一种基于机器学习的ICU患者脓毒症风险预测方法及系统与流程
一种基于机器学习的icu患者脓毒症风险预测方法及系统,用于脓毒症重要特征提取及风险发生预测,属于医学。
背景技术:
1、脓毒症被定义为宿主对感染的有害反应引起的致死性器官功能障碍,是重症监护病房(icu)患者高发病率和死亡率的主要疾病之一。全球icu成人脓毒症的发病率约为每10万人年58例,其中42%在出院前死亡,给其家庭和社会造成严重负担。脓毒症的特点是起病快,无特异的临床表现,进展快,累及多器官功能障碍,不易逆转。早期发现败血症有助于早期治疗,提高危重病人的生存率。
2、迄今为止,一些脓毒症的早期筛查工具被广泛用于icu住院患者,如系统性炎症反应综合征(sirs)标准、顺序器官衰竭评估(sofa)标准或快速sofa(qsofa)、国家预警评分(news)或改良的早期预警评分(mews)和logistic器官功能障碍(lods)评分。这些工具的诊断准确性差异很大,大多数具有较差的预测价值。拯救脓毒症运动2021年指南建议,与sirs、news或mews相比,由于qsofa评分的筛查效果不佳,不建议作为脓毒症或感染性休克的单一筛查工具。其中sirs标准对诊断脓毒症的特异性较低,许多住院患者符合sirs标准,包括那些没有发生感染的患者。qsofa评分仅包含三个变量,用于快速识别和评估疑似脓毒症患者。然而,qsofa评分仅在icu外患者群体中进行验证,不适用于已入住icu的患者。与sirs诊断标准相比,sofa评分以降低敏感性为代价缩小了脓毒症人群,由此产生的假阴性可能会延迟疾病的诊断。
3、此外,据报道,一些新的机器学习模型在脓毒症早期预测方面比传统的筛查工具有着更好的敏感性和特异性。目前哪种模型对icu患者的早期脓毒症预测效果最好尚无定论。此外,目前大多数机器学习的创新都集中在算法和数据集开发上,因此较少关注确保机器学习模型易于临床医生使用。ml模型的可重复性、可解释性和可比性是临床应用前必须面对的挑战。
4、综上所述,现有技术中存在如下技术问题:
5、1.现有的方法无法有效筛选出临床应用中脓毒症发生的全部重要特征,难以适用于在其他地区获取的icu患者数据集,需要后续继续训练及验证,从而造成适用难的问题;
6、2.无法准确预测icu患者脓毒症发生的风险。
技术实现思路
1、本发明的目的在于提供一种基于机器学习的icu患者脓毒症风险预测方法及系统,解决现有的方法无法准确的筛选出临床应用中脓毒症发生的重要特征。
2、为了实现上述目的,本发明采用的技术方案为:
3、一种基于机器学习的icu患者脓毒症风险预测方法,包括如下步骤:
4、步骤1:从数据库中获取全身感染或患败血症患者所对应的患者信息,并筛选符合分析条件的患者所对应的患者信息,并进行预处理;
5、步骤2:基于预处理后得到的患者信息构成的数据集对朴素贝叶斯、支持向量机和提升树进行训练,训练后分别得到对应的重要特征,并将各重要特征输入logistic回归模型,得到预测因子;
