基于Transformer-Encoder和多尺度卷积神经网络的转录因子识别方法
基于transformer-encoder和多尺度卷积神经网络的转录因子识别方法
技术领域
1.本发明涉及蛋白质功能注释领域,具体涉及一种基于transformer-encoder和多尺度卷积神经网络的转录因子识别方法,由于转录因子是一类具有特殊功能的蛋白质,所以本发明属于深度学习在蛋白质功能注释领域的应用。
背景技术:
2.转录因子(transcription factor)是一种具有特殊结构、行使调控基因表达功能的蛋白质分子。转录因子通过与dna序列特异性结合,促进或抑制特定dna到rna的转录过程,从而调节目标基因的表达。
3.传统上,通过生化实验来鉴定和识别转录因子的方法耗时、成本昂贵,无法大规模使用;采用blast的同源搜索方法无法对同数据库中已知蛋白质均不同源的蛋白质是否为转录因子进行鉴定;采用传统机器学习的预测方法可基于蛋白质结构或序列信息识别其是否为转录因子,但需要人工设计和转录因子相关的特征,需要较强的领域知识,且预测精度不高;深度学习具有可以直接学习蛋白质序列的特征的优点,但现有方法大多基于卷积神经网络构建预测模型。由于卷积核的限制,这类方法虽然可以自动学习特征表示,但只能学习距离较近的氨基酸间关系的局部特征,无法学习距离较远的氨基酸间关系的全局特征,影响了模型的预测精度。
技术实现要素:
4.针对上述技术问题,本发明提供了一种基于transformer-encoder和多尺度卷积神经网络的转录因子识别方法,可以同时提取蛋白质序列中的全局和局部信息,自动获得关于转录因子的全面表示特征,从而进一步提高预测精度。
5.本发明提供的技术方案如下:
6.一种基于transformer-encoder和多尺度卷积神经网络的转录因子识别方法,步骤如下:
7.步骤1:构建训练集:从蛋白质数据库中收集蛋白质序列,根据对应的蛋白质注释信息,将每条蛋白质序列标记为转录因子或者非转录因子;对所有序列进行预处理,得到训练数据集;
8.步骤2:搭建网络结构:搭建transformer-encoder和多尺度卷积神经网络相结合的网络结构构建转录因子预测模型;其中transformer-encoder用于获得第i条蛋白质序列xi的全局特征多尺度卷积神经网络用于基于进行转录因子预测识别;
9.步骤3:训练预测模型:用步骤1得到的训练集来训练步骤2搭建的网络,得到训练好的转录因子预测模型;
10.步骤4:转录因子预测:利用步骤3得到的预测模型,预测未知的蛋白质序列是否为转录因子,输出预测结果。
11.进一步,所述步骤1包括以下子步骤:
12.1.1从蛋白质数据库中挑选不包含非标准氨基酸即b,o,u,z的蛋白质序列,组成数据集s1;
13.1.2从s1中剔除长度超过1000的序列,仅保留长度小于或等于1000的序列;对长度小于1000的蛋白质序列,用零填充到长度为1000;最后得到蛋白质序列数据集s2;
14.1.3根据蛋白质数据库中每条蛋白质的go注释信息,将s2中的每条蛋白质序列分别赋予转录因子“1”或非转录因子“0”的标签;最终得到训练数据集s=(xi,ci)|i=1,..,n;其中xi代表数据集中第i条蛋白质序列;ci为xi的标签,ci∈{0,1};n为s的大小。
15.进一步,所述步骤1.3中,如果蛋白质的go注释中包含“transcription factor”的go term,或者同时包含“transcription regulation”和“dna binding”两个go terms,则将该蛋白质序列为转录因子,并赋值为“1”;否则,该蛋白质序列为非转录因子,并赋值为“0”。
16.进一步,所述步骤2中网络结构包括串联组成的transformer-encoder结构和多尺度卷积神经网络结构;
17.该transformer-encoder结构仅保留transformer中的encoder部分,由6个encoder块堆叠而成,每个encoder块包含12个attention head;transformer-encoder用于从输入的蛋白质序列中提取全局特征;
18.多尺度卷积神经网络由四个并联的具有不同一维卷积核的卷积子网络、两个全连接层和输出层组成;卷积层包含多个分别对应不同大小卷积核的一维卷积操作获得多个不同大小的卷积特征;池化层分别对多个卷积特征进行池化,得到维度降低后的特征;池化后特征经过拼接送入全连接层;全连接层计算后得到的预测结果由输出层输出。
