基于语言模型的信号肽-蛋白组合分泌效率预测方法及系统与流程
本发明属于生物信息,更具体地,涉及一种基于语言模型的信号肽-蛋白组合分泌效率预测方法及系统。
背景技术:
1、许多的抗体药物或者治疗性蛋白在研究、生产过程中都面临着产量低、稳定性差、活性低等问题。增加蛋白的产量是工业界一个亟需解决的问题。目前,在大规模制备抗体药物的过程中,常常利用动物细胞表达系统来生产分泌蛋白,而信号肽作为连接在分泌蛋白n端的一段氨基酸序列,能够控制蛋白质的分泌途径进而影响抗体蛋白的表达产量,因此,重组蛋白的高效表达与信号肽密切相关。许多原核和真核信号肽即使在不同物种之间在功能上也可以互换,天然信号肽也不一定是最有效的信号肽,把来自不同物种的信号肽与目标蛋白嵌合还可以介导cho细胞中抗体分泌增加。基于这些发现的基础上,我们可以筛选不同物种的不同信号肽,融合到要表达的蛋白中,从而提高最终的分泌蛋白表达量。
2、lars等将治疗性抗体和fc融合蛋白与16种不同信号肽融合,并通过瞬转与稳转分析了分泌效率,与对照信号肽相比,来自多种物种的信号肽甚至天然免疫球蛋白g信号肽都无法实现更高的效率,而使用人白蛋白和人天青霉素的天然信号肽获得了最佳结果。ryan等将免疫球蛋白重链和轻链信号肽的数据库依据序列相似度进行聚类分析,最终将重链信号肽分为8类,轻链信号肽分为2类,并且将他们融合到当前卖得最好的5个治疗性抗体中,用于分析信号肽对表达量的影响,优化后的信号肽对比原信号肽,能够将rituxan的产量提高两倍。昂贵的白细胞介素-21生产费用限制了它的应用,hee jun cho等通过优化il-21密码子将产量提高10倍,为了更一步提高产量,他们通过文献搜索了5个信号肽并且评估其对il-21表达量的影响,其中人天青霉素信号肽能够将产量再提高3倍。wei-li ling等将trastuzumab和pertuzumab交换不同的骨架,系统地比较了共168种抗体排列变体中的骨髓瘤和天然信号肽对产量的影响,在大部分情况下,骨髓瘤信号肽比天然信号肽产量要高。此外,他们根据信号肽和目标蛋白的氨基酸数量建立了逻辑回归模型,用于预测产量的高低,这是利用信号肽与蛋白的氨基酸序列性质预测产量的第一次尝试。stefano等手动提取了信号肽的156个特征,高通量分析了11,643个信号肽融合amyq(来自解淀粉芽孢杆菌的α淀粉酶)在枯草芽孢杆菌的蛋白的表达量,手动提取的信号肽的特征通过随机森林模型去预测蛋白的产量。
3、尽管对信号肽在工业界有着普遍的重要性并且有了多年的研究,但为目标蛋白找到最合适的信号肽往往是通过不断地重复实验得到的。过去有研究利用信号肽氨基酸数量特征等研究过信号肽与目标蛋白结合产量的关系,也有固定单个蛋白在原核系统上研究信号肽的特征与产量的关系。这些研究的特征往往是手动提取的,而且信号肽与目标蛋白的结合往往太过单一。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于语言模型的信号肽-蛋白组合分泌效率预测方法、电子设备或非暂态计算机可读存储介质,其目的在于通过截取信号肽-蛋白序列的序列长度作为信号肽特征序列,平衡信号肽和蛋白序列的特征,并且通过蛋白质语言模型,丰富截取的信号肽特征序列的结构特征,由此解决现有技术难以准确预测信号肽-蛋白组合分泌效率的技术问题。
