基于集合深度学习模型的ncRNAs家族预测方法
基于集合深度学习模型的ncrnas家族预测方法
技术领域
1.本发明涉及一种ncrnas家族的预测方法,特别涉及一种基于集合深度学习模型的ncrnas家族预测方法。
背景技术:
2.目前,随着高通量技术的迅猛发展,越来越多未知的ncrnas被发现,同时ncrnas在生命活动当中扮演着不可或缺的角色,因此研究这些未知ncrnas的功能变得十分重要。因为相同家族的ncrnas有着相似的功能,对未知的ncrnas进行家族预测可以初步预测其功能,所以正确预测每一个未知ncrnas的所属家族是必要和紧迫的。
3.现阶段ncrnas家族预测方法可以分为三个方向,通过生物手段预测ncrnas家族、通过ncrnas的二级结构特征预测ncrnas家族、通过ncrnas的序列特征预测ncrnas家族。但是以上这三种方法都存在很多问题。
4.通过生物手段预测ncrnas家族存在的问题:
5.基于生物实验的方法尽管在一些领域可以达到很高的精度,但是会花费大量的人力物力且无法满足高通量的需求。
6.通过ncrnas二级结构特征预测ncrnas家族存在的问题:
7.ncrnas的二级结构是由序列中的碱基通过氢键相互匹配形成的二维结构,ncrnas的二级结构分为多种形式,主要由螺旋和单链构成,单链又分为发卡环、内环、突环与多分支结构,因为ncrnas二级结构的多样性,导致获取ncrnas二级结构的过程复杂且准确率低。因此通过ncrnas二级结构特征预测ncrnas家族不仅耗费大量时间,还存在着预测准确率低的问题。
8.通过ncrnas序列特征预测ncrnas家族存在的问题:
9.现存通过ncrnas序列特征预测ncrnas家族的主要方法包括ncrfp和ncdlres。ncrfp方法采用静态lstm方法,对不等长的ncrnas序列采取填充或者截取的操作,导致部分ncrnas序列特征信息缺失并且增添许多无用的特征信息,使得ncrnas家族预测准确率下降。ncdlres采用动态的lstm避免了ncrnas序列特征的缺失问题,但是ncdlres在提取ncrnas序列上下文信息特征的时候采取的是单向rnn模型,而单向rnn模型只能提取当前碱基之前的碱基信息,导致特征提取不充分。
10.以上的方法都不适合解决ncrnas家族的预测问题。
技术实现要素:
11.本发明的主要目的是为了解决现有ncrnas预测方法不适合应用于大规模的ncrnas家族预测问题;
12.本发明的另一个目的是为了提高ncrnas家族预测的准确率和效率;
13.本发明为了达到上述目的、解决上述问题而提供的一种基于集合深度学习模型的ncrnas家族预测方法。
14.本发明提供的基于集合深度学习模型的ncrnas家族预测方法,其方法包括的步骤如下:
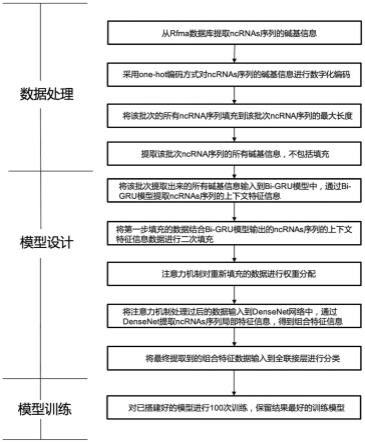
15.第一步、数据处理,具体步骤如下:
16.步骤1、从rfam数据库收集ncrnas的数据信息,收集6320条非冗余ncrnas数据,其中ires共计320条数据,其余ncrnas家族包括micrornas、5s_rrna、5.8s_rrna、ribozymes、cd-box、haca-box、scarna、trna、intron_gpi、intron_gpii、leader和riboswitch各500条数据;
17.步骤2、将ncrnas序列输入到集合深度学习模型中,采用one-hot编码将每一个ncrnas的碱基编码为1*8的数据,a腺嘌呤、u尿嘧啶、g鸟嘌呤和c胞嘧啶是四种常见的ncrnas的碱基,one-hot的编码规则为a-10000010、u-00101000、c-00010100、g-01000001、n-00000000,“n”代表一些稀有碱基,每一个ncrnas序列编码之后的长度为l*8,l为ncrnas序列中碱基的数量;
18.步骤3、在模型训练过程中采用十折交叉验证方法,因此将每个家族的ncrnas数据均分为十份,轮流将其中九份作为训练集剩余一份作为测试集;
19.第二步、模型设计
20.模型设计包括了三种网络模型和一种注意力机制,三种网络模型分别为bi-gru循环神经网络、densenet卷积神经网络和全联接神经网络,bi-gru循环神经网络用于提取ncrnas序列的上下文特征信息,densenet卷积神经网络用于提取ncrnas序列的局部特征,全联接神经网络根据组合特征进行分类预测,注意力机制为attention mechanism,attentionmechanism通过给bi-gru提取出来的特征分配不同的权重,将注意力进行调整转移进而忽略不相关信息,放大重要信息,模型设计具体步骤如下:
21.步骤1、使用动态bi-gru模型提取ncrnas序列的上下文特征信息,具体如下:
22.将ncrnas序列中所有经过数据处理过后的碱基信息提取出来并输入到bi-gru模型中,设置bi-gru模型中的隐藏层单元为512,最终输出结果的维度为(n,1024),n为每一批次中所有ncrnas的碱基数量,设置两个gru单元,每个gru单元的计算公式如下:
23.1)、重置门计算公式:r
t
=σ(w
ir
·
x
t
+b
ir
+w
hr
·ht-1
+b
nr
);
24.2)、更新门计算公式:z
t
=σ(w
iz
·
x
t
+b
iz
+w
hz
·ht-1
+b
hz
);
25.3)、重置当前记忆内容:
26.4)、计算gru的输出:
27.w
ir
、w
iz
、w
hr
、w
hz
、w
it
、w
ht
表示模型中能够学习的权重矩阵,b
ir
、b
hr
、b
iz
、b
hz
、b
it
、b
ht
表示模型中的偏差;
28.重置门决定了如何将新输入的信息与前面的信息相结合,重置门的值越大代表需要记住上一刻的信息越多,新输入的信息x
t
与前面的记忆h
t-1
结合的越多,相反重置门的值越小代表需要记住上一刻的信息越少,新输入的信息x
t
与前面的记忆h
t-1
结合的越少;
29.更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越接近1,代表新输入的信息留下来的数据越多,而越接近0则代表新输入的信息遗忘的越多;
30.步骤2、引入注意力机制,获取关键信息,进一步优化模型,公式如下:
[0031][0032]
将bi-gru模型提取到的ncrnas序列特征加入注意力机制,c是注意力机制输出结果、lx是输入ncrnas序列的长度、a是第j个隐藏状态分配的系数、h是第j个隐藏状态,注意力机制的核心思想是给重要的输入信息分配更大的权重,从而将注意力进行调整转移进而忽略不相关信息,放大重要信息,如此,聚焦注意区域中的信息接收灵敏度和处理速度大大提高,相同家族的ncrnas序列有着相似的序列,只需将模型放在这些序列上就能对ncrnas进行分类,因此注意力机制能够很好的应用在ncrnas家族预测上;
[0033]
步骤3、使用densenet网络来提取ncrnas序列的局部特征信息,具体如下:
[0034]
1)、将bi-gru卷积神经网络和attention mechanism注意力机制处理过后的特征数据进行填充和重塑,分为32个32*32*1大小的数据集;
[0035]
2)、将处理好的数据集输入到卷积核为3*3的卷积网络中,得到32个数据集大小为32*32*64的数据;
[0036]
3)、将卷积网络处理过后的数据输入到一个denseblock中,densenet网络模型采用了4层的denseblock,每一个denseblock共有十个连接,每一层的denseblock的计算公式如下:
[0037]
xi=h([x1,x2,x3……
x
i-1
])
[0038]
h采用的是bn+relu+3*3conv的结构,最后输出32个数据集大小为32*32*196的数据;
[0039]
4)、将denseblock处理过后的数据输入到transition层中,每一个transition层包括一个卷积层和一个平均池化层,transition层的主要作用是降低数据维度,得到32个数据集大小为16*16*196的数据;
[0040]
5)、接下来将得到的数据经过一个denseblock和一个transition层得到32个数据集大小为8*8*122的数据,继续将数据输入到一个denseblock和一个transition层得到32个数据集大小为4*4*120的数据;
[0041]
6)、将得到的数据输入到一个denseblock和一个平均池化层,最后得到32个数据集大小为1*1*248的数据,将32个数据集合并后得到一个大小为32*248的数据集;
[0042]
步骤4、使用全联接层进行分类,具体如下:
[0043]
ncrnas序列的碱基信息经过bi—gru提取ncrnas序列的上下文特征信息、attention mechanism注意力机制放大重要的特征信息、densenet提取ncrnas序列局部特征信息,最终得到了一个32*248组合特征的数据集,接下来将得到的数据集输入到全联接神经网络进行分类得到分类结果的概率值,最后经过sigmoid函数得到32个ncrnas预测结果;
