基于药物敏感性数据的多组学生物标志物筛选方法和装置
本发明属于多组学生物标志物,具体涉及一种基于药物敏感性数据的多组学生物标志物筛选方法和装置。
背景技术:
1、癌症的治疗是全世界都在努力解决的一个重大难题,高通量测序技术和人工智能技术的发展为癌症的精准治疗提供了无限可能。但是抗癌药物的对患者个体的治疗效果在使用前是未知的,如果药物选择失败会耽误治疗时机,给患者带来严重的身心伤害。所以如何利用较少的多组学生物标志物结合人工智能技术高效地实现预测癌症患者对药物的敏感性,从而为每个患者制定个性化的治疗方案,实现精准医疗是一个非常重要的问题,对减少患者的痛苦和经济负担,提高治疗的效果具有重要的意义。因此,这也成为了全世界研究人员都非常关注的一个问题。
2、近年来,已经有一些研究在利用机器学习预测药物敏感性方面做出了不少努力和贡献,但却鲜有研究利用机器学习的可解释性来寻找用于预测药物敏感性的多组学生物标志物。
3、随着计算机软硬件和人工智能技术的不断发展,产生了一系列性能优秀的机器学习模型,例如,支持向量机、随机森林、神经网络等。人工智能和其他学科的交叉也越来越广泛,其中医学人工智能作为交叉学科的代表更是得到快速发展。
4、随着人们对多组学研究的深入,研究人员提出了一些公开数据集并被广泛地应用于医学人工智能的研究,例如癌症药物敏感性基因组学数据集(genomics of drugsensitivity in cancer,gdsc),癌症基因组图谱(the cancer genome atlas,tcga)等数据集,这为开展基于药物敏感性数据的多组学生物标志物筛选方法和装置的研究提供了便利。
5、然而,现有的方法通常只是利用多组学数据来预测患者的药物敏感性,并没有充分挖掘不同生物标志物在预测中的重要度差异来减少需要的生物标志物数量,以便于提高预测的性能和效率。因此,目前尚未有比较好的模型能够通过机器学习的可解释性来减少预测患者药物敏感性所需的生物标志物数量并达到高效、高准确率的预测。
技术实现思路
1、鉴于上述,本发明目的是提供一种基于药物敏感性数据的多组学生物标志物筛选方法和装置,利用机器学习的可解释性来筛选对于药物敏感性预测最重要的多组学生物标志物,以尽可能少的生物标志物实现高效率和高准确度预测患者的药物敏感性。
2、为实现上述发明目的,本发明提供的一种基于药物敏感性数据的多组学生物标志物筛选方法,包括以下步骤:
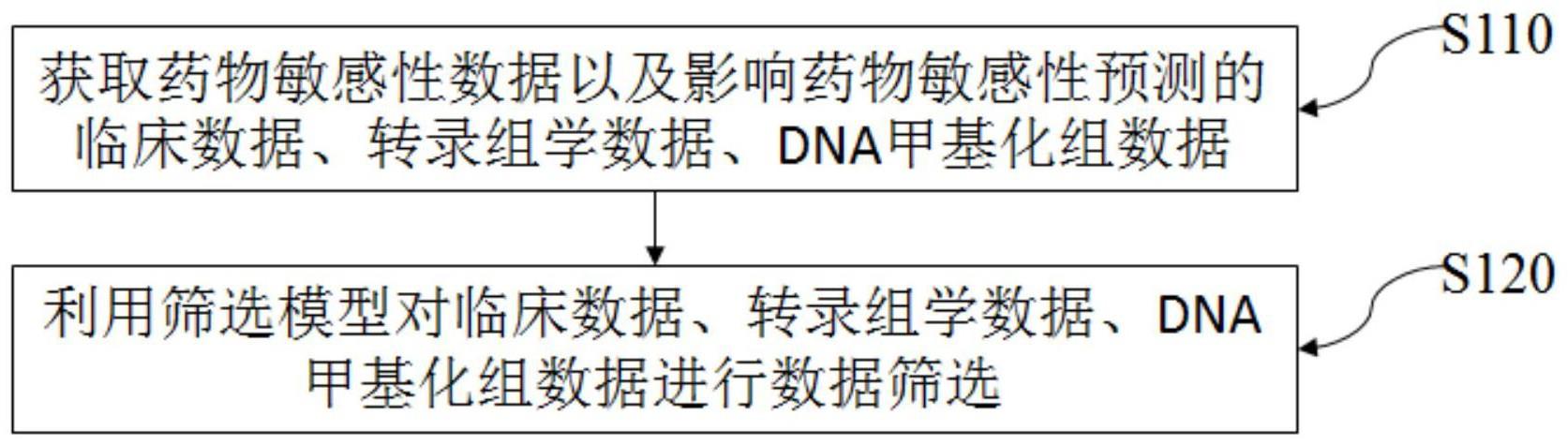
3、获取药物敏感性数据以及影响药物敏感性预测的临床数据、转录组学数据、dna甲基化组数据;
4、利用筛选模型进行数据筛选,包括:基于转录组生物标志物筛选模块对转录组学数据进行筛选以得到一组候选转录组生物标志物,基于dna甲基化组生物标志物筛选模块对dna甲基化组数据进行筛选以得到一组候选dna甲基化组生物标志物,基于多组学联合筛选模块对候选转录组生物标志物、候选dna甲基化组生物标志物以及临床数据进行联合筛选以得到混合候选组,基于敏感性预测效果验证筛选模块对混合候选组中特征进行根据药物敏感性数据的验证筛选以确定最终筛选结果;
