测量低聚半乳糖的方法与流程
本发明涉及一种在制备具有高gos纤维含量的乳制品和/或其中乳糖含量也显著降低的富含gos纤维的乳制品的同时进行低聚半乳糖(gos)定量的在线(in-line)方法。
背景技术:
1、低聚半乳糖(gos)是定义为具有通过糖苷键连接的两个或更多个半乳糖部分(包括多达九个)的碳水化合物。人和动物无法消化gos。gos还可以包括一个或多个非半乳糖糖部分,包括葡萄糖。摄入gos的有益作用之一是它能够充当益生元,通过选择性地刺激有益的结肠微生物(例如细菌)的增殖来提供生理益处。已确定的健康作用使得对作为食物的gos的兴趣日益增加。
2、β-半乳糖苷酶(ec 3.2.1.23)可以催化两种类型的反应。对于大多数β-半乳糖苷酶,将乳糖水解为单糖d-葡萄糖和d-半乳糖是优选的反应。在该反应的催化过程中,该酶水解乳糖并瞬时结合半乳糖-酶复合物中的半乳糖单糖,该半乳糖-酶复合物将半乳糖转移到水的羟基基团上,从而释放d-半乳糖和d-葡萄糖。然而,在某些条件下,例如高乳糖浓度和/或高温,β-半乳糖苷酶可以将半乳糖转移到d-半乳糖或d-葡萄糖的羟基基团上。这种反应称为转半乳糖基化。转半乳糖基化的主要产物是gos。
3、已经开发了用于产生高水平gos的酶和方法。参见,例如,具有转半乳糖基化活性的多肽,wo 2013/182686。另外,已经开发了产生高水平gos同时还进一步减少剩余乳糖的方法。参见,例如,使用乳糖酶提供高gos纤维水平和低乳糖水平,wo 2020/117548。在酸奶、奶酪、奶饮料和奶粉等奶基产品的乳品应用的上下文中,虽然gos的产生会减少内源性乳糖,但对于乳糖不耐症个体来说,乳糖水平可能仍然过高。据估计,世界上约70%的人口患有乳糖不耐症,即如果他们摄入乳糖,就会患上消化系统障碍。
4、如上所述,某些β-半乳糖苷酶在正确的条件下可以驱动乳糖转化为gos。然而,这些相同的酶在正确的条件下可以催化gos水解为葡萄糖和半乳糖(取决于gos的组成)。通常,这发生在gos形成峰值时或接近峰值时。gos水解可以通过酶灭活(例如通过加热)来防止。然而,了解何时灭活需要关于转半乳糖基化程度的可靠且准确的信息,特别是何时达到最佳gos浓度。
5、本领域持续需要测定最佳gos产率的方法。在工业乳品环境中尤其如此,在该环境中,奶生产商在短时间内处理数十万升奶,并且没有先进的实验室设备,也没有经过训练的现场(on premises)化学家。
技术实现思路
1、提出了一种用于测定样品中碳水化合物含量的方法,该方法具有以下步骤:获得对应于该样品的ftir(傅里叶变换红外光谱术)光谱数据;提供该ftir光谱数据的至少一部分作为经过训练的机器学习模型的输入;以及使用该经过训练的机器学习模型处理该ftir光谱数据的至少一部分,以生成碳水化合物含量值,从而提供该样品中碳水化合物含量水平的定量指示。
