一种基于投票机制的乳房癌诊断与预测方法
本发明涉及乳房癌诊断与预测领域,具体涉及一种基于投票机制的乳房癌诊断与预测方法。
背景技术:
1、乳房肿瘤通过穿刺采样进行分析可以确定其为良性(benign)的或为恶性(malignant)的。从患者乳房穿刺得到的病灶组织为良性和恶性的细胞核显微图像,医学研究发现乳房肿瘤病灶组织的细胞核显微图像的10个量化特征:细胞核直径,质地,周长,面积,光滑度,紧密度,凹陷度,凹陷点数,对称度,断裂度与该肿瘤的性质有密切的关系。现试图根据已获得的实验数据建立起一种诊断乳房肿瘤是良性还是恶性的方法。数据来自已经确诊的500个病例,每个病例的一组数据包括采样组织中各细胞核的这10个特征量的平均值,标准差和“最坏值”(各特征的三个最大数据的平均值)共30个数据.将方法用于另外69名已做穿刺采样分析的患者(69组数据)。
2、若为节省费用,还想发展一种只用此30个特征数据中的部分特征来区分乳房肿瘤是良性还是恶性的方法,需要找到一个特征数少而区分又很好的方法。
技术实现思路
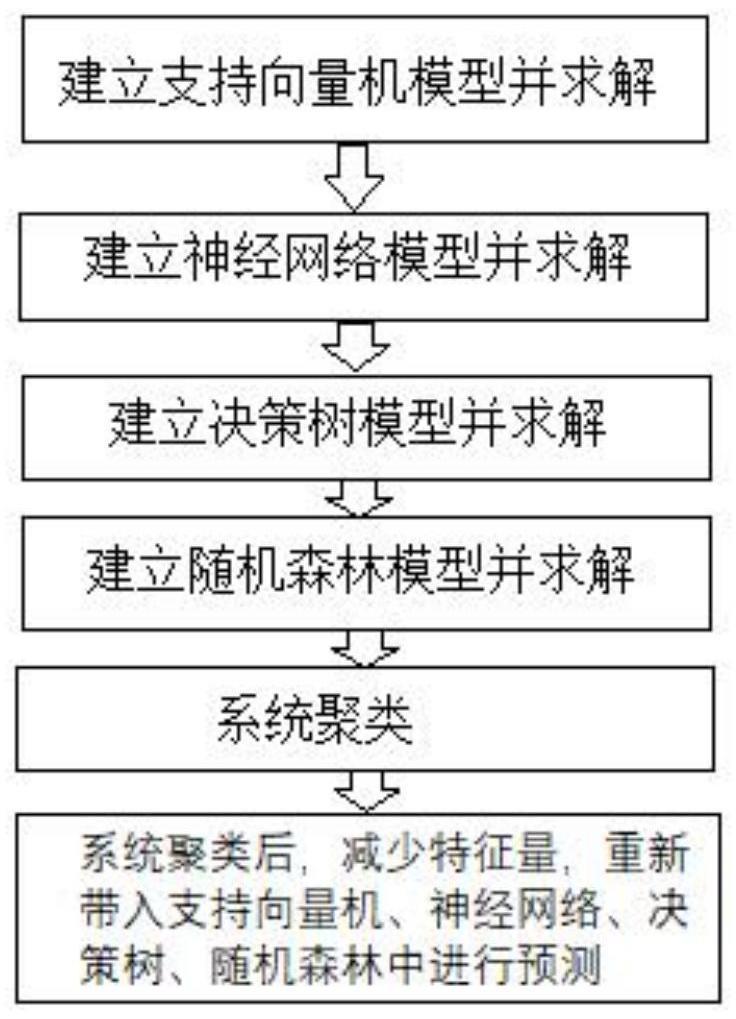
1、本发明公开了一种基于支持向量机、神经网络、决策树、随机森林的投票机制的乳房癌诊断与预测方法。乳房癌的诊断可以通过穿刺采样分析判别为良性还是恶性,研究发现乳房癌肿瘤有10个细胞核显微特征,每个特征有均值、标准差和“最坏值”。本发明根据乳房癌的特征属性,建立乳房癌判断预测模型,对于二分类问题,采用支持向量机、神经网络、决策树、随机森林来分类预测,将四种方法的预测结果实行少数服从多数的投票机制,同时采用系统聚类筛选主要特征属性,减少模型训练成本,实现了特征数少而区分又很好的乳房癌诊断。
2、本发明的技术解决方案是:
3、一种基于支持向量机、神经网络、决策树、随机森林的投票机制的乳房癌诊断与预测方法,其特征在于,包括如下步骤:
4、i、建立支持向量机模型并求解
5、步骤1):确定特征点到超平面距离最短的目标函数:
6、
7、s.t.yi(wtxi+b)≥1,i=1,2,...,n.
