一种基于通量平衡分析的代谢网络关键因子挖掘方法
1.本发明属于生物工程领域,具体涉及一种利用通量平衡分析以及代谢网络进行关键因子挖掘的方法,其可用于通过分析目标反应通量对代谢产物的动态调节结果,来确定影响代谢产物的代谢网络中的关键因子。
背景技术:
2.在工业生产中,很多生活必需的化合物如燃料和塑料、聚合物和药物材料等都可以通过微生物代谢工程生产。代谢工程通过操纵微生物的基因或者酶为制造天然产品提供了一条绿色可持续的代谢途径,用于进行进一步的途径改造和大规模生产。但是在很多情况下,由于途径中参与反应的酶活性不足和中间代谢产物利用不充分的限制,导致细胞工厂目标代谢产物的产量不足,这种在代谢网络中对代谢产物的产量具有较大的影响的反应,被定义为促进目标代谢产物的关键因子。
3.由于代谢网络中生化反应和酶的对应关系,有一些工作是基于限速酶来定位关键反应的。例如,异戊烯基二磷酸(ipp)-二甲基烯基二磷酸(dmapp)异构酶(idi)是异戊二烯生物合成的一个限速酶,由于它具有调整ipp和dmapp的细胞内浓度方面的作用,并发现其对应基因的有序共表达可以明显改善大肠杆菌中的异戊二烯生产,这些限速酶的过表达可以有效提高对应关键反应的代谢通量,进而提高mep途径的通量,最终提高目标产品的前体供应和最终产物的生产。
4.现阶段,对于关键因子的挖掘和定位研究大多都是基于生物实验,体外模拟途径等。例如,通过遍历代谢途径中的所有基因,按顺序敲除单个目标基因,对比敲除前后底盘细胞对于目标化合物的产量,依此来判断目标基因对应的生化反应是否为影响代谢的关键因子,但由于实验成本和技术限制,很难扩大评估目标途径。体外实验是通过在含有底物和辅助因子的溶液中加入催化途径反应的酶的混合物来启动代谢途径,模拟体内的代谢过程,这一方法将体内的整条途径搬到体外来进行产物提取分析,从而定位到目标酶所对应的关键反应。由于代谢系统的复杂性,这一方法缺少生物体内酶的相互作用信息,不能完全模拟代谢过程。
5.之前的工作由于生物实验和体外模拟途径的限制,不能有效地提取多个代谢关键因子。并且,对于代谢途径中的大多数酶来说,直接对其产物进行高通量检测可操作性不高。此外,对多个关键酶进行单独的酶修饰难度也极大,而且可能会产生新的关键因子。有的工作是基于文献整理收集了不同物种的限速酶数据库,缺乏对其他未测量菌株或者生物的关键酶的注释。还有的方法是基于单独一种底盘细菌进行的关键因子或者限速步骤的研究,对其它菌株缺少指导价值。
技术实现要素:
6.针对上述技术问题,本发明的目的在于提供一种基于通量平衡分析的代谢网络关键因子挖掘方法。该方法不需要复杂的领域知识,通过输入代谢网络模型以及目标化合物,
可以直接挖掘对目标化合物影响最大的k个反应,用于快速辅助生物学家优化代谢网络。本方法所描述的关键因子指代谢网络中的特定生化反应,然后可以根据代谢网络中反应和酶的对应关系,可以定位该生化反应对应的催化酶,从而从蛋白质组学和代谢组学分析目标途径。
7.本发明提供的技术方案如下:
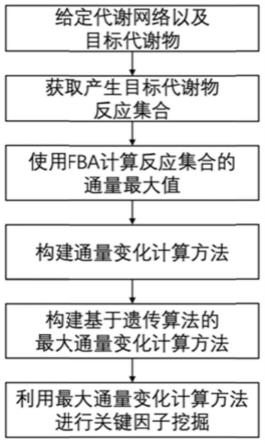
8.一种基于通量平衡分析的代谢网络关键因子挖掘方法,包括以下步骤:
9.步骤一:从已知代谢网络n中获取反应集合r以及代谢物集合m,给定目标代谢物m
t
,其中,m
t
∈m;
10.步骤二:从反应集合r中获取所有反应产物为m
t
的反应集合r
t
,其中
11.步骤三:使用通量平衡分析(flux balance analysis,fba)计算初始条件下反应集合r
t
的通量最大值v;
12.步骤四:构建通量变化计算方法a,计算给定反应r在给定scale下的目标产量变化值δv,其中scale为变量用于控制反应的通量扰动;
13.步骤五:使用步骤四中的方法a构建基于遗传算法的最大通量变化计算方法b,用于计算每个反应所能得到的最大目标产量变化值δv
max
,以及此时的扰动量scale;
14.步骤六:使用步骤五中的方法b进行关键因子挖掘:输入代谢网络n以及目标代谢物m
t
,方法b输出反应集合r中每一个反应所对应的最大目标产量变化值,进而筛选出产量变化值最大的前k个反应也即关键因子作为结果输出,k为设定的参数。
15.具体地,
16.步骤一中的已知代谢网络n是从公共资源收集或科研人员提供的代谢网络模型,其中,代谢网络模型的存储格式为sbml。代谢网络n中包含有所有的反应集合r以及代谢物集合m。每个反应ri∈r包含有反应所对应代谢物集合mi,其中,
17.具体地,
18.所述步骤三中,fba的计算方式如下:
19.3.1初始化代谢网络,提取代谢网络中所有的反应;
20.3.2构建化学计量矩阵s,每一行代表一种代谢物,每一列代表一个反应;
21.3.3构建稳态条件下的线性方程组s
·
v=0,其中,v表示每一个反应的通量约束,对于任意反应i,其范围为[αi,βi];
[0022]
3.4定义最大化优化问题:z=c
t
v,其中,c为权重向量,z为优化目标,即反应集合r
t
所对应的最大通量;c表示反应对目标的贡献度,为0-1向量(该向量中的元素只有0、1,例如[0,1,0,
…
,1]),仅在感兴趣的反应位置为1,其余位置为0,即仅在步骤二中的反应集合r
t
所对应的c处为1;
[0023]
3.5使用线性规划法求解带约束的优化问题,得到最大目标值v。
[0024]
具体地,
[0025]
步骤四中的通量变化计算方法a对于给定的反应r以及扰动scale,具体流程如下:
[0026]
4.1使用通量变化分析(flux variability analysis,fva)计算每个反应r的通量约束[,β];
[0027]
4.2修改反应r的通量约束,令α=α
×
(1+scale),β=β
×
(1-scale),其中α≤β;
[0028]
4.3使用fba计算修改反应r的约束后代谢网络的最大目标值v
′
;
[0029]
4.4计算δv=|v-v
′
|,作为方法a的输出。
[0030]
具体地,
[0031]
所述步骤五中,基于遗传算法的最大通量变化计算方法b的步骤如下:
[0032]
5.1初始化种群pop0,设置种群规模为pop_size,设置适应度函数func为步骤四中的通量变化计算方法a,用于计算初始种群中每个个体的适应度值;
[0033]
5.2对种群进行迭代:设置迭代次数g
max
,并设置当前迭代次数g=1;若g≤g
max
,则:(1)从当前种群popg中生成新的种群pop
′g,(2)计算新种群pop
′g的适应度值obj
′g,(3)从混合种群popg∪pop
′g中选择适应度值更大的pop_size个个体加入到新的种群pop
g+1
,(4)更新g=g+1;
[0034]
5.3输出种群中的最优个体。
[0035]
更具体地,
[0036]
在5.1中,pop由个体imd组成,个体由决策变量即scale以及适应度值即目标产量变化值δv组成。即,pop={ind1,ind2,
…
,indi,
…
,ind
pop_size
},indi={scalei,δvi},其中δvi=func(scalei)。
[0037]
与现有技术相比较,本发明的有益效果在于:
[0038]
1.本发明是代谢工程领域里首个基于代谢网络的关键因子挖掘方法,能够很好的促进代谢工程领域的发展。
[0039]
2.本发明不需要复杂的参数设置,仅仅需要给定待优化的代谢模型以及需要生产的目标化合物,即可得到代谢网络中的关键因子。
[0040]
3.本文方法不需要对代谢物浓度有任何了解,不需要了解系统的酶动力学,仅使用化学计量系数就可以对特定目标化合物关键因子挖掘。
附图说明
[0041]
图1为本发明一种基于通量平衡分析的代谢网络关键因子挖掘方法流程图;
[0042]
图2为本发明中通量平衡分析计算方法流程图;
[0043]
图3为本发明中通量变化计算方法流程图;
[0044]
图4为本发明中基于遗传算法的最大通量变化计算方法流程图。
具体实施方式
[0045]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0046]
以下结合附图和实施例对本发明的技术方案作进一步描述。
[0047]
实施例1
[0048]
一种基于通量平衡分析的代谢网络关键因子挖掘方法,包括:
[0049]
步骤一:从已知代谢网络n中获取反应集合r以及代谢物集合m,给定目标代谢物m
t
,其中,m
t
∈m;
[0050]
步骤二:从反应集合r中获取所有反应产物为m
t
的反应集合r
t
,其中
[0051]
步骤三:使用通量平衡分析fba计算初始条件下反应集合r
t
的通量最大值v;
[0052]
步骤四:构建通量变化计算方法a,计算给定反应r在给定scale下的目标产量变化值δv,其中scale为变量用于控制反应的通量扰动;
[0053]
步骤五:使用步骤四的方法a构建基于遗传算法的最大通量变化计算方法b,用于计算每个反应所能得到的最大目标产量变化值δv
max
以及此时的扰动量scale;
[0054]
步骤六:使用步骤五中的方法b进行关键因子挖掘:输入代谢网络n以及目标代谢物m
t