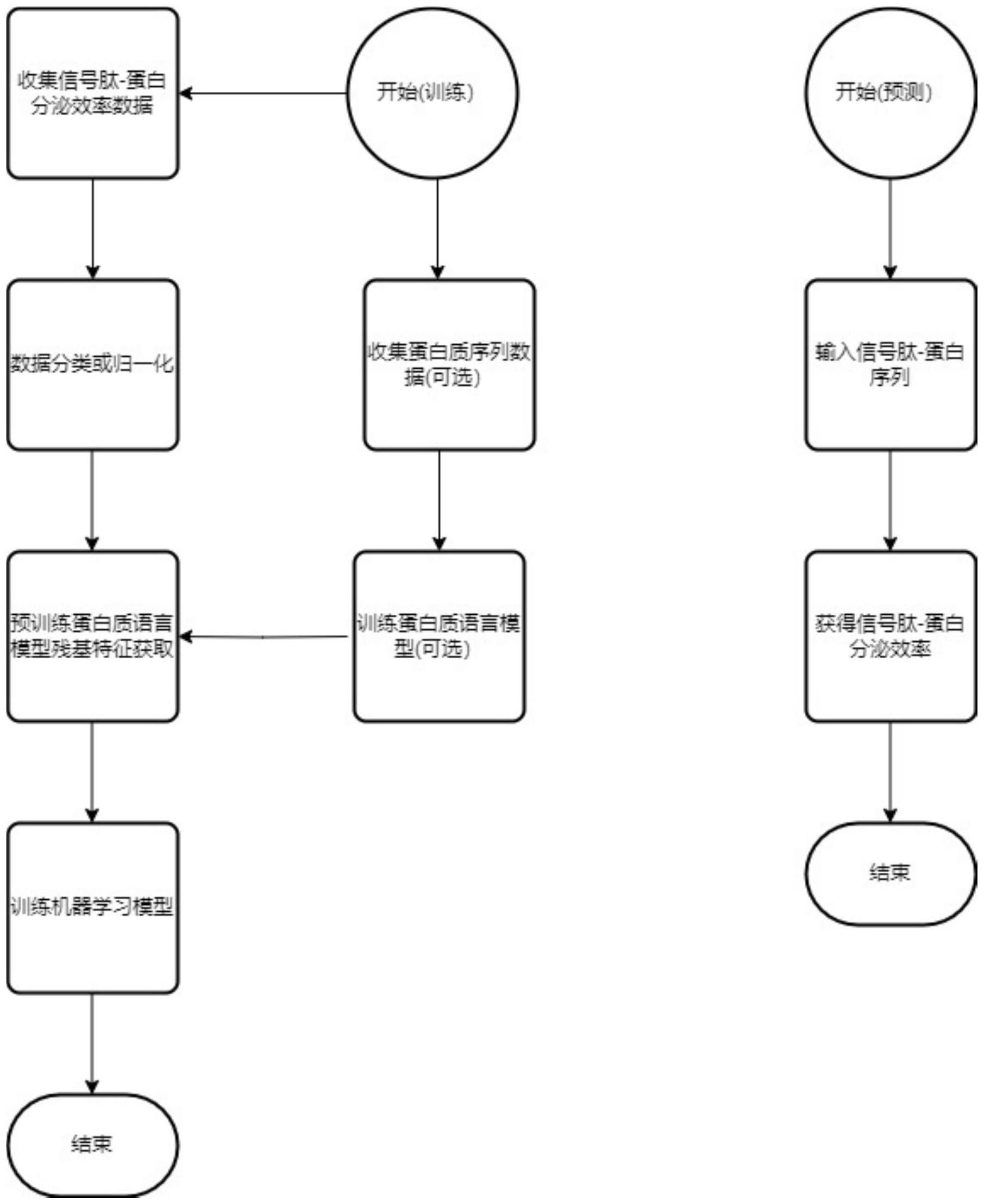
2、为实现上述目的,按照本发明的一个方面,提供了一种基于语言模型的信号肽-蛋白组合分泌效率预测方法,包括以下步骤:
3、(1)将待预测的信号肽-蛋白序列划分为翻译单元,对于每一个翻译单元截取n端的前m位氨基酸序列,作为信号肽特征序列;
4、(2)将步骤(1)中获得的每一个翻译单元的信号肽特征序列,输入到预训练的蛋白质语言模型,获得所述翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量;
5、(3)将步骤(2)中获得的待预测的信号肽-蛋白序列的每一翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量进行特征拼接,获得所述信号肽-蛋白序列的分泌特征向量获得所述信号肽-蛋白序列的分泌特征向量;
6、(4)将步骤(3)获得的信号肽-蛋白序列的分泌特征向量输入到预测模型,预测所述信号肽-蛋白序列的分泌效率等级。
7、优选地,所述信号肽-蛋白组合分泌效率预测方法,其步骤(1)所述信号肽特征序列长度即m取值在80~200之间,优选100至150。
8、优选地,所述信号肽-蛋白组合分泌效率预测方法,其步骤(1)所述翻译单元是指mrna序列翻译为氨基酸序列的最小独立单元,一般蛋白质亚基为翻译单元。
9、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述与训练的蛋白质语言模型包括但不限于esm-1、esm-2、aminobert、以及采用氨基酸序列进行训练的自然语言深度学习模型,所述自然语言深度学习模型的框架为bert及其衍生框架、或gpt及其衍生框架;
10、所述蛋白质语言模型基于语言模型,以氨基酸序列作为训练数据,进行模型的自监督预训练,得出的氨基酸特征向量和蛋白质序列特征向量。
11、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述待预测的信号肽-蛋白序列的每一翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量进行特征拼接,进行归一化处理后,获得所述信号肽-蛋白序列的分泌特征向量。
12、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述待预测的信号肽-蛋白序列的每一翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量进行特征拼接,采用以下方式之一:
13、其一,将各翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量直接拼接为分泌特征向量,所述分泌特征向量的维度为各翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量的维度之和;
14、其二,将各翻译单元的氨基酸残基特征向量和/或蛋白质序列特征向量采用一维卷积模型进行卷积后再拼接为分泌特征向量。