5、所述混合候选组和最终筛选结果中特征均包括转录组生物标志物、dna甲基化组生物标志物以及临床指标中的至少一种。
6、在一个实施例中,所述基于转录组生物标志物筛选模块对转录组学数据进行筛选以得到一组候选转录组生物标志物,包括:
7、将微环境内间质细胞与经过药物处理后正常化的间质细胞测序进行差异分析获得差异mrna,将差异mrna与转录组学数据进行求交集后结果输入至转录组生物标志物筛选模块包括的第一药物敏感性预测模型中;
8、在转录组生物标志物筛选模块中,基于第一药物敏感性预测模型计算敏感性预测结果,并基于敏感性预测结果采用shap分析确定每个特征的重要度,依据重要度筛选得到一组候选转录组生物标志物,其中,每个特征为1个转录组生物标志物。
9、在一个实施例中,所述基于dna甲基化组生物标志物筛选模块对dna甲基化组数据进行筛选以得到一组候选dna甲基化组生物标志物,包括:
10、在dna甲基化组生物标志物筛选模块中,将dna甲基化组生物标志物输入至第二药物敏感性预测模型,基于第二药物敏感性预测模型计算敏感性预测结果,并基于敏感性预测结果采用shap分析确定每个特征的重要度,依据重要度筛选得到一组候选dna甲基化组生物标志物,其中,每个特征为1个dna甲基化组生物标志物。
11、在一个实施例中,所述基于多组学联合筛选模块对候选转录组生物标志物、候选dna甲基化组生物标志物以及临床数据进行联合筛选以得到混合候选组,包括:
12、在多组学联合筛选模块中,将候选转录组生物标志物、候选dna甲基化组生物标志物以及临床数据的组合结果输入至第三药物敏感性预测模型,基于第三药物敏感性预测模型计算敏感性预测结果,并基于敏感性预测结果采用shap分析确定每个特征的重要度,依据重要度筛选得到混合候选组,其中,每个特征为转录组生物标志物、dna甲基化组生物标志物或临床指标。
13、在一个实施例中,所述基于敏感性预测结果采用shap分析确定每个特征的重要度,包括:
14、计算每个特征的归因值φj,表示为:
15、
16、其中,j为特征索引,{x1,…,xp}为特征集合,p为特征总量,{x1,…,xp}\{xj}为不包括特征{xj}的所有特征可能的集合,fx(s)为特征子集s的敏感性预测结果,fx(s∪{xj})为特征子集s∪{xj}的敏感性预测结果;
17、基于归因值φj计算特征的重要性ij,表示为:
18、
19、其中,i表示样本索引,n表示样本总量,表示第i个样本的第j个特征的归因值。
20、在一个实施例中,所述依据重要度筛选得到一组候选转录组生物标志物,包括:依据重要度筛选重要度降序排序靠前的最多25个转录组生物标志物作为一组候选转录组生物标志物;
21、所述依据重要度筛选得到一组候选dna甲基化组生物标志物,包括:依据重要度筛选重要度降序排序靠前的最多25个dna甲基化组生物标志物作为一组候选dna甲基化组生物标志物;
