基于机器学习的钛合金热挤压工艺优化方法及装置
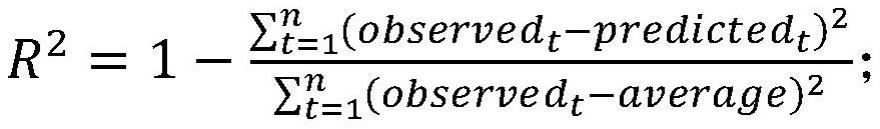
本发明涉及钛合金工艺优化的,尤其是涉及一种基于机器学习的钛合金热挤压工艺优化方法及装置。
背景技术:
1、热挤压是一种较为先进的塑性成形工艺方法,利用挤压机上的挤压杆提供挤压力,将处于再结晶温度以上的金属坯料,在挤压筒内进行挤压,形成与模具内腔形状相同或者相关联的产品,传统的热挤压工艺优化主要采用实验和理论研究为主,不仅速度慢、时间长且需要耗费大量的人力、财力、物力,随着社会的发展和科技的进步,以计算机为平台,以有限元分析软件为工具的优化方式逐渐普及,但由于热挤压工艺较为复杂,使得有限元模模拟优化效率低下,影响工艺进度。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于机器学习的钛合金热挤压工艺优化方法及装置,以缓解现有技术中热挤压有限元模拟工艺复杂,工艺优化速度慢的技术问题。
2、第一方面,本发明提供了一种基于机器学习的钛合金热挤压工艺优化方法,包括:
3、获取数据集,所述数据集包括热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比、热挤压坯料再结晶体积分数标准差以及热挤压坯料再结晶平均晶粒尺寸标准差,并将所述数据集划分训练集以及测试集;
4、构建第一随机森林模型,利用预处理后的数据集对所述第一随机森林模型进行学习以获取第二随机森林模型;
5、利用第二随机森林模型的预测结果获取第一映射关系以及第二映射关系,所述第一映射关系为热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比与热挤压坯料再结晶平均晶粒尺寸标准差映射关系,所述第二映射关系为热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比与热挤压坯料再结晶体积分数标准差的映射关系;
6、确定第二随机森林模型预测结果的优化范围,所述优化范围的参数包括热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比,并利用多目标遗传算法、第一映射以及第二映射获取目标函数的解;
7、目标函数包括:
8、minf(x),s.t{lb≤x≤ub};
9、f(x)=ω1·f1(x)+ω2·f2(x);
10、其中,f1(x)表示再结晶体积分数标准差;f2(x)表示再结晶平均晶粒尺寸标准差,lb以及ub分别代表上限以及下限,ω1和ω2为权值;
11、所述目标函数的解为优化范围中目标函数最小值所对应的热挤压坯料挤压初始温度、热挤压坯料挤压速度以及热挤压坯料挤压比。
12、一种可能的方式是,所述多目标遗传算法的遗传操作包括交叉、变异和选择,交叉率为pcro、变异率为pmul;
13、多目标遗传算法所涉及的参数包括:种群数量npop、最大迭代次数dgen、目标函数数量fobj以及决策变量的个数nvol;
14、多目标优化遗传算法的选择类型为:带有多目标函数的权值结合经营保存机制中的pareto强度进化算法。
15、一种可能的方式是,所述方法还包括:对所述目标函数的解进行验证。
16、一种可能的方式是,所述第一随机森林模型以及第二随机森林模型基分类器选择cart算法决策树,基学习器采用bootstrap重抽样法和多决策树结合构建bagging集;
17、所述第一随机森林模型以及第二随机森林模型参数包括:最大特征数量fmax、最大叶子节点数lmax、决策树最大深度dmax、子树的数量m、特征重要度n。
18、一种可能的方式是,所述方法还包括:
19、对所述第二随机森林模型进行评价并获取评价指标,所述第二随机森林的评价指标满足要求,则利用所述第二随机森林模型对输入数据进行预测以获取随机森林模型的预测结果,所述输入数据包括热挤压坯料挤压速度、热挤压坯料挤压初始温度以及热挤压坯料挤压比,所述随机森林模型的预测结果包括热挤压坯料再结晶平均晶粒尺寸标准差以及热挤压坯料再结晶体积分数标准差。
20、一种可能的方式是,所述评价指标包括r2、rmse和mape;
21、
22、
23、
24、t—取值指针
25、n—样本总量
26、r2—决定系数;
27、rmse—均方根误差;
28、mape—平均绝对百分比误差;
29、observedt—数据集的热挤压坯料再结晶体积分数标准差和/或热挤压坯料再结晶平均晶粒尺寸标准差观测值;
30、predictedt—第二随机森林模型的热挤压坯料再结晶体积分数标准差和/或热挤压坯料再结晶平均晶粒尺寸标准差预测值;
31、average—数据集的热挤压坯料再结晶体积分数标准差和/或热挤压坯料再结晶平均晶粒尺寸标准差平均值。
32、一种可能的方式是,构建损失函数,利用采用梯度下降法,损失函数值最小值所对应的随机森林模型为第二随机森林模型。
33、一种可能的方式是,所述预处理包括对数据集进行归一化处理。
34、一种可能的方式是,利用热挤压坯料横断半径与热挤压坯料模具出口半径进行表征热挤压坯料挤压比。
35、第二方面,本发明提供了一种基于机器学习的钛合金热挤压工艺优化装置,包括:
36、数据获取模块:用于获取数据集,所述数据集包括热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比、热挤压坯料再结晶体积分数标准差以及热挤压坯料再结晶平均晶粒尺寸标准差,并将所述数据集划分训练集以及测试集;
37、随机森林模型构建模块:用于构建第一随机森林模型,利用预处理后的数据集对所述第一随机森林模型进行学习以获取第二随机森林模型;
38、映射获取模块:用于利用第二随机森林模型的预测结果获取第一映射关系以及第二映射关系,所述第一映射关系为热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比与热挤压坯料再结晶平均晶粒尺寸标准差映射关系,所述第二映射关系为热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比与热挤压坯料再结晶体积分数标准差的映射关系;
39、优化模块:用于确定第二随机森林模型预测结果的优化范围,所述优化范围的参数包括热挤压坯料挤压速度、热挤压坯料挤压初始温度、热挤压坯料挤压比,并利用多目标遗传算法、第一映射以及第二映射获取目标函数的解;
40、目标函数包括:
41、minf(x),s.t{lb≤x≤ub};
42、f(x)=ω1·f1(x)+ω2·f2(x);
43、其中,f1(x)表示再结晶体积分数标准差;f2(x)表示再结晶平均晶粒尺寸标准差,lb以及ub分别代表上限以及下限,ω1和ω2为权值;
44、所述目标函数的解为优化范围中目标函数最小值所对应的热挤压坯料挤压初始温度、热挤压坯料挤压速度以及热挤压坯料挤压比。
45、本发明实施例带来了以下有益效果:本发明提供了一种基于机器学习的钛合金热挤压工艺优化方法及装置,所述方法包括:获取数据集,构建第一随机森林模型,利用预处理后的数据集对所述第一随机森林模型进行学习以获取第二随机森林模型;利用第二随机森林模型的预测结果获取第一映射关系以及第二映射关系,确定第二随机森林模型的预测结果的优化范围,并利用多目标遗传算法、第一映射以及第二映射获取目标函数的解,所述目标函数的解为优化范围中目标函数最小值所对应的热挤压坯料挤压初始温度、热挤压坯料挤压速度以及热挤压坯料挤压比。通过本发明可以缓解现有技术中热挤压有限元模拟时间长,工艺优化速度慢的技术问题。
46、本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
47、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!