15、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述一维卷积模型包括一个一维卷积层、以及一个池化层;氨基酸残基特征向量和/或蛋白质序列特征向量通过一维卷积层,在序列长度方向进行卷积;卷积层输出通过一个池化层降低信息维度,防止过拟合;池化层输出转化为一维向量,将多个已转化成一维的向量直接拼接为分泌特征向量。
16、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述预测模型为分类模型或回归模型;优选分类模型,例如支持向量机、随机森林、多层感知器模型。
17、优选地,所述信号肽-蛋白组合分泌效率预测方法,其所述预测模型,按照如下方法进行训练:
18、(4-1)获取与待预测信号肽-蛋白组合相同类型的信号肽-蛋白组合分泌效率训练数据,所述信号肽-蛋白组合与待预测信号肽-蛋白组合具有相同数量的翻译单元;
19、(4-2)将步骤(4-1)获得的信号肽-蛋白组合分泌效率训练数据,按照分泌效率进行分类或将数据归一化后直接预测分泌效率数值,获得训练样本集;优选按照分泌效率进行分类;
20、(4-3)采用步骤(4-2)获得的训练样本集训练,以最小化损失函数的值为目标,训练所述预测模型直至收敛;
21、当所述预测模型为分类模型时,优选采用模型预测的分泌效率与真实分泌效率的交叉熵作为损失函数loss,记作:
22、
23、其中,n为训练样本呢数量,k为分类类别数,如果第i个样本属于c类别则yic=1,否则yic=0,pic为预测样本i属于c类别的概率;
24、当所述预测模型为回归模型时,优选采用模型预测的分泌效率与真实分泌效率的均方误差或者平均绝对误差作为损失函数loss,记作:
25、
26、其中,n为样本数量,yi为第i个样本分泌效率,为第i个样本的预测分泌效率,m为范数,如m=1则损失函数为平均绝对误差,m=2则损失函数为均方误差。
27、按照本发明的另一个方面,提供了一种系统,为电子设备或非暂态计算机可读存储介质,其所述电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现本发明提供的信号肽-蛋白组合分泌效率预测方法的步骤;
28、所述非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现本发明提供的信号肽-蛋白组合分泌效率预测方法的步骤。
29、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
30、本发明将信号肽-蛋白序列截取合适长度的信号肽特征序列,平衡信号肽信息和蛋白序列信息,利用蛋白质语言模型,提取信号肽特征序列的氨基酸理化特征和序列上下文特征,输入到预测模型,预测神经网络预测信号肽与目标蛋白配对的表达量,从而能够代替实验找到与目标蛋白最适配的信号肽。本发明避免了蛋白序列过长,掩盖信号肽序列的关键特征,同时通过蛋白质语言模型,丰富截取的蛋白序列结构特征,避免了由于序列的不完整导致结构特征缺失的问题,提高了预测模型对于信号肽-蛋白组合分泌效率的预测准确性。
- 还没有人留言评论。精彩留言会获得点赞!