22、所述依据重要度筛选得到混合候选组,包括:依据重要度筛选重要度降序排序靠前的最多25个特征组成混合候选组,其中,每个特征为转录组生物标志物、dna甲基化组生物标志物或临床指标。
23、在一个实施例中,所述基于敏感性预测效果验证筛选模块对混合候选组中特征进行根据药物敏感性数据的验证筛选以确定最终筛选结果,包括:
24、对混合候选组中特征进行抽取组成验证特征组,将验证特征组输入至第四敏感性预测模型计算敏感性预测结果,并基于药物敏感性数据采用十折交叉验证测试敏感性预测结果的准确率和auc,并基于准确性和auc筛选预测效果最高的验证特征组作为最终筛选结果,其中,每个特征为转录组生物标志物、dna甲基化组生物标志物或临床指标。
25、在一个实施例中,所述对混合候选组中特征进行抽取组成验证特征组,包括:
26、共提取m个验证特征组,第m个验证特征组包括重要度前m大的m个特征,其中,m取值为1-m,m为混合候选组中特征总量。
27、为实现上述发明目的,实施例提供了一种基于药物敏感性数据的多组学生物标志物筛选装置,包括:
28、获取单元,用于获取药物敏感性数据以及影响药物敏感性预测的临床数据、转录组学数据、dna甲基化组数据;
29、筛选单元,用于利用筛选模型进行数据筛选,包括:基于转录组生物标志物筛选模块对转录组学数据进行筛选以得到一组候选转录组生物标志物,基于dna甲基化组生物标志物筛选模块对dna甲基化组数据进行筛选以得到一组候选dna甲基化组生物标志物,基于多组学联合筛选模块对候选转录组生物标志物、候选dna甲基化组生物标志物以及临床数据进行联合筛选以得到混合候选组,基于敏感性预测效果验证筛选模块对混合候选组中特征进行根据药物敏感性数据的验证筛选以确定最终筛选结果;
30、其中,所述混合候选组和最终筛选结果均包括转录组生物标志物、dna甲基化组生物标志物以及临床指标中的至少一种。
31、为实现上述发明目的,实施例提供的一种基于药物敏感性数据的多组学生物标志物筛选装置,包括存储器、处理器以及存储在存储器中并可在处理器上执行的计算机程序,所述处理器执行计算机程序时实现上述基于药物敏感性数据的多组学生物标志物筛选方法。
32、与现有技术相比,本发明具有的有益效果至少包括:
33、通过转录组生物标志物筛选模块和dna甲基化组生物标志物筛选模块来筛选出对于影响患者药物敏感性预测的最重要的一组候选转录组生物标志物和候选dna甲基化组生物标志物,然后通过多组学联合筛选模块对候选转录组生物标志物、候选dna甲基化组生物标志物以及临床数据进行联合筛选以得到混合候选组,最后基于敏感性预测效果验证筛选模块对混合候选组中特征进行根据药物敏感性数据的验证筛选以确定最终筛选结果,这样在综合考虑患者的多组学数据和临床数据的基础上能够通过机器学习的可解释性来减少预测患者药物敏感性所需的生物标志物数量并提高了预测的性能和效率。
- 还没有人留言评论。精彩留言会获得点赞!