一种结直肠癌患病风险的早筛方法、系统、终端及介质
本发明涉及一种人工智能,更具体地说,它涉及一种结直肠癌患病风险的早筛方法、系统、终端及介质。
背景技术:
1、结直肠癌(colorectal cancer,crc),也称大肠癌,是一种常见的消化道恶性肿瘤。结直肠癌具有遗传倾向,与遗传相关的结直肠癌约占结直肠癌的20%,一级亲属有结直肠癌病史的人群被指南列入高风险人群。与其它肿瘤一样,结直肠癌的发病机理,仍然不完全清楚。早期的结直肠癌筛查手段显得至关重要,指南推荐的经典筛查方案是降低结直肠癌发病率和死亡率的主要手段,但人群的筛查依从性直接影响该方案的实施。因此,通过对影响结直肠癌高危人群筛查依从性的因素研究,对预防疾病发生的作用显得至关重要。结直肠癌的发生是一个由“正常粘膜-腺瘤-早期癌-进展期癌”的序贯过程,约5-10年,因此,结直肠癌的这一生物学特点适用于筛查,被世界卫生组织列为适合筛查的癌肿之一。结直肠癌筛查有利于疾病的早发现、早诊断和早治疗,这是预防结直肠癌和减少结直肠癌死亡率的最主要手段。
2、目前,针对结直肠癌的患病风险预测大都是基于机器学习算法来实现的,而在机器学习领域中,其属于典型的分类模型,如逻辑回归、支持向量机、k-neighbor邻近和决策树,以及基于集成的学习器,如adaboost、xgboost和lightgbm等。根据各算法应用的实际结果,lightgbm在兼顾分类性能目标的同时,呈现良好的速度、且内存资源占用更少。但是基于lightgbm算法所构建的模型包含的参数纬度较高,而高纬度的参数会影响风险预测模型的收敛速度,从而影响预测时间,并且最重要的是lightgbm在不同参数下的性能差异会导致预测能力不稳定,以及lightgbm算法会出现过拟合的现象导致风险预测泛化能力欠佳。
3、因此,如何能够克服上述机器学习算法的缺陷来达到对结直肠癌风险的有效筛查是目前急需解决的问题。
技术实现思路
1、为解决现有技术的不足之处,本发明提供一种结直肠癌患病风险的早筛方法、系统、终端及介质,本发明利用主成分分析法降低特征集的参数维度,得到待用特征集再利用机器学习算法以待用特征集为基础构建结直肠癌风险基础模型,避免高纬度的参数会影响风险早筛模型的收敛速度,从而影响筛查时间,通过分布采样实现对结直肠癌风险基础模型的参数优化,从而实现对结直肠癌风险基础模型的参数寻优,利用学习曲线对结直肠癌风险基础模型寻优后的参数进行学习来避免结直肠癌风险优化模型出现过拟合的现象,从而提高了结直肠癌风险早筛模型筛查的准确率,以及提高了结直肠癌患病风险的早筛模型的泛化能力。