2、任选地,碳水化合物是gos、dp3+gos、葡萄糖、半乳糖和dp2中的一种或多种。任选地,dp2是乳糖。任选地,碳水化合物是dp3+gos。任选地,样品是奶基底物。任选地,作为经过训练的机器学习模型的输入提供的ftir光谱数据部分是有限光谱范围内的ftir光谱数据。任选地,有限光谱范围包括1046cm-1、1076cm-1、1157cm-1和1250cm-1。任选地,有限光谱范围是下限在900cm-1和1100cm-1之间且上限在1300cm-1和1500cm-1之间的波数区域。任选地,有限光谱范围是下限在1008cm-1和1068cm-1之间且上限在1414cm-1和1475cm-1之间的波数区域。任选地,有限光谱范围位于波数区域1037:1450cm-1。
3、任选地,经过训练的机器学习模型是使用训练数据集训练的监督学习模型,对于多个训练样品中的每一个,该训练数据集具有对应于该训练样品的ftir光谱数据和该训练样品中碳水化合物含量水平的测量指示。
4、任选地,经过训练的机器学习模型是偏最小二乘回归(plsr)模型。
5、任选地,经过训练的机器学习模型是神经网络回归模型。
6、任选地,经过训练的机器学习模型包括多元线性回归(mlr)。
7、任选地,经过训练的机器学习模型是主成分回归(pcr)。
8、任选地,经过训练的机器学习模型包括经典最小二乘法cls。
9、任选地,经过训练的机器学习模型包括决策树算法。
10、任选地,ftir光谱数据是从基于服务器的数据存储中获得的,该ftir光谱数据由客户端设备上传到该数据存储中。
11、任选地,使用经过训练的机器学习模型对ftir光谱数据的至少一部分进行的处理是使用从客户端设备获得的ftir光谱数据在服务器设备上进行的。
12、任选地,碳水化合物含量值可供客户端设备访问。
13、提出了一种用于训练机器学习模型以预测奶基底物中碳水化合物含量的方法,该方法具有以下步骤:获得训练数据集,对于多个训练样品中的每一个,该训练数据集具有对应于该训练样品的ftir(傅里叶变换红外光谱术)光谱数据和该训练样品中碳水化合物含量水平的测量指示;以及使用该训练数据集进行监督学习,以确定该机器学习模型的经过训练的模型系数。
14、任选地,碳水化合物是gos、dp3+gos、葡萄糖、半乳糖和dp2中的一种或多种。任选地,dp2是乳糖。任选地,碳水化合物是dp3+gos。
15、在本发明的另一方面,提出了一种计算机程序,当在数据处理装置上执行时,该计算机程序控制该数据处理装置以进行上述方法。
16、在本发明的另一方面,提出了一种用于制备含有碳水化合物的奶产品的方法,该方法具有以下步骤:用转半乳糖基化酶处理奶基底物;对该奶基底物的样品进行ftir(傅里叶变换红外光谱术),以获得对应于该样品的ftir光谱数据;基于使用经过训练的机器学习模型对该ftir光谱数据的至少一部分进行的处理,获得碳水化合物含量值,从而提供该样品中碳水化合物含量水平的定量指示;以及基于该碳水化合物含量值,确定何时通过对该奶基进行巴氏杀菌来灭活该转半乳糖基化酶。