,方法b输出反应集合r中每一个反应所对应的最大目标产量变化值,进而筛选出选择产量变化值最大的前k个反应也即关键因子作为结果输出,k为设定的参数。
[0055]
具体地,所述步骤一中,已知代谢网络n是从公共资源收集或科研人员提供的代谢网络模型,其中,代谢网络模型的存储格式为sbml。代谢网络n中包含有所有的反应集合r以及代谢物集合m。每个反应ri∈r包含有反应所对应代谢物集合mi,其中,
[0056]
具体地,所述步骤三中,fba的计算方式如下:
[0057]
3.1初始化代谢网络,提取代谢网络中所有的反应;
[0058]
3.2构建化学计量矩阵s,每一行代表一种代谢物,每一列代表一个反应;
[0059]
3.3构建稳态条件下的线性方程组s
·
v=0,其中,v表示每一个反应的通量约束,对于任意反应ri,其范围为[αi,βi];c表示反应对目标的贡献度,为0-1向量,仅在感兴趣的反应位置为1,其余位置为0,即仅在s1.2中的反应集合r
t
所对应的c处为1;
[0060]
3.4定义最大化优化问题:z=c
t
v,其中,c为权重向量,z为优化目标即反应集合r
t
所对应的最大通量;
[0061]
3.5使用线性规划法求解带约束的优化问题,得到最大目标值v。
[0062]
具体地,所述步骤四中,通量变化计算方法a对于给定的反应r以及扰动scale,具体流程如下:
[0063]
4.1使用通量变化分析fva计算每个反应r的通量约束[,β];
[0064]
4.2修改反应r的通量约束,令α=α
×
(1+scale),β=β
×
(1-scale),其中α≤β;
[0065]
4.3使用fba计算修改反应r的约束后代谢网络的最大目标值v
′
;
[0066]
4.4计算δv=|v-v
′
|,作为方法a的输出。
[0067]
具体地,所述步骤五中,基于遗传算法的最大通量变化计算方法b的步骤如下:
[0068]
5.1初始化种群pop0,设置种群规模为pop_size,设置适应度函数func为步骤四中的通量变化计算方法a,用于计算初始种群中每个个体的适应度值;
[0069]
5.2对种群进行迭代:设置迭代次数g
max
,并设置当前迭代次数g=1;若g≤g
max
,则:(1)从当前种群popg中生成新的种群pop
′g,(2)计算新种群pop
′g的适应度值obj
′g,(3)从混合种群popg∪pop
′g中选择适应度值更大的pop_size个个体加入到新的种群pop
g+1
,(4)更新g=g+1;
[0070]
5.3输出种群中的最优个体。
[0071]
更具体地,所述步骤五的5.1中,pop由个体ind组成,个体由决策变量即scale以及适应度值,即目标产量变化值δv组成。即,pop={ind1,ind2,
…
,indi,
…
,ind
pop_size
},indi={scalei,δvi},其中δvi=func(scalei)。
[0072]
更具体地,所述步骤五的5.2中,新种群pop
′g的生成方法包括轮盘法,竞争法等。
[0073]
本实施例以大肠杆菌模型ijo1366为例,其中目标产物设置为乙酰辅酶a(accoa_
c),该模型来自于公共资源数据库bigg(king za,lu js,a,miller pc,federowicz s,lerman ja,ebrahim a,palsson bo,and lewis ne.bigg models:a platform for integrating,standardizing,and sharing genome-scale models(2016)nucleic acids research 44(d1):d515-d522.doi:10.1093/nar/gkv1049)。该模型包含1805个代谢物以及2583个反应。
[0074]
本实施例采用上述的基于fba的代谢网络关键因子挖掘方法在实施例目标产物为accoa_c的情况下,计算得到的前10个关键因子如表1所示。
[0075]
表1关键因子
[0076][0077]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
[0078]
以上所述,仅为本发明较佳的具体实施方式,但本发明保护的范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内所做的任何修改,等同替换和改进等,均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1