2、本发明的上述技术目的是通过以下技术方案得以实现的:
3、本技术的第一方面,提供了一种结直肠癌患病风险的早筛方法,方法包括:
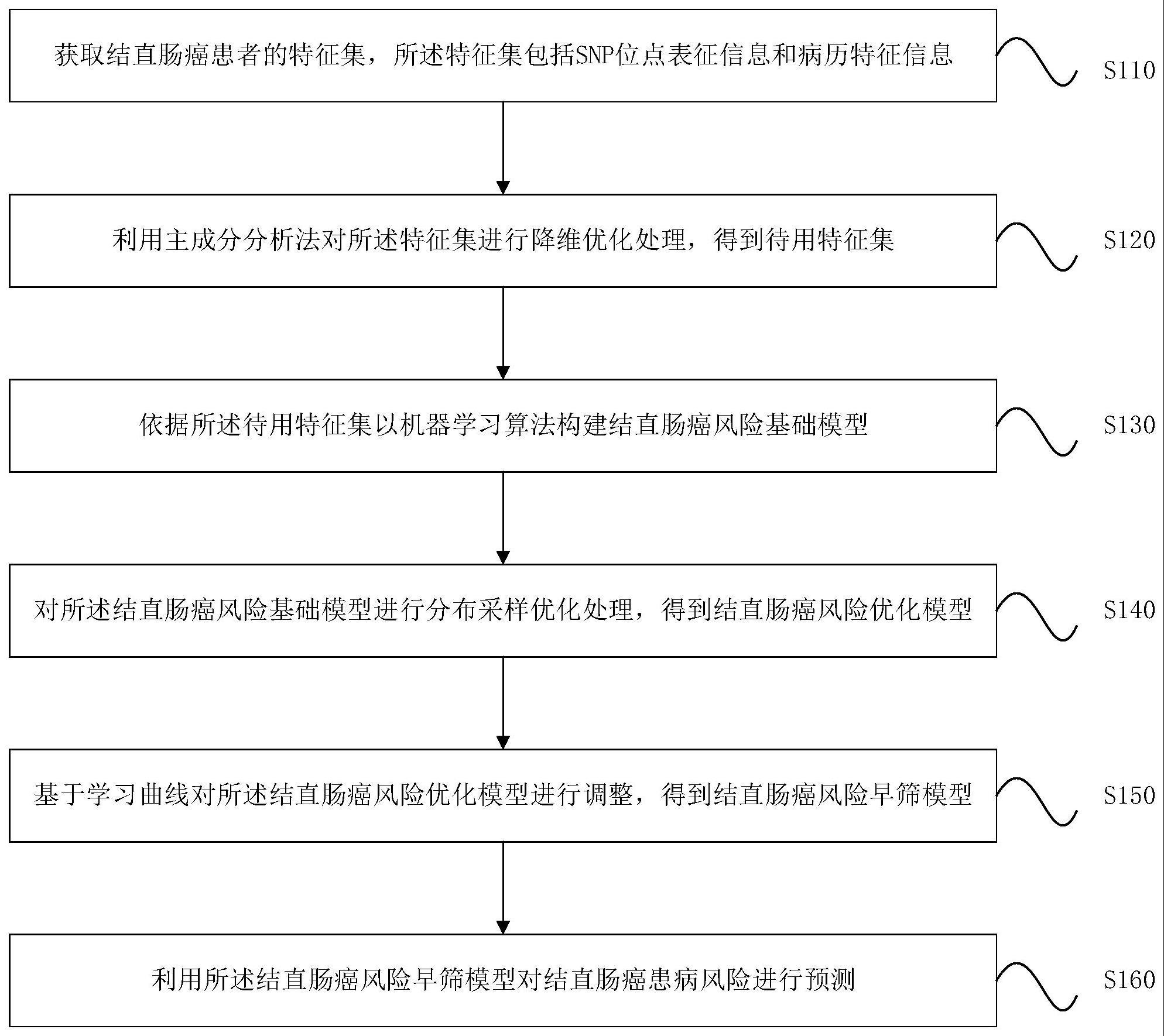
4、获取结直肠癌患者的特征集,所述特征集包括snp位点表征信息和病历特征信息;
5、利用主成分分析法对所述特征集进行降维优化处理,得到待用特征集;
6、依据所述待用特征集以机器学习算法构建结直肠癌风险基础模型;
7、对所述结直肠癌风险基础模型进行分布采样优化处理,得到结直肠癌风险优化模型;
8、基于学习曲线对所述结直肠癌风险优化模型进行调整,得到结直肠癌风险早筛模型;
9、利用所述结直肠癌风险早筛模型对结直肠癌患病风险进行预测。
10、在一种实施方案中,所述机器学习算法为lightgbm算法。
11、在一种实施方案中,所述病历特征信息包括结直肠癌患者的体重、身高、疾病史以及生活习惯。
12、在一种实施方案中,对所述结直肠癌风险基础模型进行分布采样优化处理,得到结直肠癌风险优化模型,具体包括:
13、利用网格搜索法引入随机因素对结直肠癌风险基础模型进行随机搜索处理,得到结直肠癌风险基础模型的采样参数;
14、采用卡方分布对所述采样参数进行优化处理,得到采样参数中的分析结果,其中分析结果表示卡方分布处理的准确率;
15、剔除分析结果中不符合准确率阈值的采样参数,得到结直肠癌风险优化模型。
16、在一种实施方案中,基于学习曲线对所述结直肠癌风险优化模型进行调整,得到结直肠癌风险早筛模型,具体包括:
17、预设样本数据集,将所述样本数据集划分为训练集和测试集;
18、基于学习曲线对所述训练集和测试集进行学习,得到训练集和测试集在某一学习率的准确率;
19、基于训练集和测试集在某一学习率的准确率对所述结直肠癌风险优化模型进行调整,得到基于学习曲线的结直肠癌风险早筛模型。
20、本技术的第二方面,提供了一种结直肠癌患病风险的早筛系统,系统包括:
21、特征获取模块,用于获取结直肠癌患者的特征集,所述特征集包括snp位点表征信息和病历特征信息;
22、特征处理模块,用于利用主成分分析法对所述特征集进行降维优化处理,得到待用特征集;
23、模型构建模块,用于依据所述待用特征集以机器学习算法构建结直肠癌风险基础模型;
