一种基于血常规数据的过敏源数据提取方法与流程
1.本发明涉及大数据提取技术领域,更具体的说是涉及一种基于血常规数据的过敏源数据提取方法。
背景技术:
2.目前,现有的过敏性疾病起因分析方法主要是利用过敏原筛查,对筛查结果进行分析得到引起过敏性疾病的原因,其中关键技术为过敏原筛查。
3.过敏原筛查方法包含体内试验和体外试验。体内试验就是皮肤试验,包含皮内试验、点刺试验和斑贴试验,皮内实验是用针管在皮肤内注射过敏原;点刺试验和斑贴试验是将微量的过敏原浸液通过针刺接种或贴在皮肤上吸收。体内试验是通过观察皮肤局部红肿情况,根据红肿面积判断是否对该过敏物质过敏。体外试验是通过血液检查,主要检测血液中的特异性lge抗体,若其可以测到并且达到一定数值,则判断为过敏。
4.但是,体内试验的弊端是容易出现假阳性结果,比如具有皮肤划痕症的患者会因为检查过程的针刺操作引起皮肤红肿痒等反应,从而误认为是阳性结果;若患者严重过敏,体内试验会因接触过敏原而造成严重的过敏反应,严重者会造成过敏原休克危及生命。体外实验的缺点是与实际情况的符合率不高;能检测的特异性抗体有限,即使根据检测结果进行食物回避,也经常无法控制症状;检测费用过高。因此利用传统的过敏原筛查方法进行过敏性疾病起因分析不仅存在危险性,而且因其过敏原浸夜较少和费用问题导致无法大范围开展过敏性疾病起因的分析研究。
5.因此,因此如何通过常规数据获得人体过敏源表征数据是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种基于血常规数据的过敏原数据提取方法,首先避免了体内试验严重过敏反应的发生,降低危险性;其次避免具有皮肤划痕症的患者出现假阳情况,减少假阳的概率;最后降低成本,可以大规模地进行过敏性疾病的起因分析,使得分析结果具有可靠性。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种基于血常规数据的过敏源数据提取方法,包括以下步骤:
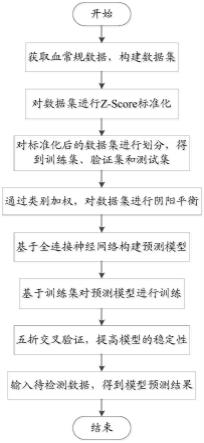
9.s1、获取血常规数据,构建数据集,对数据集进行z-score标准化,对标准化后的数据集进行划分,得到训练集、验证集和测试集;
10.s2、基于全连接神经网络构建预测模型;
11.s3,基于训练集对预测模型进行训练,通过类别加权,对数据集进行阴阳平衡,通过五折交叉验证,提高模型的稳定性;
12.s4、输入待检测数据,得到模型预测结果。
13.优选的,所述预测模型为多种,包括由3层全连接层和3层dropout层构成,以及4层
全连接层和4层dropout层构成。
14.优选的,所述数据集的划分方式为,训练集:验证集:测试集=6:2:2。
15.优选的,基于数据集的原始均值和和标准差进行数据的标准化,z-score标准化的转换公式:
[0016][0017]
其中,x为样本观测值,μ为总体数据均值,σ为总体数据的标准,使经标准化后的数据的均值为0,标准差为1。
[0018]
优选的,所述预测模型为y=x
×
w+b,其中,x为输入,代表年龄、性别以及22项血常规指标,y为隐藏层输出,即提取的特征向量,w为模型隐藏层权重,b为偏置项;
[0019]
优选的,所述类别加权为当“0”类样本数量多于“1”类样本数量时,通过调高“1”类权重达到平衡。
[0020]
优选的,所述五折交叉验证为进行5次随机抽取,每次抽取后完成一次训练测试,得到5次的训练结果和测试结果,对其求均值得到最终模型的训练结果和测试结果。
[0021]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于血常规数据的过敏源数据提取方法,首先避免了体内试验严重过敏反应的发生,降低危险性;其次避免具有皮肤划痕症的患者出现假阳情况,减少假阳的概率;最后降低成本,可以大规模地进行过敏性疾病的起因分析,使得分析结果具有可靠性。
附图说明
[0022]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0023]
图1附图为本发明提供的模型训练流程结构示意图。
具体实施方式
