含能分子人工智能设计方法与流程
本发明涉及含能分子设计,特别是一种含能分子人工智能设计方法。
背景技术:
1、分子设计的本质是在化学空间中进行候选分子采样,含能分子结构设计,既要考虑骨架和基团因素,又要兼顾分子结构对其它方面产生的潜在影响(如分子三维轮廓、晶体结构等多层级结构和力学强度、吸湿性等应用特性),因此是一个多维度空间采样问题。据科学家估计,小分子的化学空间包含1060-1080个化学结构,即使将元素组成限定为chon,仍然是一个天文数字。如何建立一种高效率的分子结构采样策略,在近乎无限大的化学空间中快速获取有效的候选分子,是含能分子设计面临的首要关键问题。
2、近年来,随着人工智能和大数据技术的快速发展,生物信息学与材料信息学领域先后兴起了基于机器主动学习的自适应设计(adaptive des ign,ad)技术。ad可实现性能预测模型和分子结构生成策略的双重优化,避免在非预期化合物的计算和实验上投入时间和资源,大幅提升了新物质发现的速度。含能分子具有生命科学和材料科学的共性特征,即研究对象都是由原子和化学键组成的分子或晶体,因此可以将ad技术引入到含能分子研究中,拓展含能分子设计的思路。发展基于ad的含能分子研究,有望在获得高精度性能预测模型的同时探索得到新的含能分子候选物,从而能充分发挥理论计算在含能分子研究中的作用,提升研制效率。
技术实现思路
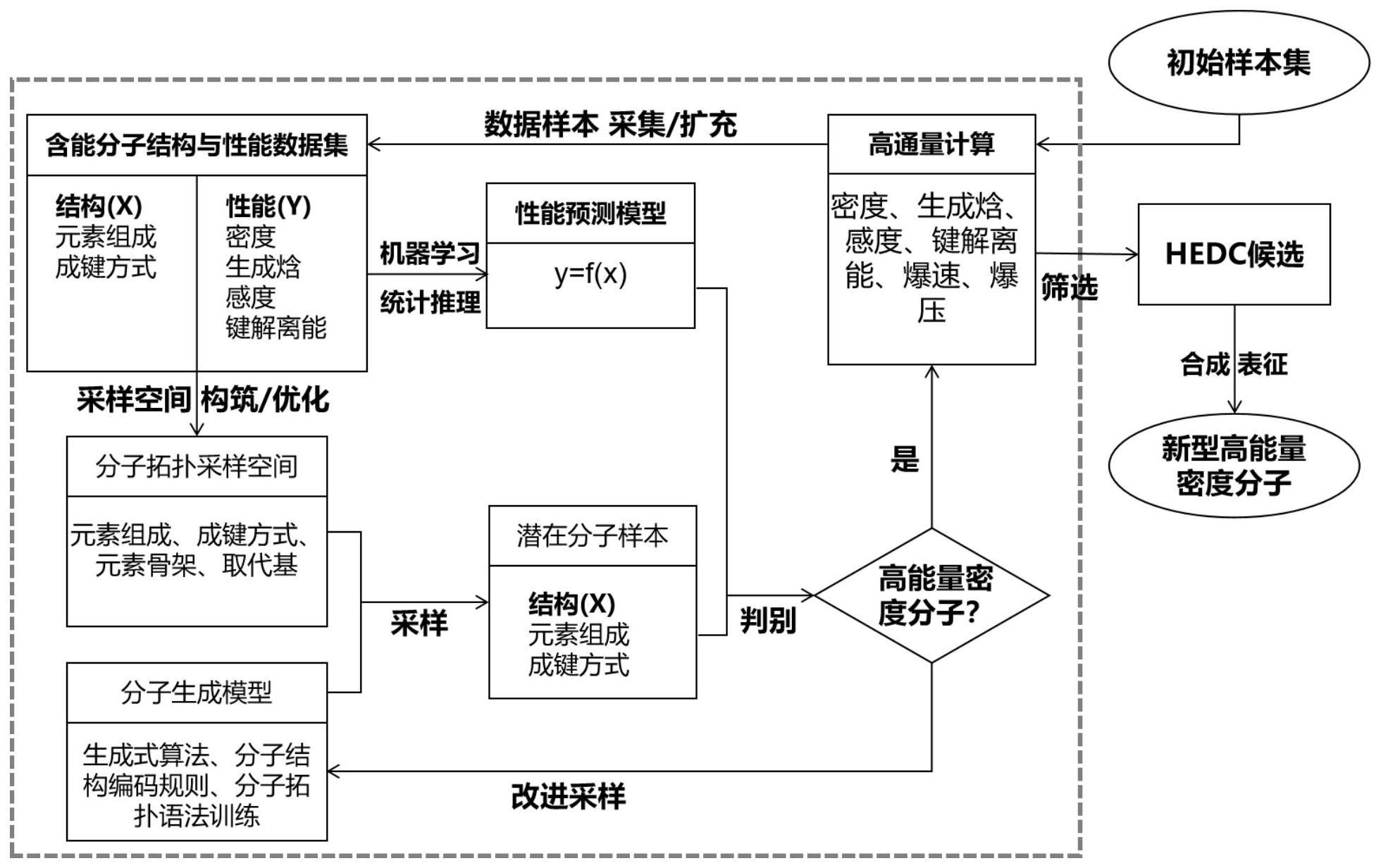
1、为解决现有技术中存在的问题,本发明的目的是提供一种含能分子人工智能设计方法,本发明构建出由性能反推分子结构的分子生成模型,从模型生成的分子中选取综合性能靠前的用于扩充训练集的样本,然后通过新的训练改进分子生成模型。由此建立“训练-生成-训练……生成”的自适应循环,使分子结构的采样向预期改进最大化的方向发展,最终实现以有限的资源快速发现潜在的新型含能分子。
2、为实现上述目的,本发明采用的技术方案是:一种含能分子人工智能设计方法,包括以下步骤:
3、步骤1、构建含能分子初始样本集,由高通量计算引擎获得含能分子的本征性质,在此基础上构建含能分子结构与性能数据集;
4、步骤2、基于含能分子结构与性能数据集,通过学习或拟合建立性能预测的机器学习或统计推理的属性预测模型,用于执行分子属性预测与筛选的功能;
5、步骤3、基于结构与性能数据集的分子结构特征构筑分子拓扑的采样空间,用于训练分子生成式模型;