17、任选地,碳水化合物是gos、dp3+gos、葡萄糖、半乳糖和dp2中的一种或多种。任选地,dp2是乳糖。任选地,碳水化合物是dp3+gos。
18、29.
19、任选地,ftir光谱数据的至少一部分由客户端设备上传到服务器,用于由经过训练的机器学习模型进行基于服务器的处理以生成碳水化合物含量值,并且碳水化合物含量值由客户端设备作为基于服务器的处理的结果而获得。
20、任选地,用于制备奶基碳水化合物的方法具有优于10%的准确度,表示为平均值的预测标准误差(3.75%),在含有至少0.1%脂肪、至少0.5%溶解乳糖和至少1%蛋白质的奶基中,gos的浓度在0-7.5%的浓度范围内。
21、任选地,用于制备奶基碳水化合物的方法具有高于0.9(不太优选的是0.85、0.8、0.75等)的pls回归模型的线性度(r2),以验证gos含量。
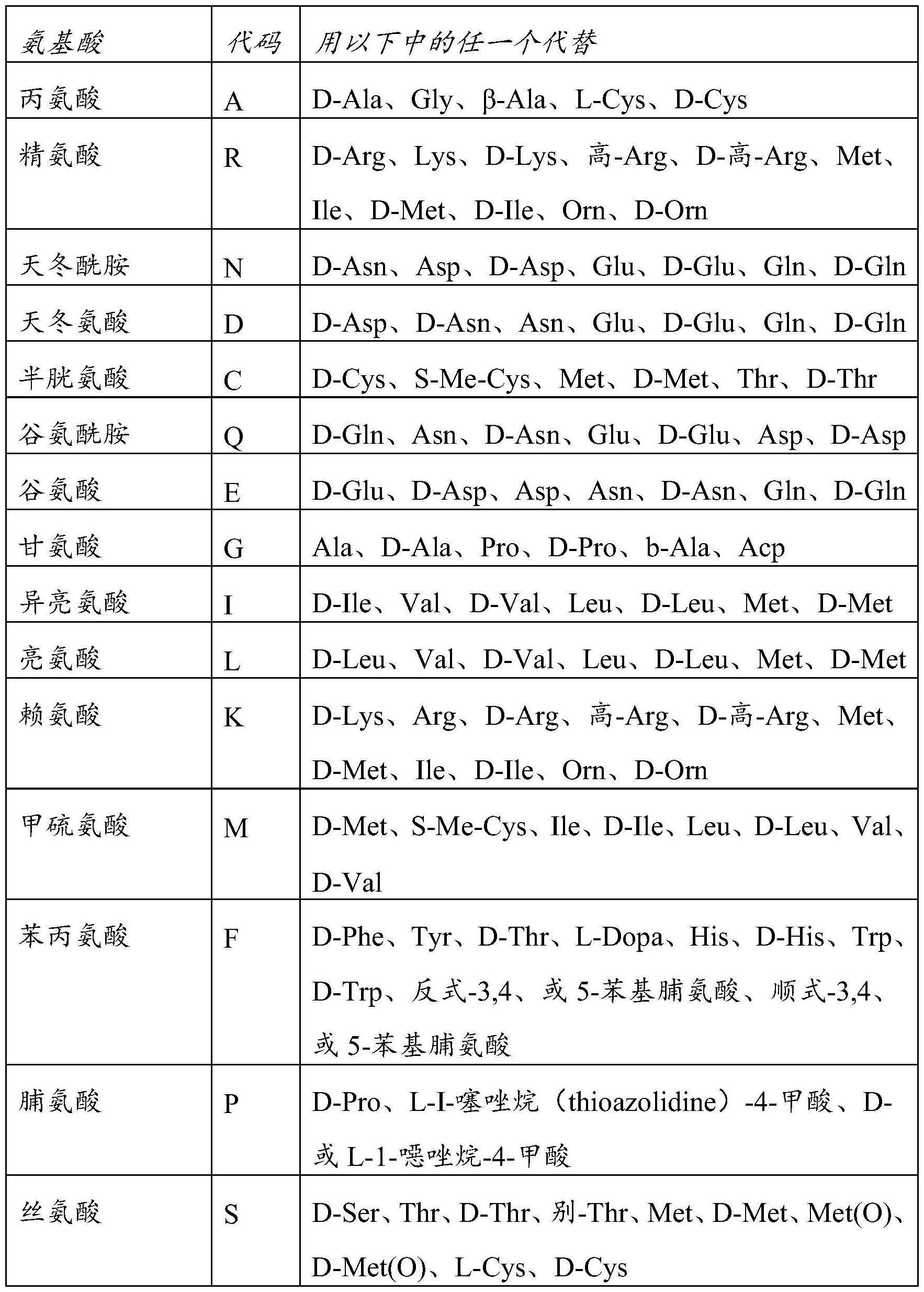
22、任选地,转半乳糖基化酶衍生自两歧双歧杆菌(bifidobacterium bifidum)。任选地,转半乳糖基化酶是来自两歧双歧杆菌的截短的β-半乳糖苷酶。任选地,来自两歧双歧杆菌的截短的β-半乳糖苷酶在c末端被截短。任选地,来自两歧双歧杆菌的截短的β-半乳糖苷酶是与seq id.no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5或其转半乳糖基酶活性片段具有至少70%序列同一性的多肽。
23、任选地,该多肽与seq id.no:1、seq id no:2、seq id no:3、seq id no:4或seqid no:5或其转半乳糖基酶活性片段具有至少80%序列同一性。任选地,该多肽与seqid.no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5或其转半乳糖基酶活性片段具有至少90%序列同一性。任选地,该多肽与seq id.no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5或其转半乳糖基酶活性片段具有至少95%序列同一性。任选地,该多肽与seq id.no:1、seq id no:2、seq id no:3、seq id no:4或seq id no:5或其转半乳糖基酶活性片段具有至少99%序列同一性。任选地,该多肽是根据seq id.no:1、seqid no:2、seq id no:3、seq id no:4或seq id no:5或其转半乳糖基酶活性片段的序列。任选地,该多肽是根据seq id no:1的序列。
- 还没有人留言评论。精彩留言会获得点赞!