[0044]
第三步、模型训练,具体如下:
[0045]
模型训练选择远程服务器作为实验设备,远程服务器的操作系统是64位linux系统,系统版本为“ubuntu16.04.4lts”,cpu为intel i78750k,gpu为1080ti,内存为16gb,深度学习单元批次读入ncrnas序列中的碱基信息和标签数据,每批次包含32个ncrnas序列,对已搭建好的模型进行100次训练,保留结果最好的训练模型,采用十折交叉验证方法将每个家族的ncrnas数据均分为十份,轮流将其中九份作为训练集剩余一份作为测试集,最后
结果取平均值。
[0046]
本发明的有益效果:
[0047]
本发明提供的基于集合深度学习模型的ncrnas家族预测方法通过提取ncrnas的序列特征来对ncrnas家族进行预测,跳过了获取ncrnas二级结构的过程,使得ncrnas家族预测的准确率提高并且简化了预测过程;本发明摒弃了传统对ncrnas序列的填充和分割,使得ncrnas序列的全部特征可以输入到bi-gru模型之中,提升了ncrnas家族预测的准确率;本发明采用了双向的rnn模型bi-gru,相比较于单向的rnn模型,不仅能够保留当前碱基之前的碱基信息还可以记录当前碱基信息之后的碱基信息,能够更好的提取ncrnas序列的上下文特征信息;本发明采用densenet的网络来提取ncrnas序列局部特征信息,通过密集连接可以更好的缓解深层网络反向传播的梯度消失。
附图说明
[0048]
图1为本发明所述的ncrnas家族预测方法的流程示意图。
[0049]
图2为本发明所述的ncrnas家族预测方法的模型示意图。
[0050]
图3为本发明所述的bi-gru的模型示意图。
具体实施方式
[0051]
请参阅图1至图3所示:
[0052]
本发明提供的基于集合深度学习模型的ncrna家族预测方法,其方法包括的步骤如下:
[0053]
第一步、数据处理,具体步骤如下:
[0054]
步骤1、从rfam数据库收集ncrnas的数据信息,共收集到6320条非冗余ncrnas数据,其中ires共计320条数据,其余ncrnas家族包括micrornas、5s_rrna、5.8s_rrna、ribozymes、cd-box、haca-box、scarna、trna、intron_gpi、intron_gpii、leader和riboswitch各500条数据。
[0055]
步骤2、为了将ncrnas序列输入到集合深度学习模型中,本文采用one-hot编码将每一个ncrnas的碱基编码为1*8的数据。a(腺嘌呤)、u(尿嘧啶)、g(鸟嘌呤)和c(胞嘧啶)是四种常见的ncrnas的碱基,one-hot的编码规则为a-10000010、u-00101000、c-00010100、g-01000001、n-00000000,“n”代表一些稀有碱基,每一个ncrnas序列编码之后的长度为l*8(l为ncrnas序列中碱基的数量)
[0056]
步骤3、本发明在模型训练过程中采用十折交叉验证方法,因此将每个家族的ncrnas数据均分为十份,轮流将其中九份作为训练集剩余一份作为测试集。
[0057]
第二步、模型设计
[0058]
本发明的模型设计包括了三种网络模型和一种注意力机制。三种网络模型分别为bi-gru循环神经网络、densenet卷积神经网络、全联接神经网络,bi-gru循环神经网络用于提取ncrnas序列的上下文特征信息,densenet卷积神经网络用于提取ncrnas序列的局部特征,全联接神经网络根据组合特征进行分类预测。注意力机制为attention mechanism,attentionmechanism通过给bi-gru提取出来的特征分配不同的权重,从而巧妙、合理地将注意力进行调整转移进而忽略不相关信息,放大重要信息。模型设计具体步骤如下:
[0059]
步骤1、使用动态bi-gru模型提取ncrnas序列的上下文特征信息,具体如下:
[0060]
将ncrnas序列中所有经过数据处理过后的碱基信息提取出来并输入到bi-gru模型中,设置bi-gru模型中的隐藏层单元为512,最终输出结果的维度为(n,1024),n为每一批次中所有ncrnas的碱基数量。设置两个gru单元,每个gru单元的计算公式如下:
[0061]
1)、重置门计算公式:r
t
=σ(w
ir
·
x
t
+b
ir
+w
hr
·ht-1
+b
hr
);
[0062]
2)、更新门计算公式:z
t
=σ(w
iz
·
x
t
+b
iz
+w
hz
·ht-1
+b
hz
);
[0063]