6、步骤4、由分子生成式模型生成潜在的含能分子样本,经属性预测模型判别后经由高通量计算进行性能验证,判别结果同时反馈给分子生成式模型以对其进行优化;
7、步骤5、对含能分子经性能筛选后,将性能合格的目标分子推荐合成,同时将计算结果用于数据样本的拓展;
8、步骤6、跳转步骤2并循环执行步骤2-步骤5,输出高能量密度候选物,其中分子生成式模型和属性预测预测模型在循环中分别进行优化。
9、作为本发明的进一步改进,在步骤2中,属性预测模型执行分子属性预测与筛选的功能具体如下:
10、使用有向消息传递神经网络提取分子表征,其中分子中原子和键的初始特征由rdkit化学信息学工具提取,对提取的原子和键特征由有向的消息传递神经网络进行聚合以得到整个分子的特征表示;顶点原子v的特征以xv表示,边特征表示为evw,n(v)是x原子的邻原子,t表示消息传递的迭代步骤,是当前节点的隐藏状态表示,则每个原子消息聚合过程为:
11、
12、
13、
14、键初始状态为顶点原子特征和键特征evw的拼接,wi是可学习矩阵;当消息聚合达到指定的阈值t次后,加和每个原子的消息并取均值得到整个分子的表征h,公式表达为:
15、
16、hv=relu(wa cat(xv,mv))
17、
18、最终,通过函数完成属性预测,f(·)是前馈神经网络,是预测值。
19、作为本发明的进一步改进,在步骤1中,构建含能分子初始样本集具体包括:
20、从公开的权威化学数据库和主流学术期刊中收集分子,将收集到的分子统一用rdki t工具包读取文件,生成mol对象,并对元素组分、结构、是否离子化合物的条件进行数据筛选,并保留仅含chon元素且含硝基的单分子结构分子和中性化合物分子,完成数据筛选后,将mol对象转化为正则smi les编码存入csv文本并保存。
21、作为本发明的进一步改进,在步骤2中,建立性能预测的机器学习或统计推理的属性预测模型具体包括:
22、从结构与性能数据集中进行性能筛选,得到多个带分子性能的数据集,每个数据集用于独立的属性预测模型训练,采用有向的消息传递神经网络对分子进行编码,将得到的编码经过前馈神经网络后得到分子属性,以此建立起分子结构-性质的qspr模型,并使用十则交叉验证对其进行训练,数据集划分比例为8:1:1。
23、作为本发明的进一步改进,在步骤3中,构筑分子拓扑的采样空间具体包括:
24、使用rdkit对分子进行裂解得到带环碎片,收集环结构采用分子对接方案与no2、nno2、cno2结构进行自由对接生成一批新分子,对分子进行化学可行性验证后,使用步骤2的属性预测模型对新分子进行性质预测,筛选性质排名前10%的分子用于分子生成式模型。
25、作为本发明的进一步改进,对分子进行化学可行性验证具体包括:
26、截取现有化合物库已有的硝基化合物中与硝基相连的骨架信息,保存骨架及其与硝基相连的位点信息,构建化学环境模式匹配库;将新生成的分子在化学环境模式匹配库中进行搜索,若新分子的硝基周边化学环境未能成功在化学环境模式匹配库中匹配,则表明分子无效,丢弃该分子。
27、作为本发明的进一步改进,在步骤4中,由分子生成式模型生成潜在的含能分子样本具体包括:
28、采用多次加载模型方案,对同一个分子生成模型进行多次加载,每次生成固定长度的字符,生成的字符以“\n”进行分割得到smiles序列,对序列进行语法验证以确保smiels序列的正确性,使用rdki t工具将序列转化为mol对象,对分子进行结构验证、去重、属性筛选后进行保存,当生成数量达到阈值时停止生成;使用步骤2的属性预测模型对分子的多种性质进行预测,将综合属性优异的分子筛选出来,将得到的分子进行量子化学计算以对预测结果进行验证以确保所得分子性能的正确性。
29、作为本发明的进一步改进,在步骤6中,分子生成式模型在循环中进行优化具体包括:
30、分子生成模型其训练集来源于初始样本集和新生成的分子,新生成的分子包括分子对接生成的优异分子和上次分子生成模型自身产生的优异分子,每一次循环,将上次所有的优异分子用于微调分子生成模型,在迭代过程中,数据规模逐渐扩大,分子性能也逐步优异,分子生成模型也逐渐具备只生成优异分子的能力。
31、本发明的有益效果是:
32、(1)通过分子对接方案,生成了一批综合属性优异的分子用于分子生成模型的训练,解决了用于机器学习模型初始训练集含能分子样本量稀缺、分子多样性低的问题;(2)基于机器学习的分子属性预测加快了分子的筛选过程,与传统的量子化学计算相比,极大的减少了计算资源和计算时间;(3)通过生成的分子反作用于生成式模型,多次对模型进行调整,调整后的模型不再生成一堆与关注属性无关的分子,直接生成了满足初步条件的分子,减少了分子存储成本和分子筛选成本,极大的提高了分子筛选的命中率;总的来说,本发明提供的分子设计流程能加快分子设计。
- 还没有人留言评论。精彩留言会获得点赞!