克隆性新抗原的鉴定及其用途的制作方法
本公开内容涉及用于确定肿瘤特异性突变是否可能是克隆性的,以及用于鉴定来源于在肿瘤中存在的肿瘤特异性突变的克隆性新抗原的方法。本公开内容还涉及利用或靶向经鉴定的克隆性新抗原的用于治疗癌症的方法和组合物。
背景技术:
1、癌细胞已知可获得突变,其中的一些突变可赋予进化优势。作为结果,肿瘤通常包含多个基因型不同的相关群体(或克隆)。表征肿瘤的克隆性组成在治疗背景下是特别重要的。事实上,靶向仅在肿瘤细胞群体的亚群中存在的突变(也称为“亚克隆性”突变)可与有限的临床益处(因为该治疗仅靶向部分群体)和复发或转移的高可能性(因为未受影响的克隆仍然能够增殖)相关。相反,越来越认为靶向克隆性新抗原(作为突变存在的结果表达的抗原,其存在于所有肿瘤细胞中)或组合多种靶向治疗可以是有效控制肿瘤所必需的(mcgranahan et al.,2015)。另外,克隆性新抗原负荷已知与至少一些癌症中的预后,以及对用检查点抑制剂治疗的敏感性相关(mcgranahan et al.,2016;litchfield et al.,2021)。
技术实现思路
1、本发明人已开发了用于确定肿瘤特异性突变是否可能是克隆性的新方法,所述方法使用来自包含肿瘤细胞或来源于其的遗传物质的一个或更多个样品的序列数据,所述方法解决了现有技术方法的一个或更多个问题。该方法在鉴定克隆性新抗原中具有特别用途,例如出于癌症治疗或预后的目的。所述方法使用了严格的统计框架以将个体突变分类为克隆性的,并且提供了反映分配中置信度的概率。所述方法是快速的、灵活的、稳健的和可复制的,依赖于可解释的假设,可灵活并入体细胞拷贝数畸变数据,并且可在提供其预测时考虑由于多重倍性/纯度解导致的拷贝数调用中的不确定性。
2、因此,根据第一方面,提供了在对象中确定肿瘤特异性突变是否可能是克隆性的方法,所述方法包括:提供或获得来自对象的包含肿瘤遗传物质的一个或更多个样品的序列数据,所述序列数据针对一个或更多个样品中的每一个包含以下中的至少两者:所述样品中显示所述肿瘤特异性突变的的读出数目(db)、所述样品中显示相应种系等位基因的读出数目、和在所述肿瘤特异性突变的位置的读出总数目(d);以及作为后验概率确定所述肿瘤特异性突变为克隆性的可能性,该后验概率取决于:所述突变为克隆性的先验概率,和在所述肿瘤特异性突变是(i)克隆性的或(ii)非克隆性的情况下,鉴于一个或更多个样品中每一个的肿瘤分数和一个或更多个候选联合基因型而观察到所述序列数据的概率,所述一个或更多个候选联合基因型各自包含以下群体在所述肿瘤特异性突变位置的基因型:正常群体、不包含所述肿瘤特异性突变的参考肿瘤群体和包含所述肿瘤特异性突变的变体肿瘤细胞群体。
3、所述方法获得了突变为克隆性的概率(p(z=1))作为后验概率(p(z=1|db,d,π,t,ρ)),其取决于突变为克隆性的先验概率(ρ)和观察到所述序列数据的概率(也称为观察到所述序列数据的“可能性”,或简称为所述序列数据的“可能性”)。因此,其可针对任何突变简单地使用与正在研究的突变相关的所述序列数据来单独获得,并产生依赖于明确假设的容易解释的输出值(即突变为克隆性的先验概率,以及鉴于群体结构的明确模型而观察到所述序列数据的可能性)。换句话说,这样的概率取决于可通过由可检查的严格假设组强调的贝叶斯(bayesian)框架从以下二者中获得的数据:包含肿瘤遗传物质的一个或更多个样品和任何可获得的先验知识。该输出值可用于比较任何数目的突变,例如将任何数目的突变划分优先顺序,这不需要覆盖整个基因组。该输出值还具有组合来自包含肿瘤遗传物质的多个样品的证据的能力,但可使用包含肿瘤遗传物质的单个样品来等同地确定。
4、本方面的方法可具有以下特征中的一个或更多个。
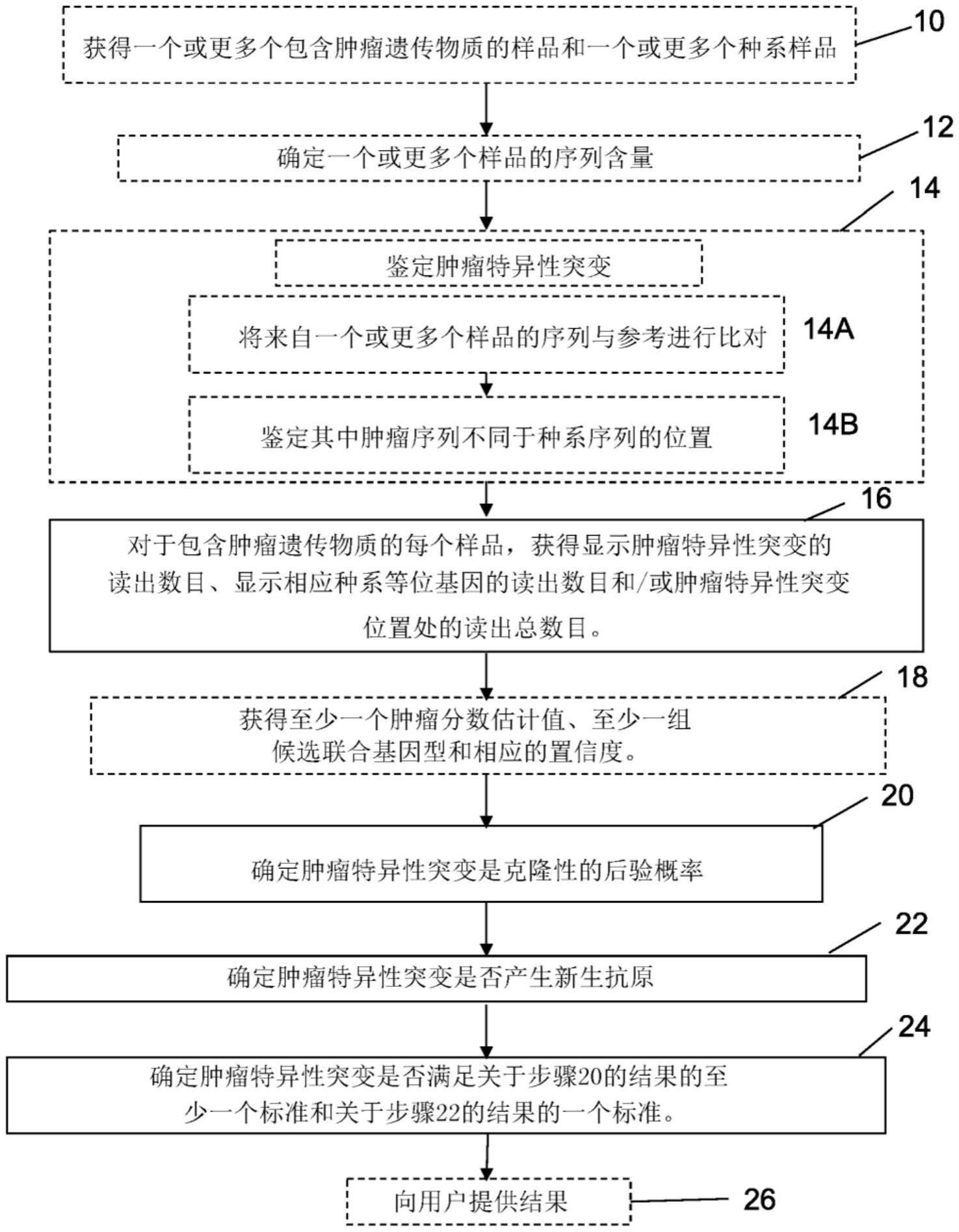
