本发明涉及大数据循证医学系统领域,具体是一种基于大数据的优生智库及其评估方法。
背景技术:
1、循证医学(evidence-based medicine,ebm)是一种基于最新临床研究证据、临床经验和患者价值观的医学决策方法。它强调医疗决策应该依据科学研究的可靠证据,以及医生的临床经验和患者的价值观,从而更有效地提供医疗护理。
2、循证医学的主要步骤包括:
3、(1) 提出问题(ask): 在临床实践中遇到问题时,医生首先明确问题,定义问题的特点和关键要素。
4、(2) 获取证据(acquire): 医生从可靠的医学文献、临床试验和研究中获取最新的、可信的证据。这可能涉及对医学数据库进行检索和筛选。
5、(3) 评估证据(appraise): 医生对获取的证据进行评估,考虑研究方法的质量、样本规模、统计分析等,以确定证据的可靠性和适用性。
6、(4) 应用证据(apply): 根据评估后的证据,医生将适用的证据应用到具体患者的临床情况中,制定治疗计划。
7、(5) 评价效果(assess): 在治疗实施后,医生评估治疗效果,考虑患者的反应和改善程度,进一步调整治疗计划。
8、循证医学的核心理念是确保医疗决策基于最新、最可靠的临床研究证据,以最大程度地提供患者的安全和治疗效果。这种方法强调对证据的客观评估,避免基于偏见或经验主义进行医疗决策,从而推动医学实践的科学化和精细化。
9、而对于现有的循证医学系统,咨询前端上传数据,咨询后端通过上传的数据通过后端服务器进行检索,并给出相应的结果,而对于该过程不够智能化,使用者只能通过输入特定的参数而进行精确查找,而对于模糊的句段、参数等,只能通过使用者前期自行处理过滤,才能得到想要的结果,针对上述问题,现有的循证医学系统需要提供能够自动处理使用者输入的句段,提取其相应参数,并自动与其数据库内的评价结果进行匹配的功能。
技术实现思路
1、本发明的目的在于克服现有技术的不足,针对现有的循证医学系统对于咨询前端接收信息的能力不足的问题,结合大数据平台,提出一种基于大数据的优生智库系统及其评估方法,能够对咨询前端发出的句段数据进行处理,解析关键参数,并根据人工智能技术进行参数分类,再结合大数据平台及后端数据库,对所涉及的参数统一进行计算评估,得到评估结果。
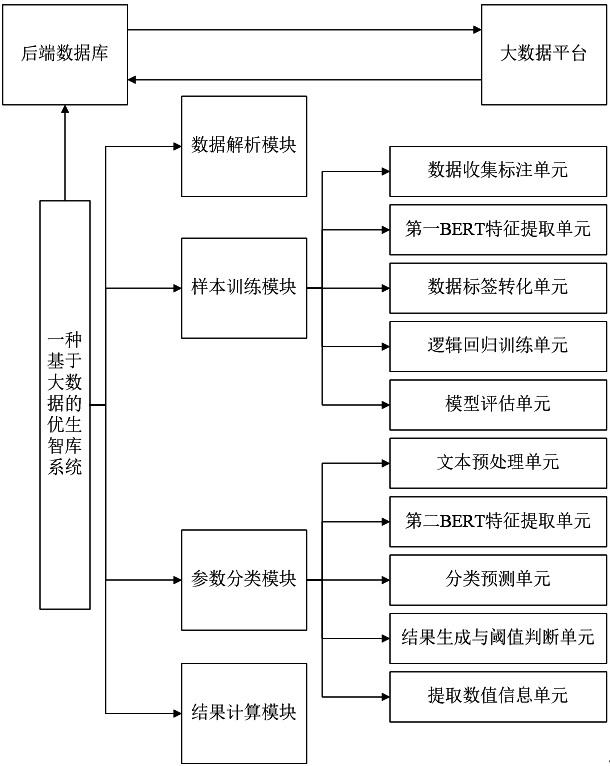
2、其中,一种基于大数据的优生智库系统,包括咨询前端和查询后端,所述咨询前端用于医护人员上传查询需求和查询需求所对应的查询数据;所述查询后端用于根据查询需求和查询数据,结合后端数据库,评断并发布结果,其中:
3、所述系统包括有对查询数据进行数据解析的数据解析模块,所述数据解析模块通过数据解析对查询数据进行识别和参数提取,其中,所述参数为所设定的参数计算方式中所需的参数;
4、所述系统包括有bert模型进行预先训练的样本训练模块,所述样本训练模块对样本数据训练,通过逻辑回归模型,将bert模型生成的特征作为输入,标签作为输出,进行模型训练;
5、所述系统包括有通过bert模型对参数进行分类的参数分类模块,所述参数分类模块通过训练后的bert模型对查询数据进行解析,并生成特征,通过分类器对特征进行分类预测,根据分类结果,对提取的参数进行分类识别;
6、所述系统包括有对分类识别的参数进行计算的结果计算模块,所述结果计算模块通过分类识别后的参数,结合后端数据库存储的计算算式,计算出相应的评价结果,并输出评价结果。
7、进一步的,所述后端数据库连接大数据平台,用于存储计算评价结果的计算算式及所涉及的参数,其中,所述后端数据库实时对所涉及的参数和计算算式进行更新,所涉及的参数的更新同步至数据解析模块、样本训练模块和参数分类模块。
8、进一步的,所述样本训练模块具体包括以下单元:
9、数据收集标注单元,用于收集包含参数的训练数据,并对训练数据中的参数进行标注,所述训练数据的样本包括输入的句段和对应的参数标签,其中,标签为二进制标签,用于表示参数是否出现在句段中,1表示参数存在,0表示参数不存在;
10、第一bert特征提取单元:用于通过加载的预训练bert模型,对训练数据中的每个句子进行编码,获得上下文感知的特征表示;其中,bert模型的输出为多层的transformer隐藏状态,该状态用于后续的特征提取;
11、数据标签转化单元:用于对于每个句段,根据标注的参数,将对应的参数设为正例,其他参数设为负例,构建训练集,其中,每个样本由输入特征和对应的标签组成;
12、逻辑回归训练单元:用于通过正例和负例的特征和标签训练逻辑回归分类器;
