于分子对接技术的多肽药物虚拟筛选以及建立对外开放的功能多肽数据库网站。
24.优选的,数据存在模块还包括:利用biosql将多肽库存为通用的sql格式;并利用ncbi本地版的makeblastdb将多肽库转化blastpdb,用来比对未知功能的多肽序列。
25.优选的,数据存在模块还包括:使用本地版的深度学习蛋白结构预测工具alphafold2对序列库中的每条多肽进行结构预测,并将预测的每条序列5个结构模型的pdb保存到一个af2db结构数据库,用来做基于靶点蛋白的虚拟分子对接。
26.本发明的有益效果是:
27.本发明在对数据库的建立过程中大量使用基于python编程和爬虫技术,以此获取公有肽数据源上目标功能肽的序列信息;本数据库以csv格式存储每条多肽的序列及其生物功能信息,方便后期用于基于nlp自然语言的深度学习算法的运用,并且可以有效地帮助研发人员快速对众多候选多肽进行优先级。
附图说明
28.为了更清楚地说明本发明实施方式的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
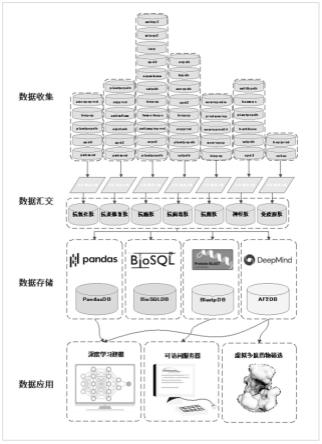
29.图1是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库构架图;
30.图2是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库零星分散的功能多肽数据集来源图;
31.图3是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库可用于训练深度学习判别模型的功能多肽数据集图;
32.图4是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库分布于plantpepdb的抗氧化多肽示意图;
33.图5是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库抓取plantpepdb数据库网页表格中的抗氧化多肽汇聚到一个fasta文件的流程示意图;
34.图6是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库抓取satpb数据库网页表格中的抗癌多肽汇聚到一个fasta文件的流程示意图;
35.图7是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库从pubmed文献数据库获取特定功能多肽序列的流程示意图;
36.图8是本发明实施方式提供的一种用于深度学习判别模型训练的功能多肽数据库基于功能多肽数据库构建的深度学习多肽功能判别模型示意图。
具体实施方式
37.为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
38.实施例
39.参照图1-8,一种用于深度学习判别模型训练的功能多肽数据库,包括数据库建立步骤以及数据库,数据库建立步骤如下:
40.s1:互联网检索相关的多肽数据集信息,汇集29个标注功能的多肽数据源,多肽数据源可直接点击下载多肽序列,或需要根据网页格式编写适应的爬虫脚本抓取多肽序列;
41.s2:将积累的已标注功能多肽数据集分类成七份,得到七个功能肽库,七个功能肽库如下:抗氧化肽库,抗炎修复肽库,抗癌肽库,抗病毒肽库,抗菌肽库,神经肽库以及免疫原肽库,对每一个功能肽库,排查重复序列(库频》1),并将只含有20种天然氨基酸残基的多肽序列进行保存;本数据库囊括了七种不同功能的多肽,多肽序列源自公认的肽库以及实验研究报道的文献;序列的特定功能活性已经被前人标记,样本量到达10^4,可用于训练一个多分类(七分类)的深度学习判别模型;
42.s3:将收集得到的七个功能子库汇集到一个csv文件中,并利用pythonpandas保存到一个dataframe表格中,对每个多肽保存序列,标注功能以及数据源;
43.s4:利用biosql将多肽库存为通用的sql格式;
44.s5:利用ncbi本地版的makeblastdb将多肽库转化blastpdb,用来比对未知功能的多肽序列;
45.s6:使用本地版的深度学习蛋白结构预测工具alphafold2对序列库中的每条多肽进行结构预测,并将预测的每条序列5个结构模型的pdb保存到一个af2db结构数据库,预测使用方法为:gor方法;gor方法将蛋白质序列当作一连串的信息值来处理,该方法不仅考虑了被预测位置本身氨基酸残基种类的影响,而且考虑了相邻残基种类对该位置构象的影响;