5、所述方法可以是计算机实现的。因此,获得序列数据的步骤可通过处理器进行,并且确定肿瘤特异性突变为克隆性的可能性的步骤可由所述处理器进行。获得序列数据的步骤可包括接收包含来自对象的一个或更多个样品的序列读出的序列数据,以及从所述序列读出中确定以下中的至少两者:样品中显示肿瘤特异性突变的读出数目(db)、样品中显示相应种系等位基因的读出数目和在肿瘤特异性突变位置的读出总数目(d)。至少确定肿瘤特异性突变为克隆性的可能性的步骤可以是计算机实现的。确定肿瘤特异性突变为克隆性的可能性的步骤可包括以下步骤:数值积分,以获得后验概率。特别地,该步骤可包括确定突变为克隆性的后验概率,这鉴于突变为克隆性的先验概率,和在肿瘤特异性突变是(i)克隆性的或(ii)非克隆性的情况下,观察到序列数据的概率,这是通过求解多个一维积分(例如,如针对每个样品的积分对,分别表示突变为克隆性和非克隆性的假设)将在0和1之间的所有可能的癌细胞分数内的所观察的序列数据的概率积分进行的。这些数值积分可针对每个样品和每个突变独立(例如,如并行)求解。提供的步骤可包括一个或更多个步骤,其中全部或一些步骤是计算机实现的。
6、肿瘤特异性突变为克隆性的概率可取决于突变为克隆性的先验概率(ρ),其通过以下:在鉴于突变为克隆性的先验概率的情况下,突变被分配至克隆性类别的先验概率(p(z=1|ρ)=ρ);以及在突变为克隆性的先验概率的情况下,突变被分配至非克隆性类别的先验概率(p(z=0|ρ)=(1-ρ))。如果肿瘤特异性突变为克隆性的(鉴于一个或更多个样品中每一个的肿瘤分数和一个或更多个候选联合基因型),则观察到序列数据的概率可在癌细胞分数内被边缘化。类似地,如果肿瘤特异性突变不是克隆性的,鉴于一个或更多个样品中每一个的肿瘤分数和一个或更多个候选联合基因型,则观察到序列数据的概率可在癌细胞分数内被边缘化。
7、肿瘤特异性突变为克隆性的概率可取决于:在突变为克隆性的先验概率的情况下,突变被分配至克隆性类别的先验概率(p(z=1|ρ)=ρ),乘以在每个样品中鉴于肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率,如果突变为克隆性的(其可被计算为ψ1,每个样品中序列数据的可能性,在癌细胞分数内被边缘化);以及在突变是亚克隆性的先验概率的情况下,突变被分配至非克隆性类别的先验概率(p(z=0|ρ)=1-ρ)乘以鉴于肿瘤分数和一个或更多个候选联合基因型在每个样品中观察到序列数据的概率,如果突变为非克隆性的(其可被计算为ψ0,每个样品中序列数据的可能性,在癌细胞分数内被边缘化)。
8、肿瘤特异性突变为克隆性的概率可作为以下之比获得:(i)在突变为克隆性的先验概率的情况下,突变被分配至克隆性类别的先验概率乘以在每个样品中鉴于肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率,如果突变为克隆性的(p(db,d,z=1|π,t,ρ),其可被表示为ρψ1),除以(ii)以下的总和:(i)(即p(db,d,z=1|π,t,ρ))和在突变是亚克隆性的先验概率的情况下,突变被分配至非克隆性类别的先验概率乘以鉴于在每个样品中的肿瘤分数和一个或更多个候选联合基因型在每个样品中观察到序列数据的概率,如果突变为非克隆性的(p(db,d,z=0|π,t,ρ),其可被表示为(1-ρ)ψ0)。
9、突变为克隆性的概率可使用等式(11a)来获得。在等式(11a)中,项pr(db,d|π,φ,t)可由等式(3)、(4)、(3a)、(4a)、(3b)或(4b)中的任一个给出。在等式(11)中,项p(φ|z=0)和p(φ|z=1)可由等式(6)给出。
10、克隆性突变可以是存在于来自对象的包含肿瘤遗传物质的一个或更多个样品中的所有或基本上所有肿瘤细胞中(或者一个或更多个样品中的所有肿瘤遗传物质中)的突变。这样的突变可在对象的所有肿瘤细胞中存在或可假设在对象的所有肿瘤细胞中存在(因为这方面的完全确定性可与对象中所有肿瘤细胞的测序相关,但在一个或更多个样品中的基本上所有细胞中的存在可用作这方面的指示)。