8、对上述式子的每条约束添加拉格朗日乘子αi≥0,则上式的拉格朗日函数可以写成:
9、
10、其中α=(α1+α2,...,αn)t,w为分隔超平面的法向量,xi为单个样本的第i个特征属性,b为超平面与原点的距离。
11、步骤2):研究其对偶问题:
12、
13、
14、上述对偶问题满足wtxi+b>1,根据slater条件,强对偶问题成立,所以原问题和其对偶问题拥有相同的最优解。求解得出α,从而得到w,b,进一步得出分类预测函数:
15、
16、步骤3):求解,利用matlab内置fitcsvm函数分类,采用高斯核函数,smo序列最小优化的方法,作图画出散点图和支持向量。
17、ii、建立神经网络模型并求解
18、步骤1):确定前项传播函数:
19、
20、其中输入向量为x(0),f是激活函数,x(i-1)作为前一层的输出向量,也作为当前层的输入向量,w(i)是前一层和当前层的权重连接矩阵,b(i)是本层的偏置项。
21、步骤2):确定误差损失目标函数
22、选择单个样本梯度下降法,将损失函数写成单个样本均方误差的算术平均:
23、
24、其中是单个样本的损失函数。
25、步骤3):确定修正权重项和偏执项
26、采用单个样本进行迭代,梯度下降法的权重更新公式为:
27、
28、偏置项更新公式为:
29、
30、其中
31、
32、步骤4):误差反向传播算法
33、
34、先计算出输出层的误差项,得到输出层的权重矩阵和偏置项,然后逐步往前推得到前一层的。
35、步骤5):求解
36、第一步:初始化服从某种分布的随机数来初始化权重矩阵和偏置向量。
37、第二步:利用交叉验证随机分割数据集,并进行归一化处理。
38、第三步:创建一个两层前馈网络,该网络有一个隐含层,其中有4个神经元,前向传播,计算每一层输出值。
39、第四步:误差逆传播算法,先求出输出层,再逐次往前,利用梯度下降法更新权重和偏置项。
40、第五步:依次迭代。
41、iii、建立决策树模型并求解
42、步骤1):决策树剪枝
43、1.后剪枝
44、设γ为决策树复杂程度的惩罚系数,一个叶节点包含了m个样本,该结点再划分为l个子结点,第i个子结点包含mi个样本,其中有ei个样本被分错,当如下式子成立时,表示置信度足够大决策树可以继续划分从而减少损失。
45、
46、2.代价-复杂度剪枝算法
47、定义一个决策树的每个非叶结点的α值为:
48、
49、其中e(t)是结点t的错误率,e(ti)是以结点t为父结点的子树的错误率,是该子树的叶结点错误率之和,|ti|为叶结点数目。
50、步骤2):选取划分属性方法
51、1.信息熵
52、设样本集d包括l类样本,信息熵定义为:
53、
54、2.信息增益
55、设某个属性a对样本集d进行划分所获得的信息增益为:
56、
57、其中di为样本集被属性a划分后第i个取值为ai的样本。因此选用划分属性的公式如下:
58、
59、3.增益率
60、
61、其中
62、4.基尼指数
63、设样本集d包括l类样本,其中第k类样本所占的比例为pk(k=1,2,...,l),基尼指数:
64、
65、对某个属性a的基尼指数:
66、
67、选用划分属性的公式如下:
68、
69、步骤3):cart决策树模型建立
70、第一步:对于当前结点的数据集d,如果样本个数小于阈值或者没有属性,则返回决策子树,当前结点停止递归。
71、第二步:计算样本集d的基尼指数,如果基尼指数小于阈值,则返回决策树子树,当前节点停止递归。
72、第三步:计算当前结点现有的各个属性的每个属性值对数据集d的基尼指数。