46.gor针对长度为17的残基窗进行二级结构预测;对序列中的每一个残基,gor方法将与它n端紧邻的8个残基和c端紧邻的8个残基与它放在一起进行考虑;gor方法是通过对已知二级结构的蛋白样本集进行分析,计算出中心残基的二级结构分别为螺旋、折叠和转角时每种氨基酸出现在窗口中各个位置的频率,从而产生一个17x20的得分矩阵;然后利用矩阵中的值来计算待预测的序列中每个残基形成螺旋、折叠或者转角的概率;gor方法是基于信息论来计算这些参数的,下面介绍gor方法的数学基础:
47.首先考虑两个事件s和r的条件概率p(s|r),即在r发生的条件下,s发生的概率;定义信息为:
48.i(s;r)=log[p(sr)p(s)]
[0049]
若s和r无关,即p(s|r)=p(s),则i(s;r)=0;若r的发生有利于s的发生,即p(s|r)>p(s),则i(s;r)>0;如果r的发生不利于s的发生,则p(s|r)<p(s),则i(s;r)<0;使用对数的优点在于可将概率的乘积变为信息值的加和;在二级结构预测过程中,s表示特殊的二级结构类型,r代表氨基酸残基,p(sir)就是残基r处于二级结构类型s的概率;p(s)是在统计过程中观察到二级结构类型s的概率;根据条件概率的定义:
[0050][0051]
p(s,r)是同时观察到s和r的联合概率,而p(r)是r的出现概率;对现有蛋白质序列数据库和二级结构数据库进行数学统计分析,很容易得到i(s;r);如果令n为数据库中总的氨基酸残基的个数,fr在为残基r的总个数,fs为处于二级结构类型s的残基总数,f
s,r
为残基r处于二级结构类型s的总数,则;
[0052]
p(s,r)=f
s,r
/n
[0053]
p(r)=fr/n
[0054]
p(s)=fs/n
[0055]
r处于二级结构类型s的信息值按下式计算:
[0056]
i(s;r)=log[(f
s,r
/fr)fs/n]
[0057]
信息差的计算公式如下:
[0058]
i(δs;r)=i(s;r)-i(s
′
;r)=log(f
s,r
/fs′
,r
)+log(fs′
/fs)
[0059]
这里s`表示除s之外的其它所有二级结构类型;例如,如果s代表α螺旋,则在三态情况下s`代表β折叠或者转角,信息值计算公式从正反两个方面给出了关于氨基酸残基r与二级机构s关系的信息值;
[0060]
若r可以分为两个较简单的事件r1和r2,则有:
[0061]
i(s;r)=i(s;r1,r2)=log[p(s|r1,r2)/p(s)]
[0062]
=log[p(s|r1,r2)/p(s|r1)]+log[p(s|r1)/p(s)]
[0063]
式中第一项表示在r1发生的条件下,r2对事件s的影响,第二项表示r1对s的影响,
上式可改为:i(s;r)=i(s;r2|r1)+i(s;r1);
[0064]
同理,若r可分解为一系列的简单事件r1,r2,...,rn,则有
[0065]
i(s|r)=i(s;r1)+i(s;r2|r1)+i(s;r3|r2,r1)+...+i(s;rn|r1,r2,...,r
n-1
)
[0066]
这里,r1,r2,...,rn代表蛋白质序列中一组连续的残基,预测的对象是中心残基,判断它处于什么样的构象态,其它残基作为环境;gor方法只考虑待预测残基及其两侧各8个残基;
[0067]
gor方法考虑了中心残基r1的影响,信息计算公式如下:
[0068]
i(δs;r)=i(δs;r1)+i(δs;r2r1)+i(δs;r3r1)+...+i(δs;rnr1)
[0069]
通过统计,可以得出各种残基r处于中心残基周围各位置i时的信息值i(δs;ri)或i(δs;ri|r1),它们反应了周边残基对中心残基形成特定二级结构的影响,再通过上式近似公式,就可计算出i(δs;r);对于一条肽链中任一位置残基r的构象预测过程包括三个步骤:
[0070]
(1)以r为中心,取其左右两侧共17个残基作为计算的窗口(记为r);
[0071]
(2)取窗口内每个残基的信息值i(δs;ri),并按照上式近似公式加和,得到i(δs;r);
[0072]
(3)中心残基r的二级结构预测为i(δs;r)最大的二级结构类型s;
[0073]
假定数据库中有1830个残基,780个处于螺旋态,1050个处于非螺旋态;库中共有390个丙氨酸(a),有240个a处于螺旋态,其余150个a处于非螺旋态。可得:
[0074]fh
=780/1830
[0075]fh
′
=1050/1830
[0076]fh,a
=240/390
[0077]fh
′
,a=150/390
[0078]
根据公式i(δs;r)=i(s;r)-i(s
′
;r)=log(f
s,r
/fs′
,r
)+log(fs′
/fs),有:
[0079]
i(δh;a)=log(f
h,a
/fh′
,a
)+log(fh′
/fh)
[0080]