11、鉴于每个样品中的肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率可取决于鉴于肿瘤分数、癌细胞分数和一个或更多个候选联合基因型而观察到序列数据的概率(pr(d,db|π,φ,t))。鉴于肿瘤分数、癌细胞分数和一个或更多个候选联合基因型而观察到序列数据的概率可以是鉴于肿瘤分数、癌细胞分数、和一个或更多个候选联合基因型中的每一个而观察到序列数据的概率的加权和。
12、有利地,观察到序列数据的概率(序列数据的可能性)可在多个候选基因型上计算(例如,作为包含针对每个候选基因型的项的概率总和,参见例如等式(3a)、(3b)),其贡献可以被加权,例如以反映关于候选基因型的相对概率的先验知识(例如一些基因型是否比另一些基因型更可能发生的任何先验知识)。当这样的先验知识不是可用的或期望的时,每个候选基因型的概率可被同等地加权。考虑的各个候选基因型的权重合适地相加为1,使得总概率反映所考虑的不同候选联合基因型的相对贡献。当使用单个候选联合基因型时,可将其权重分配为1(即不可获得总和)。
13、鉴于肿瘤分数、癌细胞分数和特定候选联合基因型(gi)而观察到序列数据的概率(其可以被计算为ψz,每个样品中序列数据的可能性,在癌细胞分数内边缘化)可使用具有参数db和ξ(gi,φ,t)的二项分布获得。或者,鉴于肿瘤分数、癌细胞分数和特定候选联合基因型而观察到序列数据的概率可使用具有参数db、ξ(gi,φ,t)、和γ的β二项分布获得。在两种情况下(即无论使用二项分布还是β二项分布),假设特定基因型gi、癌细胞分数φ和肿瘤纯度t,ξ(gi,φ,t)可表示用变体等位基因对读出进行取样的概率。概率ξ(gi,φ,t)可作为以下的函数获得:针对正常基因型、变体基因型和参考基因型中的每种的总拷贝数,用来自具有基因型gi的群体中的变体对读出进行取样的概率,其鉴于以下:基因型中的基因座处是变体的等位基因的比例和测序错误率,样品中的肿瘤分数,和突变的癌细胞分数。
14、鉴于每个样品中的肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率可对每个样品中癌细胞分数的所有可能值进行积分来获得,其中癌细胞分数是包含肿瘤特异性突变的肿瘤细胞的比例。因此,确定肿瘤特异性突变为克隆性的可能性的步骤可包括使用处理器以将所述积分进行数值积分。
15、癌细胞分数(φ)可取0和1之间的值。换句话说,在突变为克隆性的或非克隆性的情况下,鉴于每个样品中的肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率可通过在癌细胞分数的所有可能值上将取决于癌细胞分数的值进行积分(即,在癌细胞分数内边缘化)来获得。取决于癌细胞分数的值可表示为pr(db,d|π,φ,t)=p(φ|z=z),其中第一项是鉴于肿瘤分数、癌细胞分数和一个或更多个候选联合基因型而观察到序列数据的概率,并且在突变被分类为克隆性的或非克隆性的(分别为z=1或z=0)的情况下,第二项是癌细胞分数的先验概率(即基于癌细胞分数对克隆性/非克隆性突变应如何表现的假设的概率)。因此,鉴于每个样品中的肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率可作为获得。
16、如果突变被分类为克隆性的,则特定癌细胞分数的先验概率可定义为具有参数α(设置为>1的值,例如99,但也可使用任何其他值)和β=1的β分布(β(φ|α,1))。如果突变被分类为非克隆性的,则特定癌细胞分数的先验概率可定义为具有参数α=1和β=1的β分布(β(φ|1,1))。
17、可获得来自多个样品的序列数据并且鉴于多个样品中每一个的肿瘤分数和一个或更多个候选联合基因型而观察到序列数据的概率可作为鉴于相应样品中的肿瘤分数和所述一个或更多个候选联合基因型而观察到序列数据的概率的乘积而获得。
