一种基于多元时序关系的老年慢病共病预警模型的构建方法
本发明涉及老年慢病共病预测,具体的说是一种基于多元时序关系的老年慢病共病预警模型的构建方法。
背景技术:
1、老年慢病数据中主要包括静态数据以及动态数据,静态数据主要是病人基本信息,医院检查结果,以及住院时用药等,而动态数据主要是出院后周期性随访所得到的病人情况包括用药,不良习惯,症状变化等,体现了一种多元时序关系。同时因为慢病发作周期长的特点,每个时间点发病的人群属于极少的一部分,这就造成了数据类别上的极度不平衡,这对预警模型的构建带来了极大的挑战,也出现了许多的方法来解决这两个问题。
2、神经网络出现以后,通常都是使用rnn(recurrent nn),以及lstm(long shortterm memory)来处理时序数据,但二者都是对时序数据进行顺序递归处理,这引入了极大的计算量,同时由于二者都存在长期依赖性的问题,容易造成性能的下降。针对数据存在的不平衡问题,主要包括重采样,cost-sensitive learning,logit adjustment以及生成模型等,都能在一定程度上缓解不平衡问题,但在类别极度不平衡的情况下,比如样本丰富类与样本稀疏类的比例在1000:1以上,许多方法的效果都显著下降,尤其是基于样本稀疏类的方法,因为此时很难在稀疏类上获取有效信息。
3、针对类别不平衡的时序数据,通常是上述两种方法的结合。其中引入生成式模型取得了较大的提升,不过大多数生成式方法都是基于样本稀疏类中的信息去生成稀疏样本,比如t-smote,ib-gan等,这极大地浪费了样本丰富类中所包含的信息,同时在极度不平衡的情况下,性能也会显著下降。
技术实现思路
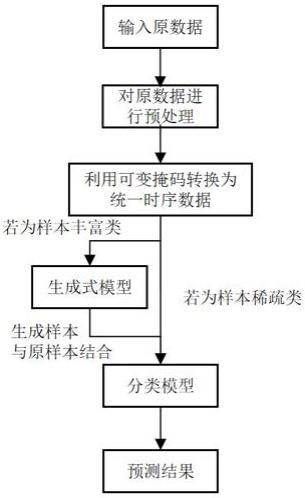
1、本发明的目的是针对现有技术的不足而提供的一种基于多元时序关系的老年慢病共病预警模型的构建方法,采用将样本丰富类转换为样本稀疏类的生成式模型与时序transformer结合的方法,利用生成式模型充分提取样本丰富类的信息,结合时序transformer提取的多元时序信息,构建一个统一的时序预警模型对老年慢病进行预警,该方法在时间维度上将数据集中的静态数据以及多元时序数据进行融合,同时将其中样本丰富类输入到生成器中转换为样本稀疏类,最终通过分类器对老年慢病共病进行预警,大大提高了预警模型的准确性,该方法对提升模型性能有极大的帮助,具有良好应用前景。
2、本发明的目的是这样实现的:一种基于多元时序关系的老年慢病共病预警模型的构建方法,其特点是该方法包括以下步骤:
3、步骤1:获取老年慢病共病数据,对数据进行预处理。
4、步骤2:对预处理后的数据集在时间维度上,将其中的静态数据以及多元时序数据进行融合。
5、步骤3:在步骤2处理完后的不平衡的数据集上预训练分类器。
6、步骤4:冻结预训练好的分类器,将数据集中样本丰富类作为生成器的输入,随后将生成器产生的伪样本输入到分类器中进行分类,构造损失函数使得生成器产生的样本远离样本丰富类,接近样本稀疏类。
7、步骤5,按步骤4训练生成器固定epoch后,不再冻结分类器,在整个数据集上对生成器和分类器进行协同训练,样本丰富类输入到生成器后与生成的伪样本一起输入到分类器中进行分类,而样本稀疏类直接输入到分类器中进行训练,得到基于多元时序关系的生成式预警模型,即基于多元时序关系的老年慢病共病预警模型。
8、步骤6,预测结果
9、将指定维度的老年慢病数据输入上述构建的生成式预警模型,即可完成对指定时间段内的疾病预警。
10、所述步骤2的数据预处理包括:
11、步骤1-1:通过删除有效信息较少的无关特征以及冗余特征,选出不同类型的老年慢病数据中的重要特征,并对包含多个类别的特征进行one-hot编码。
12、所述步骤2,具体包括:
13、步骤2-1:融合不同类型的数据,每一份时序数据都与对应的静态数据进行拼接,随后对所有数据进行imputation。
14、步骤2-2:将处理后的数据以时序为轴reshape,最终获得的数据集shape为[样本id,时序,特征]。
15、所述步骤3中的预训练操作具体包括:
16、步骤3-1:从某个固定的时间点开始,若在该时间点或之后的时间点发生了某种疾病,则保留发病时间点之前的时序数据,mask掉之后的时序数据,从而使得类别之间的样本数更均衡。
17、步骤3-2:选用时序transformer作为分类器,focal_loss作为损失函数,对分类器进行预训练,所述focal_loss作为损失函数由下述(a)式表示为:
18、fl(pt)=-(1-pt)γlog(pt) (a)。
19、其中,pt为分类器输出的概率,γ为可调节因子。
20、所述的步骤4中生成器的训练过程包括:
21、步骤4-1:冻结分类器,只选择样本丰富类作为生成器的输入,产生对应的伪样本。
22、步骤4-2:随后将生成的伪样本作为分类器的输入,得到下述(b)式表示的伪样本的logits:
23、logits=[c1,c2,...,cn] (b)。
24、其中,logits分类器输出;c1,c2,...,cn为样本丰富类对应的logit,且c1>c2>...>cn。
25、步骤4-3:选择logits第二高的类别作为伪样本的标签,同时将样本丰富类对应的logit置为0,计算交叉熵损失,使得产生的伪样本更加接近样本稀疏类,其交叉熵损失l的计算过程由下述(c)~(e)式表示为:
26、logits′=[0,c2,...,cn] (c);
27、label=[0,1,0,...0] (d);
28、
29、其中,label为伪标签;labelic为第i个样本第c个类别构建的伪标签;logits′ic为将样本丰富类对应的logit置为0得到的logits。
30、步骤4-4:设置一个阈值标签与开始的logits计算交叉熵损失,使得产生的伪样本更加远离样本丰富类,其交叉熵损失l1的计算过程由下述(f)~(g)式表示为:
31、label′=[0.4,0,...,0] (f);
32、
33、其中,label′为阈值分数;label′ic为第i个样本第c个类别的阈值分数;logitsic为第i个样本第c个类别的logit。
34、所述步骤5中生成器与分类器的协同训练如下:
35、步骤5-1,将样本丰富类输入生成器中与生成的伪样本一起输入分类器中进行判断。
36、步骤5-2,不再冻结分类器,设置伪样本的标签为第二高的类别,计算交叉熵损失。
37、步骤5-3,反向传播同时更新生成器以及分类器,使得分类器更加均衡。
38、本发明与现有技术相比具有充分利用样本丰富类的信息,将其经过生成式模型转换为样本稀疏类,从而缓解样本不平衡问题,同时借助在样本不平衡的数据集上训练得到的分类器会倾向于样本丰富类的特点,将生成器与分类器结合,使得产生的样本远离样本丰富类,接近样本稀疏类,再去更新得到的分类器将更加均衡,大大提高了预警模型的准确性,该方法对提升模型性能有极大的帮助,具有良好应用前景。
- 还没有人留言评论。精彩留言会获得点赞!