=log(240/390)(150/390)+log(1050/1830)(780/1830)
[0081]
=0.7650
[0082]
这里h代表二级结构螺旋态,而h'代表除h以外的其它类型二级结构,i(δh;a)就是丙氨酸a处于中心位置时的螺旋信息值;
[0083]
s7:用上述步骤建立的数据库训练深度学习多肽功能判别模型。
[0084]
进一步的,数据库包括:
[0085]
数据收集模块:用于通过检索互联网检索相关的多肽数据集信息,共汇集了29个标注功能的多肽数据源;
[0086]
数据汇交模块:用于将积累的已标注功能多肽数据集进行分类,总共分为七类,并对每一个功能肽库,排查重复序列(库频》1),并只保留只含有20种天然氨基酸残基的多肽序列;
[0087]
数据存储模块:用于将收集得到的七个功能子库汇集到一个csv文件中,并利用pythonpandas保存到一个dataframe表格中,对每个多肽保存序列,标注功能以及数据源;
[0088]
数据应用模块:包括将这个功能多肽库用于训练深度学习多肽功能判别模型,基于分子对接技术的多肽药物虚拟筛选以及建立对外开放的功能多肽数据库网站。
[0089]
进一步的,数据存在模块还包括:利用biosql将多肽库存为通用的sql格式;并利用ncbi本地版的makeblastdb将多肽库转化blastpdb,用来比对未知功能的多肽序列。
[0090]
进一步的,数据存在模块还包括:使用本地版的深度学习蛋白结构预测工具alphafold2对序列库中的每条多肽进行结构预测,并将预测的每条序列5个结构模型的pdb保存到一个af2db结构数据库,用来做基于靶点蛋白的虚拟分子对接。
[0091]
基于本数据库建立的多肽功能判别模型可用于辅助实验人员在提取天然食物来源的多肽后预判未知功能的多肽的潜在功能(见图8),比如通过先验ai模型虚拟筛选富集抗氧化肽,减少后续多肽功能表征实验的测试成本;通常,研究人员为了获得某一食物来源的多肽,会用相关蛋白酶水解食物来源的功能蛋白,然后利用质谱技术获取到若干天然功能多肽的序列信息,这些功能未知的多肽样本量可高达数千条;若逐一对这些多肽进行功效评价将耗费巨大的人力,物力,以及时间;若引入深度学习判别模型对多肽进行功能预判,可以有效地帮助研发人员快速对众多候选多肽进行优先级;比如研发人员希望尽量获取较多的抗氧化多肽,则可以根据深度模型判别若干候选多肽具有抗氧化性的概率将多肽数据集进行排序,将含抗氧化肽概率最大的多肽序列优先级放置最高,从而缩小功效测试集的范围,加速整个研发流程;
[0092]
本数据库可建立本地或图形界面的检索接口(ui),可以作为功能活性肽信息库帮助研究人员快速检索含有特定目标功能的多肽(比如检索抗炎修复肽)的序列多样性信息,辅助研发人员进行特定功能肽的序列重设计和定向进化,从而帮助研发人员节省了大量时间,降低研发成本;构建的功能多肽数据库可以格式化成可以用blastp检索的数据库格式,然后用户可以在终端输入一条待检索多肽,blastp可以针对输入的检索序列与功能多肽库的每条序列进行同源比对,然后输出具有一定序列相似性的若干参考序列提供给用户。这些输出的相似序列可以作为参考辅助用户进行已有序列的设计(比如规避已经被保护的多肽序列);然后用户设计好的序列又可以用深度学习多肽功能判别模型进行预判筛选,看设计的序列是否具有预期的功能,如此进行目标多肽序列的定向进化;
[0093]
本数据库锁定需要搜集序列的七种目标功能肽,包括免疫相关肽,神经相关肽,抗菌肽,抗病毒肽,抗癌肽,抗炎修复肽以及抗氧化肽。(2)针对每一种特定功能的多肽,尽可能的从公有多肽库收集含有该特定功能的多肽;这七种特定功能肽,除了免疫相关肽在iedb数据库中集中分布,其他六种功能多肽的序列分散在众多公有数据库(见图2,例如plantpepdb,apd3,satpdb,biopep,tumorhope,avpdb)以及github上的开源数据集中,总共汇集了约三万条多肽(见图3);值得注意的是,每个数据集的不完全是能通过鼠标点击就能一键下载的方式获取;很多数据库把每条多肽的序列信息分散在众多网页上,比如plantpepdb的抗氧化多肽分散在23个网页的表格里面(参考图4);为了一次性批量获得plantpepdb所有的抗氧化肽,编写python脚本下载所有位于plantpepdb数据库的抗氧化肽的网页php并打包汇聚到一个fasta文本格式(见图5);又比如satpdb数据库将抗癌多肽分布于22页网页上,我们也通过编写python爬虫脚本将所有抗癌肽汇聚到一个fasta文本文档(见图6).
[0094]
以上所述仅为本发明的优选实施方式而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1