18、有利地,本方法能够无缝集成获自多个样品的支持/反对(for/against)突变克隆性的证据,如果这些证据是可用的。这是特别有利的,因为可利用多区域测序数据的用于推断肿瘤细胞群体的克隆性结构的方法已表明在基准研究中表现得特别好(farahani etal.,2017)。
19、所述方法还可包括针对每个样品获得或提供肿瘤分数的至少一个估计值,以及一个或更多个候选联合基因型的至少一个相应组。肿瘤分数估计值可使用用于确定包含肿瘤和正常细胞的混合物的样品中的等位基因特异性拷贝数谱的方法来获得。使用测序或阵列数据来进行其的方法在本领域中是已知的,例如通过将等位基因特异性数据表达为参数(包括等位基因特异性拷贝数、肿瘤非整倍体和肿瘤细胞分数)的函数,并确定最佳拟合所有数据的这些参数的值来进行。这样的方法的实例包括例如ascat(van loo et al.,2010)等。或者,可实验性地确定肿瘤分数估计值。因此,所述方法还可包括获得针对一个或更多个样品中每一个的肿瘤分数估计值。特别地,所述方法可包括通过处理器获得针对每个样品的肿瘤分数的至少一个估计值,其包括使用序列数据确定等位基因特异性拷贝数和肿瘤分数的估计值的处理器,以及通过所述处理器确定的与所述等位基因特异性拷贝数相关的一个或更多个候选联合基因型的组。
20、一个或更多个候选基因型的组可使用混合样品中针对肿瘤细胞的等位基因特异性拷贝数或来源于其的变量(或者相反地,这样的等位基因特异性拷贝数可来源于的变量,例如b等位基因分数和log r)来获得。混合样品中肿瘤细胞的等位基因特异性拷贝数可使用用于确定包含肿瘤和正常细胞的混合物的样品中等位基因特异性拷贝数谱的方法例如,如ascat(van loo et al.,2010)或ascatngs(raine et al.,2016)等来获得。
21、因此,所述方法还可包括针对一个或更多个样品的每个获得以下中至少两者的估计值:样品中肿瘤细胞中主要等位基因的拷贝数、样品中肿瘤细胞中次要等位基因的拷贝数和样品中肿瘤细胞中肿瘤特异性突变位置处的总拷贝数。样品中肿瘤细胞中拷贝数的估计值可表示样品中在肿瘤细胞的整个群体中汇总的(例如平均值)估计值。
22、一个或更多个候选联合基因型的组可作为与以下假设相容的候选联合基因型获得:仅包含正常等位基因a的正常群体(即gh=aa或a,例如,如果基因座在性染色体上);不包含变体等位基因b的参考群体(即gr=(a)*n);以及包含至少一个拷贝的变体等位基因b的变体群体(即gv=(a)*m(b)*|)。
23、有利地,候选基因型的组可包括还与以下假设之一相容的候选联合基因型:(i)参考群体基因型与正常群体基因型匹配,并且变体群体的拷贝数等于该位置的总拷贝数并且最高至变体等位基因的主要拷贝数(major copy number);或(ii)参考群体的拷贝数等于该位置的总拷贝数,并且变体群体具有1个变体等位基因并且变体群体的拷贝数等于该位置总拷贝数(“主要拷贝数优先”)。该方法有利地在考虑群体的基因型中的不确定性而不考虑太多情况之间取得了良好的平衡。
24、相反或除此之外,一个或更多个候选联合基因型的组可包括与以下假设相容的任何候选联合基因型:每个突变都是二倍体和杂合的(即gv=ab,gr=aa)(“ab优先”)。相反或除此之外,一个或更多个候选联合基因型的组可包括与以下假设相容的任何候选联合基因型:每个突变都是二倍体和纯合的(即gv=bb,gr=aa)(“bb优先”)。相反或除此之外,一个或更多个候选联合基因型的组可包括与以下假设相容的任何候选联合基因型:变体群体的基因型在突变区域具有预测的总拷贝数,仅具有一个突变体等位基因(即gv=(a)*mb,其中m=总拷贝数-1)(“无接合性优先(no zygosity prior)”)。相反或除此之外,一个或更多个候选联合基因型的组可包括与以下假设相容的任何候选联合基因型:变体群体的基因型在突变区域具有预测的总拷贝数,具有至少一个突变体等位基因,并且参考群体是aa或基因型的拷贝数等于预测的总拷贝数并且没有变体等位基因(即gr=(a)*n,其中n是总拷贝数,gv=(a)*m(b)*l,其中m+i=n且i>1)(“总拷贝数优先”)。相反或除此之外,一个或更多个候选联合基因型的组可包括与以下假设相容的任何候选联合基因型:变体群体的基因型之突变体等位基因的数目对应于主要拷贝数或次要拷贝数(“亲本模式”)。