19.进一步,所述步骤2中,设一个蛋白质序列为xi=x
i1
,x
i2
,
…
,x
ij
,
…
x
i1000
,x
ij
表示蛋白质序列xi中第j个位置的氨基酸,利用transformer-encoder得到xi的全局特征的具体步骤为:
20.2.1通过embedding操作,得到xi的embedding向量,embedding的具体方法如下:
21.2.1.1首先对不同的氨基酸种类进行随机初始化,然后按照对应的氨基酸类型将xi的每个氨基酸x
ij
embedding生成相应的向量;
22.2.1.2使用位置编码提取蛋白质序列中的氨基酸的位置信息,其中位置编码是通过正弦和余弦函数来识别氨基酸在蛋白质的不同位置,其中第j个氨基酸的位置编码公式如下所示:
[0023][0024]
其中,pos表示氨基酸在蛋白质序列中的位置,d表示嵌入向量的维度,k为自然数;
[0025]
2.1.3将每个氨基酸x
ij
的embedding和对应的位置编码进行相加,得到蛋白质xi序列的embedding向量;
[0026]
2.2得到蛋白质序列xi的embedding向量后,将其作为transformer-encoder的输入,利用其attention机制挖掘每两个氨基酸之间的attention分数,将attention分数与
embedding向量做叉乘,从而得到整个蛋白质序列xi的全局特征
[0027]
更进一步,所述步骤2中,所述卷积子网络依次由卷积层,归一化层,dropout层和max-pooling层组成;
[0028]
其中第i个子网络输出的计算公式为:
[0029]fi
(x)=maxpooling(relu(norm(conv(x)))
[0030]
其中,x为卷积层的输入;
[0031]
四个子网络的拼接输出为:
[0032]
ouput=concat(fi(x)),i=1,2,3,4。
[0033]
进一步,所述步骤2中,多尺度卷积神经网络使用不同size的一维卷积核,将用于提取不同长度的局部蛋白质序列之间的特征。
[0034]
更进一步,所述步骤2中,卷积核的长度和蛋白质的嵌入维度相同,宽度设置为4-20,卷积核的大小依次为4,8,12,16。
[0035]
进一步,所述步骤2中,基于进行转录因子预测识别的方法如下:
[0036]
基于蛋白质序列xi的全局特征进行不同尺度的卷积操作后得到xi的局部特征其中j为不同的卷积核对应的局部特征,随后将所有的局部特征进行拼接,最终输入全连接层,其中loss函数选择cross entropy,具体如下公式:
[0037][0038]
其中是模型预测样本是转录因子的概率,y是样本标签,如果样本属于正例,取值为1,否则取值为0;
[0039]
对于所有蛋白质序列,经过softmax函数得到最后的输出概率为[p
1j
,p
2j
,
…
,p
nj
],通过下式计算出蛋白质i的预测类别yi:
[0040][0041]
如yi=1,则表示蛋白质序列i为转录因子,反之,则为非转录因子。
[0042]
与现有技术相比较,本发明的有益效果在于:
[0043]
1.本发明使用了一种新的识别分类方法,解决了传统的生物化学实验的实验成本高,过程复杂等问题,能快速地仅依靠蛋白质序列来判断转录因子,极大地提高蛋白质标注效率。
[0044]
2.本发明在特征提取方面,对比之前学者提出方法,增加了提取序列特征地维度,从仅能提取3-16片段氨基酸序列的特征到提取整个蛋白质序列地特征,有效增加了提取到的蛋白质特征地维度,提高了转录因子的预测精度。
[0045]
3.本发明在模型中引入transformer-encoder模块,该模块可以计算了每个氨基酸和其它氨基酸之间的attention score,从而发掘蛋白质序列中氨基酸关联度较高的氨基酸对,可以更好地挖掘蛋白质序列内氨基酸之间地相互关系。
附图说明
[0046]
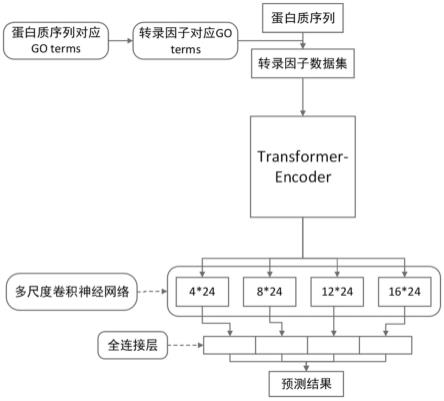
图1是本发明的模型流程图;
[0047]
图2是蛋白质数据预处理流程;
[0048]
图3是本发明中使用的transformer-encoder模型结构图;
[0049]
图4是本发明中transformer-encoder中的attention score计算流程;
[0050]
图5是本发明中的多尺度卷积神经网络模型示意图;