13、模型评估单元:用于通过验证集评估训练后的逻辑回归模型的性能,并根据评估结果进行调优,其中,所述性能至少包括准确率、精确率、召回率指标。
14、进一步的,所述逻辑回归训练单元通过逻辑回归二元分类算法,将线性特征组合并经过sigmoid函数进行预测类别概率,具体如下:
15、;
16、其中,所述表示样本属于正例的概率,所述、…分别表示特征向量的各个分量,所述、…分别表示逻辑回归模型的参数,所述表示特征,所述表示标签,所述表示数学常数。
17、进一步的,所述参数分类模块具体包括以下单元:
18、文本预处理单元,用于对输入文本进行预处理;
19、第二bert特征提取单元, 用于通过已加载的bert模型对输入文本进行编码,得到上下文感知的特征表示;
20、分类预测单元,将bert生成的特征输入到训练好的逻辑回归模型中,进行分类预测,逻辑回归模型返回每个类别的概率;
21、结果生成与阈值判断单元:用于对于每个参数,使用分类器预测的概率对参数是否存在进行判断,当预测概率超过阈值时,判定为参数存在;
22、提取数值信息单元:用于对于存在的参数,从输入文本中进一步提取数值信息。
23、作为优选的,提出一种基于大数据的优生智库的评估方法,该方法基于上述任一项所述的一种基于大数据的优生智库系统来实现,包括以下步骤:
24、s1. 通过数据解析对查询数据进行识别和参数提取,其中,所述参数为所设定的参数计算方式中所需的参数;
25、s2. 对样本数据训练,通过逻辑回归模型,将bert模型生成的特征作为输入,标签作为输出,进行模型训练;
26、s3. 通过训练后的bert模型对查询数据进行解析,并生成特征,通过分类器对特征进行分类预测,根据分类结果,对提取的参数进行分类识别;
27、s4. 通过分类识别后的参数,结合后端数据库存储的计算算式,计算出相应的评价结果,并输出评价结果。
28、进一步的,还包括步骤s5:后端数据库实时对所涉及的参数和计算算式进行更新,所涉及的参数的更新同步至系统。
29、进一步的,所述步骤s2具体包括以下子步骤:
30、s201. 收集包含参数的训练数据,并对训练数据中的参数进行标注,所述训练数据的样本包括输入的句段和对应的参数标签,其中,标签为二进制标签,用于表示参数是否出现在句段中,1表示参数存在,0表示参数不存在;
31、s202. 通过加载的预训练bert模型,对训练数据中的每个句子进行编码,获得上下文感知的特征表示;其中,bert模型的输出为多层的transformer隐藏状态,该状态用于后续的特征提取;
32、s203. 对于每个句段,根据标注的参数,将对应的参数设为正例,其他参数设为负例,构建训练集,其中,每个样本由输入特征和对应的标签组成;
33、s204. 通过正例和负例的特征和标签训练逻辑回归分类器;
34、s205. 通过验证集评估训练后的逻辑回归模型的性能,并根据评估结果进行调优,其中,所述性能至少包括准确率、精确率、召回率指标。
35、进一步的,所述步骤s204具体为:通过逻辑回归二元分类算法,将线性特征组合并经过sigmoid函数进行预测类别概率,具体如下:
36、;
37、其中,所述表示样本属于正例的概率,所述、…分别表示特征向量的各个分量,所述、…分别表示逻辑回归模型的参数,所述表示特征,所述表示标签,所述表示数学常数。
38、进一步的,所述步骤s3具体包括以下子步骤:
39、s301. 对输入文本进行预处理;
40、s302. 通过已加载的bert模型对输入文本进行编码,得到上下文感知的特征表示;
41、s303. 将bert生成的特征输入到训练好的逻辑回归模型中,进行分类预测,逻辑回归模型返回每个类别的概率;
42、s304. 对于每个参数,使用分类器预测的概率对参数是否存在进行判断,当预测概率超过阈值时,判定为参数存在;
43、s305. 对于存在的参数,从输入文本中进一步提取数值信息。
44、本发明的有益效果是:
45、(1) 本发明通过bert模型对查询数据进行解析,并生成特征,通过分类器对特征进行分类预测,根据分类结果,对提取的参数进行分类识别,使得咨询前端的使用者可输入任意数量、任意格式带有参数的句段,系统对句段进行处理后可得到对应的参数,并根据分类的参数通过后端数据库实现对应的评估结果;
46、(2) 通过本发明所提出的评估方法,使得咨询前端的使用者可不根据特定的评估结果而输入特定的参数,而是结合大数据平台及后端数据库,对所涉及的参数统一进行计算评估,得到评估结果。