25、观察到序列数据的概率可与鉴于一个或更多个样品中至少一个样品的各自的肿瘤分数和一个或更多个候选联合基因型的相应组而观察到序列数据的多个概率合并,任选地,其中所述方法包括针对至少一个或者一个或更多个样品获得肿瘤分数的多个估计值和一个或更多个候选联合基因型的多个相应组。因此,所述方法可包括针对至少一个样品获得肿瘤分数的多个估计值。这可包括通过处理器确定肿瘤分数和与序列数据相容的相应多个等位基因特异性拷贝数的多个估计值,以及通过处理器确定与所述多个等位基因特异性拷贝数相关的一个或更多个候选联合基因型的多个组。
26、本方法有利地能够确定突变为克隆性的概率,这考虑了多个可能的肿瘤分数和候选联合基因型的相应组。换句话说,本方法能够获得突变为克隆性的概率,这在可获得肿瘤分数和候选联合基因型的多个拷贝数解内进行积分。相比之下,现有技术方法通常依赖于以下的单一估计值:肿瘤纯度和等位基因特异性拷贝数(可从中获得候选联合基因型),其通常是根据专家定义的最佳标准人工选择的。选择被认为是最佳的拷贝数解的步骤是高度易错的,并且依赖于单一解的方法的输出值可能根据解显著变化。
27、因此,有利地,观察到序列数据的概率(序列数据的可能性)可在多组候选基因型和相应的肿瘤分数估计值中计算(例如,作为包含针对每个拷贝数解的项的概率的总和,参见等式(3b)、(4b)),其贡献可被加权,例如以反映获得肿瘤分数估计值和候选基因型的组之拷贝数解中的置信度。考虑的拷贝数解的贡献的权重合适地相加为1,使得总概率反映考虑的不同拷贝数解的相对贡献。当使用单一拷贝数解时,可将其权重分配为1(即不可获得总和)。
28、突变为克隆性的先验概率可被设置为中性先验,或者被设置为来源于先验数据和/或专业知识的值。有利地,本文中所述的方法能够在用于确定突变为克隆性的概率的贝叶斯框架中考虑关于突变的先验知识,如果这样的知识是可用的。然而,即使在不存在这样的知识的情况下,其也能够提供突变为克隆性的可能性。
29、针对突变为克隆性的先验概率的值可取决于对象、肿瘤、突变或这些的组合。例如,值可使用先前获得的关于相关组群的患者(例如,如患有相同类型癌症或癌症亚型的患者)的数据来确定。例如,在这样的组群中的克隆性vs.亚克隆性的突变的比例的知识可用于设置本文中使用的先验概率。或者,值可基于关于癌症类型或突变的先验知识来任意设置。例如,已在多个癌症样品中发现并且已在这些样品中被鉴定为通常是克隆性的特定突变可被分配高于0.5的概率。
30、所述方法还可包括重复用于在对象中鉴定多个肿瘤特异性突变的方法。所述方法还可包括至少部分基于所确定的多个肿瘤特异性突变在对象中为克隆性的可能性来对所述多个肿瘤特异性突变进行排序或以其他方式划分优先顺序。
31、所述方法还可包括在对象中鉴定一个或更多个肿瘤特异性突变。在对象中鉴定一个或更多个肿瘤特异性突变可使用来自对象的包含肿瘤遗传物质的一个或更多个样品的序列数据和来自对象的一个或更多个种系样品的序列数据例如通过比较所述序列数据来进行。在对象中鉴定一个或更多个肿瘤特异性突变可包括将来自至少一个包含肿瘤遗传物质的样品的序列数据与参考序列比对以及鉴定样品的序列不同于参考序列的位置。所述方法还可包括将来自至少一个种系的样品的序列数据与参考序列比对以及鉴定包含肿瘤遗传物质的样品的序列不同于种系样品的位置。
32、提供来自对象的一个或更多个样品的序列数据的步骤可包括从用户(例如通过用户界面)、从一个或更多个计算装置或者从一个或更多个数据存储器或数据库接收序列数据,或由从用户(例如通过用户界面)、从一个或更多个计算装置或者从一个或更多个数据存储器或数据库接收序列数据组成。
33、提供序列数据的步骤还可包括对来自对象的包含肿瘤遗传物质的一个或更多个样品进行测序(或以其他方式确定样品中存在的基因组物质的序列组成)。