73、第四步:选择基尼指数最小的属性a和对应的属性值a。根据这个最优属性和最优属性值,把数据集划分成两部分d1和d2,同时建立当前结点的左右结点,左结点的数据集为d1,右节点的数据集为d2。
74、第五步:对左右结点递归调用1-4步,生成决策树。
75、iv、建立随机森林模型并求解
76、第一步:对样本集d进行t次随机采样,每次采样n个属性,得到n个样本的采样集dt,以采样集dt训练数据,创建决策树ht(x)。
77、第二步:得到决策树集合{h1(x),h2(x),...,ht(x)}
78、第三步:最终分类预测结果由t个弱学习器投票最多的为最终分类结果:
79、
80、第四步:最终回归结果由t个弱学习器得到的回归结果算术平均得到的值为最终模型的输出:
81、
82、v将四种方法的预测结果实行少数服从多数的投票机制,得出诊断预测结果。
83、vi系统聚类:
84、1.先将数据标准化处理,采用组间联结方法。假设gp和gq是两个类别,d(gp,gq)是这两个类的距离,xi∈gp,xj∈gq,d(xi,xj)是两个样本之间的距离,组件联结方法:
85、
86、2.分类完成后采用肘部法则通过图形大致估计最优的聚类数量。
87、假设一共将n个样本划分到k个类中(k≤n-1),用ck表示第k个类(k=1,2,...,k),且该类重心的位置记为uk,那么第k个类的畸变程度为∑i∈ck|xi-uk|2,定义所有类的总畸变程度:
88、
89、聚成k个类后,对各类样本利用偏相关系数进行变量之间关系的分析:
90、3.计算样本的偏相关系数:
91、若有k(k>2)个变量x1,x2,…xk,任意两个变量xi和xj的g(g≤k-2)阶样本偏相关系数公式为:
92、
93、4.偏相关系数检验
94、第一步:提出原假设h0:偏相关系数与零无显著性差异,即两自变量之间不相关。
95、第二步:t检验,代入公式计算。
96、
97、其中r为偏相关系数,n为样本数,q为阶数,t统计量服从n-q-2个自由度的t分布。
98、5.计算检验统计量的观测值和对应的概率p值。
99、6.决策。如果检验统计量的概率p值小于给定的显著性水平θ(0.05),应拒绝零假设,认为两总体的偏相关系数与零有显著性差异,即两变量之间有显著相关关系;反之,如果检验统计量的概率p值大于给定的显著性水平θ,则说明两变量之间没有显著的相关关系。
100、vii系统聚类后,减少特征量,重新带入支持向量机、神经网络、决策树、随机森林中进行预测,将四种结果实行少数服从多数的投票机制,得出最终预测结果,将其结果与v的结果比较分析。
101、有益效果:
102、1)提出了一种基于支持向量机、神经网络、决策树、随机森林的投票机制的乳房癌诊断与预测方法,以少数服从多数的投票机制,有效减少判错率,准确性高,有较好的泛化性和健壮性。系统聚类,将30个自变量分成若干类别,对每一个类别做偏相关分析找到类别的代表,最后进行类别代表和因变量的灵敏度分析,得到紧密度的平均值、光滑度的标准差、凹陷度的标准差和面积的最坏值能够代表其他特征变量,且与因变量肿瘤类型有密切关系。
103、2)通过仿真分析,验证该乳房癌诊断与预测的方法,验证了该方法具有上述优势。
104、3)将其应用于乳房癌诊断与预测的实际场景中,减少模型训练成本,实现了特征数少而区分又很好的乳房癌诊断。
105、本发明在现有技术单手段诊断预测容易出现预测出错以及模型训练成本高昂的问题背景下,提出了一种基于支持向量机、神经网络、决策树、随机森林的投票机制的乳房癌诊断与预测方法,将四种方法的预测结果实行少数服从多数的投票机制,同时采用系统聚类筛选主要特征属性,减少模型训练成本,实现了特征数少而区分又很好的乳房癌诊断。
- 还没有人留言评论。精彩留言会获得点赞!