具体实施方式
[0051]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清除、完整的描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0052]
实施例1
[0053]
请参阅附图1-5,一种基于transformer-encoder和多尺度卷积神经网络的转录因子识别方法,包括如下步骤:
[0054]
步骤1:从uniprotkb 2021_04swiss-prot数据库中获取所有的蛋白质序列,并对数据进行预处理,构建转录因子训练集s。
[0055]
步骤1中所述的数据预处理操作,如图2所示,包含以下子步骤:
[0056]
s1.1首先在uniprotkb 2021_04swiss-prot数据集下载所有的蛋白质序列,共565,928条,数据集中的属性包含“sequence”,“length”,“gene ontology(go)”,“entry name”,“protein names”。随后从数据集中删去包含非标准氨基酸(即b,o,u,z)的异常蛋白质数据。
[0057]
s1.2然后根据“length”属性筛选出序列长度小于或等于1000的序列,再对其进行零填充到长度为1000。
[0058]
s1.3从蛋白质注释数据库收集得到含有“transcription factor”,“transcription regulation”和“dnabinding”三种功能的terms,由于go terms为蛋白质基因注释功能类别,所以其意义在于创建转录因子的标签索引,整理得到transcription factor的go terms包括“go:0000976;go:0000977;go:0000978;go:0000979;go:0000981;go:0000984;go:0000985;go:0000986;go:0000987;go:0000992”等;transcription regulation的go terms包括“go:0001228;go:0006351;go:0006355;go:0043433”等;dna binding的go terms包括“go:0003677;go:0008301;go:0043565;go:0050692”。
[0059]
s1.4对步骤(1)中获取的蛋白质序列对应的go terms进行筛选,如果该go terms包含步骤2中“transcription factor”的terms,或者同时包含“transcription regulation”和“dna binding”的terms,则将其标记为转录因子,否则将其标记为非转录因子。这样就构建了一个包含124,316条清洗和预处理后的蛋白质序列和该蛋白质的转录因子标签的数据集。
[0060]
步骤2:搭建网络模型m,搭建一个由2层8头注意力机制的transformer-encoder(如图3-4),同时构建多尺度卷积神经网络,包含kernel size分别为4,8,12,16的一维卷积核的卷积神经网络(如图5),两者串联起来构建成模型m。
[0061]
步骤2中所述的网络结构由transformer-encoder结构和多尺度卷积神经网络结构串联组成。transformer-encoder结构来自自然语言处理领域中的transformer网络结构。原始的transformer是采用encoder-decoder架构,步骤2中仅保留transformer中的encoder部分,由6个encoder块堆叠而成,每个encoder块包含12个attention head。transformer-encoder用于从输入的蛋白质序列中提取全局特征。
[0062]
多尺度卷积神经网络由四个并联的具有不同一维卷积核的卷积子网络、两个全连接层和输出层组成;卷积层包含多个分别对应不同大小卷积核的一维卷积操作获得多个不同大小的卷积特征;池化层分别对多个卷积特征进行池化,得到维度降低后的特征;池化后特征经过拼接送入全连接层;全连接层计算后得到的预测结果由输出层输出。
[0063]
设一个蛋白质序列为xi=x
i1
,x
i2
,
…
,x
ij
,
…
x
i1000
,x
ij
表示蛋白质序列xi中第j个位置的氨基酸。步骤2中利用transformer-encoder得到xi的全局特征的具体步骤为:
[0064]
2.1通过embedding操作,得到xi的embedding向量,embedding的具体方法如下:
[0065]
2.1.1首先对不同的氨基酸种类进行随机初始化,然后按照对应的氨基酸类型将xi的每个氨基酸x
ij
embedding生成相应的向量。
[0066]
2.1.2使用位置编码提取蛋白质序列中的氨基酸的位置信息,其中位置编码是通过正弦和余弦函数来识别氨基酸在蛋白质的不同位置,其中第j个氨基酸的位置编码公式如下所示:
[0067][0068]
其中,pos表示氨基酸在蛋白质序列中的位置,d表示嵌入向量的维度,k为自然数;。
[0069]
2.1.3将每个氨基酸x
ij
的embedding和对应的位置编码进行相加,得到蛋白质xi序列的embedding向量。
[0070]
2.2得到蛋白质序列xi的embedding向量后,将其作为transformer-encoder的输入,利用其attention机制挖掘每两个氨基酸之间的attention分数,将attention分数与embedding向量做叉乘,从而得到整个蛋白质序列xi的全局特征
[0071]
多尺度卷积神经网络使用不同size的一维卷积核,将用于提取不同长度的局部蛋白质序列之间的特征。积核的长度和蛋白质的嵌入维度相同,宽度设置为4-20,卷积核的大小依次为4,8,12,16。
[0072]
所述卷积子网络依次由卷积层,归一化层,dropout层和max-pooling层组成;
[0073]
其中第i个子网络输出的计算公式为:
[0074]fi
(x)=maxpooling(relu(norm(conv(x)))
[0075]
其中,x为卷积层的输入;
[0076]
四个子网络的拼接输出为:
[0077]
ouput=concat(fi(x)),i=1,2,3,4。
[0078]
基于进行转录因子预测识别的方法如下:
[0079]
基于蛋白质序列xi的全局特征进行不同尺度的卷积操作后得到xi的局部特征其中j为不同的卷积核对应的局部特征,随后将所有的局部特征进行拼接,最终输入全连接层。其中loss函数选择cross entropy,具体如下公式。
[0080][0081]
其中是模型预测样本是转录因子的概率,y是样本标签,如果样本属于正例,取值为1,否则取值为0。
[0082]
对于所有蛋白质序列,经过softmax函数得到最后的输出概率为[p
1j
,p
2j
,
…
,p
nj
],通过下式计算出蛋白质i的预测类别yi:
[0083][0084]
如yi=1,则表示蛋白质序列i为转录因子,反之,则为非转录因子。
[0085]
步骤3:用步骤1中的数据集s来训练模型m中,得到训练好的转录因子预测模型t。步骤3中所述的模型训练采用的都是随机梯度下降的方法,其特征在于采用adam优化器,初始学习率为0.0001。在训练模型的过程中,batch size的取值为20。
[0086]
步骤4:将需要进行识别的蛋白质序列输入到模型t中(如图1),得到该序列是否为转录因子的结果。
[0087]
针对转录因子预测背景技术中提及的现有方法的局限性,本发明在原有的深度学习方法的基础上进行了改进,利用transformer-encoder的全局特征提取和多尺度卷积神经网络的局部特征提取对转录因子进行识别方法,有效地提高了原有深度学习方法预测地准确度。表1显示了本发明使用transformer-encoder和多尺度卷积神经网络构成的模型与其他对比模型的性能比较,由表1结果可以看出,本文提出的方法具有最佳综合识别效果。
[0088]
表1不同方法识别效果比较
[0089]
methodaccprecrecallf1实施例10.950.920.870.89deeptfactor0.940.930.840.88gru0.800.670.450.52
[0090]
最后应说明的是,以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
[0091]
以上所述,仅为本发明较佳的具体实施方式,但本发明保护的范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内所做的任何修改,等同替换和改进等,均应包含在发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1