34、所述方法还可包括对来自对象的一个或更多个种系样品进行测序(或以其他方式确定样品中存在的基因组物质的序列组成)。
35、所述方法还可包括从对象获得一个或更多个包含肿瘤遗传物质的样品以及任选的一个或更多个种系样品。
36、所述方法还可包括向用户提供所确定的肿瘤特异性突变为克隆性的概率和/或者来源于其或与其相关的值,例如通过用户界面提供。例如,所述方法可包括基于所确定的肿瘤特异性突变为克隆性的概率来提供“克隆性状态”标记(flag)或值。作为另一个实例,所述方法可包括提供鉴定突变的信息(例如,如突变的序列和其基因组位置)。
37、根据另一个方面,提供了在对象中鉴定一种或更多种克隆性新抗原的方法,所述方法包括:在对象中鉴定多个肿瘤特异性突变;使用前述方面的任一实施方案的方法在对象中确定一个或更多个所述肿瘤特异性突变是否可能是克隆性的;以及确定一个或更多个所述肿瘤特异性突变是否可能产生新抗原,其中克隆性新抗原是这样的肿瘤特异性突变,其满足所述肿瘤特异性突变是否可能是克隆性的一个或更多个预定标准和所述肿瘤特异性突变是否可能产生新抗原的一个或更多个标准。根据本方面还描述了在对象中鉴定一种或更多种克隆性新抗原的方法,所述方法包括:通过处理器使用来自所述对象的一个或更多个样品的序列数据在对象中鉴定多个肿瘤特异性突变;通过处理器使用前述权利要求中任一项所述的方法在对象中确定一个或更多个肿瘤特异性突变是否可能是克隆性的;以及通过所述处理器选择一个或更多个肿瘤特异性突变作为候选克隆性新抗原,其中候选克隆性新抗原是这样的肿瘤特异性突变,其满足肿瘤特异性突变是否可能是克隆性的至少一个或更多个预定标准和任选地满足肿瘤特异性突变是否可能产生新抗原的一个或更多个标准。
38、本方面的方法可具有以下特征中的任意一个或更多个。
39、克隆性新抗原可以是这样的肿瘤特异性突变,其满足选自以下的至少一个标准:具有高于预定阈值的为克隆性的概率;具有高于阈值的为克隆性的概率,该阈值适应性地设置为在已确定概率的肿瘤特异性突变中选出克隆性概率最高的预定数目的肿瘤特异性突变;以及具有高于阈值的为克隆性的概率,所述阈值适应性地设置为在已确定概率的肿瘤特异性突变中选出预定最高百分位数的肿瘤特异性突变。因此,关于肿瘤特异性突变是否可能是克隆性的一个或更多个预定标准可选自:具有高于预定阈值的为克隆性的可能性的突变、具有高于适应性地设置为在可能性被确定的肿瘤特异性突变中选出预定数目的克隆性可能性最高的突变和具有适应性地设置为在可能性被确定的肿瘤特异性突变中选出预定最高百分位数的肿瘤特异性突变的阈值的为克隆性的可能性。
40、克隆性新抗原可以是这样的肿瘤特异性突变,其满足选自以下的至少一个标准:与在肿瘤细胞中表达的表达产物相关、被预测为产生不在所述对象的正常细胞中表达的蛋白质或肽、被预测为产生至少一种可能由mhc分子呈递的肽、被预测为产生至少一种可能由已知存在于对象中的mhc等位基因呈递的肽、和被预测为产生免疫原性的蛋白质或肽。例如,克隆性新抗原可以是肿瘤特异性突变,其满足以下标准:其被预测为导致蛋白质序列变化(例如,因为其是编码的、因为其影响剪接位点、因为其导致截短的肽等),因此产生了不可在对象的正常细胞中表达的蛋白质或肽。是否是这种情况可例如通过与对象的预测的正常蛋白质组比较来进一步证实。因此,关于肿瘤特异性突变是否可能产生新抗原的一个或更多个标准可选自:突变与在肿瘤细胞中表达的表达产物相关、突变被预测为产生不在对象的正常细胞中表达的蛋白质或肽、突变被预测为产生至少一种可能由mhc分子呈递的肽、突变被预测为产生至少一种可能由已知存在于对象中的mhc等位基因呈递的肽以及突变被预测为产生免疫原性的蛋白质或肽。
41、所述方法还可包括鉴定与一种或更多种克隆性新抗原相关的一种或更多种肽(即由于存在肿瘤特异性突变而被预测为存在于肿瘤细胞中的一种或者更多种肽序列,其中肿瘤特异性突变满足如上所述的一个或更多个标准(与克隆性的可能性和产生克隆性新抗原的可能性有关)。