[0024]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0025]
本发明实施例公开了一种基于血常规数据的过敏源数据提取方法,包括以下步骤:
[0026]
s1、获取血常规数据,构建数据集,对数据集进行z-score标准化,对标准化后的数据集进行划分,得到训练集、验证集和测试集;
[0027]
s2、基于全连接神经网络构建预测模型;
[0028]
s3,基于训练集对预测模型进行训练,通过类别加权,对数据集进行阴阳平衡,通过五折交叉验证,提高模型的稳定性;
[0029]
s4、输入待检测数据,得到模型预测结果。
[0030]
为进一步优化上述技术方案,预测模型为多种,包括由3层全连接层和3层dropout层构成,以及4层全连接层和4层dropout层构成。
[0031]
为进一步优化上述技术方案,数据集的划分方式为,训练集:验证集:测试集=6:2:2。
[0032]
为进一步优化上述技术方案,基于数据集的原始均值和和标准差进行数据的标准化,z-score标准化的转换公式:
[0033][0034]
其中,x为样本观测值,μ为总体数据均值,σ为总体数据的标准,使经标准化后的数据的均值为0,标准差为1。
[0035]
为进一步优化上述技术方案,预测模型为y=x
×
w+b,其中,x为输入,代表年龄、性别以及22项血常规指标,y为隐藏层输出,即提取的特征向量,w为模型隐藏层权重,b为偏置项,模型隐藏层权重和偏置项通过最小化损失函数,反向传播更新,损失函数通过交叉熵损失函数得到;
[0036]
为进一步优化上述技术方案,类别加权为当“0”类样本数量多于“1”类样本数量时,通过调高“1”类权重达到平衡。
[0037]
为进一步优化上述技术方案,五折交叉验证为进行5次随机抽取,具体的,选择5种不同样本的集合,每次抽取后完成一次训练测试,得到5次的训练结果和测试结果,对其求均值得到最终模型的训练结果和测试结果。
[0038]
分别训练各种起因的预测模型。实验数据共有11种可能引起过敏性疾病的原因,分别为尘霾组合、草、猫/狗毛皮屑、蟑螂、鸡蛋、牛奶、鱼虾蟹、牛/羊肉、霉菌组合、树木组合、小麦,引起过敏性疾病的样本为阳性样本,没有引起过敏性疾病的样本为阴性样本,表1为数据集描述表。
[0039]
表1数据集描述表
[0040][0041]
本发明是基于全连接神经网络构建过敏性疾病的起因预测模型,除鸡蛋以外的其他起因预测模型是由3层全连接层和3层dropout层构成,起因为鸡蛋的预测模型是由4层全连接层和4层dropout构成。表2、表3、表4分别为鸡蛋起因预测模型结构参数、小麦起因预测模型结构参数、其他起因预测模型结构参数(3个模型的结构参数涵盖了11种起因预测模型参数)。
[0042]
表2鸡蛋起因预测模型结构参数
[0043]
[0044][0045]
表3小麦起因预测模型结构参数
[0046][0047]
表4其他起因预测模型结构参数
[0048]
[0049][0050]
训练模型前需要对数据集进行z-score标准化。训练过程中,数据集划分按训练集:验证集:测试集=6:2:2进行划分,epoch设置为100,batch_size设置为32。由于数据集阴性和阳性样本不平衡,需要加入类别加权。
[0051]
由于数据集样本数量较少,导致模型性能不稳定,因此本发明加入五折交叉验证,模型预测结果是由五个模型预测结果的均值构成。
[0052]
本实验的实验结果如表5所示。
[0053]
表5实验结果
[0054]
[0055]
[0056][0057]
由表5可知,测试集的auc居于0.8以上的有猫/狗毛皮屑、蟑螂、鱼虾蟹、小麦;auc大于0.7小于0.8的有草、鸡蛋、牛奶、牛/羊肉、霉菌组合;auc小于0.7的有尘霾、树木组合。因此,本发明可以准确识别猫/狗毛皮屑、蟑螂、鱼虾蟹、小麦起因;较为准确的有草、鸡蛋、牛奶、牛/羊肉、霉菌组合起因;对尘霾和树木起因的预测能力一般,不符合实际应用要求。
[0058]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0059]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1