24、模型优化模块,用于对所述结直肠癌风险基础模型进行分布采样优化处理,得到结直肠癌风险优化模型;
25、模型调整模块,用于基于学习曲线对所述结直肠癌风险优化模型进行调整,得到结直肠癌风险早筛模型;
26、预测模块,用于利用所述结直肠癌风险早筛模型对结直肠癌患病风险进行预测。
27、在一种实施方案中,模型优化模块包括:
28、随机搜索模块,用于利用网格搜索法引入随机因素对结直肠癌风险基础模型进行随机搜索处理,得到结直肠癌风险基础模型的采样参数;
29、优化处理模块,用于采用卡方分布对所述采样参数进行优化处理,得到采样参数中的分析结果,其中分析结果表示卡方分布处理的准确率;
30、采样参数剔除模块,用于剔除分析结果中不符合准确率阈值的采样参数,得到结直肠癌风险优化模型。
31、在一种实施方案中,模型调整模块包括:
32、数据集划分模块,用于预设样本数据集,将所述样本数据集划分为训练集和测试集;
33、学习模块,用于基于学习曲线对所述训练集和测试集进行学习,得到训练集和测试集在某一学习率的准确率;
34、调整模块,用于基于训练集和测试集在某一学习率的准确率对所述结直肠癌风险优化模型进行调整,得到基于学习曲线的结直肠癌风险早筛模型。
35、本技术的第三方面,提供了一种计算机终端,所述计算机终端包括处理器、存储器、以及存储在所述存储器上并可被所述处理器执行的计算机程序,其中所述计算机程序被所述处理器执行时,实现如本技术的第一方面所述的结直肠癌患病风险的早筛方法的步骤。
36、本技术的第四方面,提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,其中所述计算机程序被处理器执行时,实现如本技术的第一方面所述的结直肠癌患病风险的早筛方法的步骤。
37、与现有技术相比,本发明具有以下有益效果:
38、本发明利用主成分分析法降低特征集的参数维度,得到待用特征集再利用机器学习算法以待用特征集为基础构建结直肠癌风险基础模型,避免高纬度的参数会影响风险早筛模型的收敛速度,从而影响筛查时间,通过分布采样实现对结直肠癌风险基础模型的参数优化,从而实现对结直肠癌风险基础模型的参数寻优,利用学习曲线对结直肠癌风险基础模型寻优后的参数进行学习来避免结直肠癌风险优化模型出现过拟合的现象,从而提高了结直肠癌风险早筛模型筛查的准确率,以及提高筛查结直肠癌患病风险的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!