42、如技术人员理解的,本文中所述操作的复杂性(至少由于获得需要如本文所述的数值积分的后验概率的复杂性,和通常通过对基因组dna进行测序产生的数据量)使得其超出心理活动的范围。因此,除非上下文另外指明(例如在描述了样品制备或采集步骤的情况下),否则本文中所述方法的所有步骤都是计算机实现的。
43、根据另一个方面,提供了为已诊断为患有癌症的对象提供预后的方法,所述方法包括在来自对象的一个或更多个样品中鉴定多个肿瘤特异性突变以及使用第一方面的任何实施方案的方法来确定每个肿瘤特异性突变为克隆性的可能性。
44、所述方法还可包括将对象分类为具有高克隆性新抗原负荷与低克隆性新抗原负荷,其至少部分取决于具有高于预定阈值的为克隆性的概率的肿瘤特异性突变的比例,其中与具有低克隆性新抗原负荷的对象相比,具有高克隆性新抗原负荷的对象具有改善的预后。
45、根据另一个方面,提供了为已诊断为患有癌症的对象提供免疫治疗的方法,所述方法包括:使用如本文中所述的方法(例如根据第二方面的任何实施方案的方法)来鉴定一种或更多种克隆性新抗原;以及设计靶向一种或更多种经鉴定的克隆性新抗原的免疫治疗。
46、所述方法可具有以下特征中的任意一个或更多个。
47、靶向一种或更多种克隆性新抗原的免疫治疗可以是免疫原性组合物,一种包含免疫细胞或治疗性抗体的组合物。免疫原性组合物可包含经鉴定的克隆性新抗原(例如,如新抗原肽或蛋白质或者显示出新抗原的细胞)的一个或更多个克隆,或足以表达一种或者更多种经鉴定的克隆性新抗原的物质(例如,编码新抗原的dna或rna分子)。包含免疫细胞的组合物可包含t细胞、b细胞和/或树突细胞。包含治疗性抗体的组合物可包含一种或更多种这样的抗体,所述抗体识别一种或更多种经鉴定的克隆性新抗原中的至少一种。抗体可以是单克隆抗体。
48、在任何方面的任何实施方案中,癌症可选自膀胱癌、胃癌、食管癌、乳腺癌、结直肠癌、宫颈癌、卵巢癌、子宫内膜癌、肾癌(肾细胞癌)、肺癌(小细胞癌、非小细胞癌和间皮瘤)、脑癌(胶质瘤、星形细胞瘤、胶质母细胞瘤)、黑素瘤、淋巴瘤、小肠癌(十二指肠癌和空肠癌)、白血病、胰腺癌、肝胆肿瘤、生殖细胞癌、前列腺癌、头颈部癌、甲状腺癌和肉瘤。癌症可以是肺癌。癌症可以是黑素瘤。癌症可以是膀胱癌。癌症可以是头颈部癌。
49、在任何方面的任何实施方案中,对象可以是人。
50、设计靶向一种或更多种经鉴定的克隆性新抗原的免疫治疗可包括针对一种或更多种所靶向的克隆性新抗原中的每种来设计一种或更多种候选肽,每种肽包含所靶向的克隆性新抗原的至少一部分。
51、所述方法还可包括获得一种或更多种候选肽。所述方法还可包括针对一种或更多种特性来测试一种或更多种候选肽。测试可在体外或在计算机上进行。例如,可针对免疫原性、由mhc分子显示的倾向性(任选地由特定的mhc分子等位基因显示,其中等位基因可根据由对象表达的mhc等位基因选择)、引起免疫细胞群体增殖的能力等来测试一种或更多种肽。
52、所述方法还可包括产生免疫治疗。所述方法还可包括获得已经用一种或更多种候选肽脉冲的树突细胞群体。免疫治疗可以是这样的组合物,所述组合物包含识别一种或更多种经鉴定的克隆性新抗原中至少一种的t细胞。所述组合物可富集靶向一种或更多种经鉴定的克隆性新抗原中至少一种的t细胞。所述方法可包括获得t细胞群体并且扩增所述t细胞群体,以提高靶向一种或更多种经鉴定的克隆性新抗原中至少一种的t细胞的数目或相对比例。
53、所述方法还可包括获得t细胞群体。t细胞群体可从对象中分离,例如从获自对象的一个或更多个肿瘤样品、或从对象的外周血样品、或从对象的来自其他组织的样品中分离。t细胞群体可包括肿瘤浸润性淋巴细胞。t细胞可使用本领域公知的方法分离。例如,可从基于cd3、cd4或cd8的表达的样品产生的单细胞悬液中纯化t细胞。t细胞可由通过ficoll-paque梯度从样品中富集。