3)、重置当前记忆内容:
[0064]
4)、计算gru的输出:
[0065]wir
、w
iz
、w
hr
、w
hz
、w
it
、w
ht
表示模型中能够学习的权重矩阵,b
ir
、b
hr
、b
iz
、b
hz
、b
it
、b
ht
表示模型中的偏差;
[0066]
重置门决定了如何将新输入的信息与前面的信息相结合,重置门的值越大代表需要记住上一刻的信息越多,新输入的信息(x
t
)与前面的记忆(h
t-1
)结合的越多。相反重置门的值越小代表需要记住上一刻的信息越少,新输入的信息(x
t
)与前面的记忆(h
t-1
)结合的越少。
[0067]
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越接近1,代表新输入的信息留下来的数据越多,而越接近0则代表新输入的信息遗忘的越多。
[0068]
步骤2、引入注意力机制,获取关键信息,进一步优化模型,公式如下:
[0069][0070]
将bi-gru模型提取到的ncrnas序列特征加入注意力机制,c是注意力机制输出结果、lx是输入ncrna序列的长度、a是第j个隐藏状态分配的系数、h是第j个隐藏状态,注意力机制的核心思想是给重要的输入信息分配更大的权重,从而将注意力进行调整转移进而忽略不相关信息,放大重要信息,如此,聚焦注意区域中的信息接收灵敏度和处理速度大大提高,相同家族的ncrnas序列有着相似的序列,只需将模型放在这些序列上就能对ncrnas进行分类,因此注意力机制能够很好的应用在ncrnas家族预测上;
[0071]
步骤3、使用densenet网络来提取ncrnas序列的局部特征信息,具体如下:
[0072]
1)、将bi-gru卷积神经网络和attention mechanism注意力机制处理过后的特征数据进行填充和重塑,分为32个32*32*1大小的数据集;
[0073]
2)、将处理好的数据集输入到卷积核为3*3的卷积网络中,得到32个数据集大小为32*32*64的数据;
[0074]
3)、将卷积网络处理过后的数据输入到一个denseblock中,densenet网络模型采用了4层的denseblock,每一个denseblock共有十个连接,每一层的denseblock的计算公式如下:
[0075]
xi=h([x1,x2,x3……
x
i-1
])
[0076]
h采用的是bn+relu+3*3conv的结构,最后输出32个数据集大小为32*32*196的数据;
[0077]
4)、将denseblock处理过后的数据输入到transition层中,每一个transition层包括一个卷积层和一个平均池化层,transition层的主要作用是降低数据维度,得到32个
数据集大小为16*16*196的数据;
[0078]
5)、接下来将得到的数据经过一个denseblock和一个transition层得到32个数据集大小为8*8*122的数据,继续将数据输入到一个denseblock和一个transition层得到32个数据集大小为4*4*120的数据;
[0079]
6)、将得到的数据输入到一个denseblock和一个平均池化层,最后得到32个数据集大小为1*1*248的数据,将32个数据集合并后得到一个大小为32*248的数据集;
[0080]
步骤4、使用全联接层进行分类,具体如下:
[0081]
ncrnas序列的碱基信息经过bi—gru提取ncrnas序列的上下文特征信息、attention mechanism注意力机制放大重要的特征信息、densenet提取ncrnas序列局部特征信息,最终得到了一个32*248组合特征的数据集,接下来将得到的数据集输入到全联接神经网络进行分类得到分类结果的概率值,最后经过sigmoid函数得到32个ncrnas预测结果;
[0082]
第三步、模型训练,具体如下:
[0083]
模型训练选择远程服务器作为实验设备,远程服务器的操作系统是64位linux系统,系统版本为“ubuntu16.04.4lts”,cpu为intel i78750k,gpu为1080ti,内存为16gb,深度学习单元批次读入ncrnas序列中的碱基信息和标签数据,每批次包含32个ncrnas序列,对已搭建好的模型进行100次训练,保留结果最好的训练模型。采用十折交叉验证方法将每个家族的ncrnas数据均分为十份,轮流将其中九份作为训练集剩余一份作为测试集,最后结果取平均值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1