54、所述方法还可包括扩增t细胞群体。例如,t细胞可通过在已知为t细胞提供有丝分裂刺激的条件下进行离体培养来扩增。举例来说,t细胞可用细胞因子(例如il-2)或用有丝分裂抗体(例如抗cd3和/或cd28)进行培养。t细胞可与抗原呈递细胞(antigen-presentingcell,apc)(其可以是经辐照的)共培养。apc可以是树突细胞或b细胞。树突细胞可用包含一种或更多种经鉴定的新抗原的肽作为单一刺激剂或作为刺激新抗原肽的合并物进行脉冲处理。t细胞的扩增可使用本领域已知的方法,包括例如使用人工抗原呈递细胞(artificial antigen presenting cell,aapc)(其提供另外的共刺激信号)和呈递合适的肽的自体pbmc来进行。自体pbmc可用如本文中所讨论的包含新抗原的肽作为单一刺激剂或者作为替代地作为刺激新抗原的合并物进行脉冲。
55、根据另一个方面,提供了用于扩增t细胞群体以用于在对象中治疗癌症的方法,所述方法包括:使用如本文中所述的方法,例如根据第二方面的任何实施方案的方法,来鉴定一种或更多种克隆性新抗原;获得t细胞群体,所述t细胞群体包含能够特异性识别经鉴定的克隆性新抗原中的一种的t细胞;以及将t细胞群体与包含经鉴定的克隆性新抗原的组合物共培养。
56、所述方法可具有以下特征中的一个或更多个。
57、所获得的t细胞群体可被假设为包含能够特异性识别经鉴定的克隆性新抗原中的一种的t细胞。所述方法优选地包括鉴定多种克隆性新抗原。t细胞群体可包含多种t细胞,每种t细胞能够特异性识别多种经鉴定的克隆性新抗原中的一种,并将t细胞群体与包含多种经鉴定的克隆性新抗原的组合物进行共培养。共培养可导致特异性识别一种或更多种新抗原的t细胞群体的扩增。扩增可通过将t细胞与新抗原和抗原呈递细胞共培养进行。抗原呈递细胞可以是树突细胞。因此,扩增可以是对新抗原具有特异性的t细胞的选择性扩增。扩增还可包括一个或更多个非选择性扩增步骤。
58、根据另一个方面,提供了这样的组合物,所述组合物包含通过根据前述方面的任何实施方案的方法获得的或可获得的t细胞群体。
59、根据另一个方面,提供了这样的组合物,所述组合物包含新抗原、新抗原特异性免疫细胞、或识别新抗原的抗体,其用于在对象中治疗或预防癌症,其中所述新抗原已使用本文中所述的方法鉴定为克隆性新抗原。
60、根据另一个方面,提供了这样的组合物,所述组合物包含新抗原、新抗原特异性免疫细胞、或识别新抗原的抗体,其中所述新抗原已使用本文中所述的方法鉴定为克隆性新抗原。
61、根据另一个方面,提供了这样的细胞或细胞群体,所述细胞或细胞群体在其表面表达新抗原,其中所述新抗原已使用本文中所述的方法确定为克隆性新抗原。
62、根据另一个方面,提供了新抗原、识别新抗原的免疫细胞或识别新抗原的抗体,其用于在对象中治疗或预防癌症,其中所述新抗原已使用本文中所述的方法鉴定为克隆性新抗原。
63、根据另一个方面,提供了新抗原、识别新抗原的免疫细胞或识别新抗原的抗体在制备用于在对象中治疗或预防癌症的药物中的用途,其中所述新抗原已使用本文中所述的方法鉴定为克隆性新抗原。
64、根据另一个方面,提供了治疗已诊断为患有癌症的患者的方法,所述方法包括施用使用本文中所述的方法提供的免疫治疗或如本文中所述的组合物。
65、根据另一个方面,提供了系统,其包括:处理器;和包含这样的指令的计算机可读介质,当所述指令由处理器执行时,导致处理器进行本文中所述的任意方法例如根据上述第一、第二、第三或第四方面的任何实施方案的方法的步骤。
66、根据另一个方面,提供了一个或更多个非暂态计算机可读介质,其包含这样的指令,当所述指令由一个或更多个处理器执行时,导致一个或更多个处理器进行本文中所述的任意方法例如根据上述第一、第二、第三或第四方面的任何实施方案的方法的步骤。
67、根据另一个方面,提供了这样的计算机程序,所述计算机程序包含这样的代码,当所述代码在计算机上执行时,导致计算机进行本文中所述的任何方法例如根据上述第一、第二、第三或第四方面的任何实施方案的方法的步骤。
- 还没有人留言评论。精彩留言会获得点赞!