6、步骤3:基于预测因子构建列线图模型来预测icu患者脓毒症发生的风险。
7、进一步,所述步骤1中符合分析条件的患者所对应的患者信息是指排除未入院的患者、曾入住icu的患者、年龄小于16岁的患者后,所得到的患者所对应的患者信息,其中,患者信息包括基本信息、生命体征信息、其他信息,基本信息包括年龄、性别和种族,生命体征信息包括心率、平均血压、收缩压、舒张压、呼吸频率、体温、外周血氧饱和度、24h尿量,其他信息包括疾病评估和入院后24小时内首次测量的实验室检查结果,疾病评估包括急性生理学评分iii、序贯器官衰竭评估和logistic器官功能障碍评估,实验室检查结果包括红细胞压积、血红蛋白、血小板、白细胞、中性粒细胞绝对值计数、中性粒细胞比例、淋巴细胞、白蛋白、阴离子间隙、碳酸氢盐、血尿素氮、肌酐、葡萄糖、天冬氨酸氨基转移酶、丙氨酸氨基转移酶、碱性磷酸酶、总胆红素、国际标准化比值、凝血酶原时间和部分凝血活酶时间。
8、进一步,所述步骤1采用移除缺失值或采用k近邻插值的方式对符合条件的患者信息进行预处理。
9、进一步,所述步骤2将预处理后得到的数据集按照7:3的比例分为训练集和验证集并进行比较,比较后,若显著性概率p>0.05,则表示训练集和验证集分配随机性良好,能用于训练和验证,否则重新分配再进行比较,具体为:
10、采用非正态分布和正态分布的连续变量分别用中位数和平均值对训练集和验证集之间进行各变量的比较,其中,非正态分布的连续变量采用mann-whitney u检验进行比较,正态分布的连续变量采用学生t-检验;
11、采用pearson卡方检验比较训练集和验证集中的分类变量,其中,分类变量包括性别、种族和是否发生脓毒症。
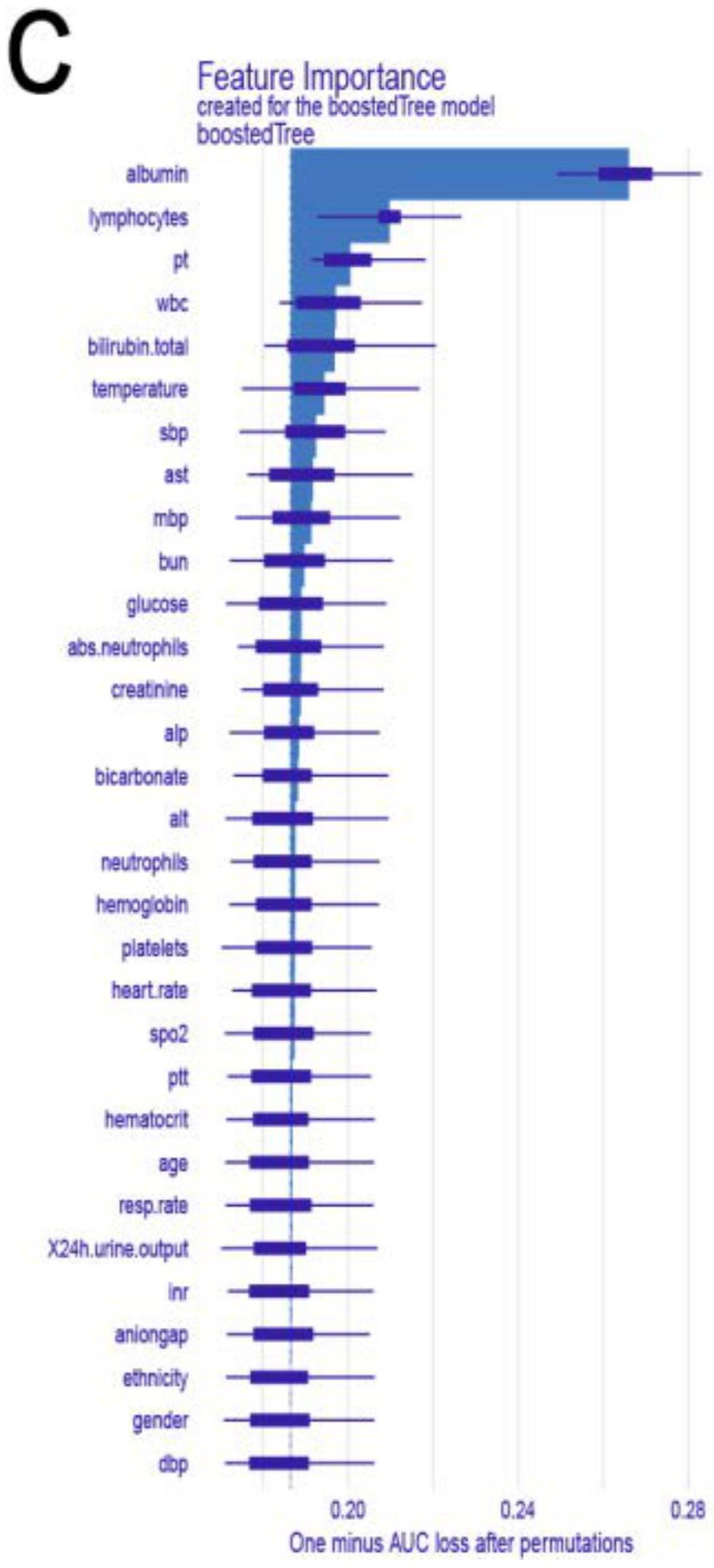
12、进一步,所述步骤2中,基于训练集训练朴素贝叶斯、支持向量机和提升树后,分别得到对应的重要矩阵,选择重要矩阵中排名前6位的变量作为重要特征;
13、训练后,朴素贝叶斯得到的重要特征为白蛋白、白细胞、总胆红素、体温、天冬氨酸氨基转移酶和淋巴细胞;
14、训练后,支持向量机得到的重要特征为白蛋白、白细胞、体温、淋巴细胞、总胆红素和收缩压;
15、训练后,提升树得到的重要特征为白蛋白、淋巴细胞、凝血酶原时间、白细胞、总胆红素和体温;
16、并将各重要特征输入logistic回归模型,得到的预测因子为白蛋白、白细胞、淋巴细胞、温度、总胆红素、凝血酶原时间和收缩压。
17、进一步,所述步骤3中,将预测因子输入列线图模型,得到预测概率阈值;
18、基于预测概率阈值建立列线图模型,并在试验组和验证集中通过采用roc曲线、偏置校准曲线和dca进行检验来检验列线图的性能,具体通过;若检验通过,基于列线图模型代入icu患者相应的指标进行icu患者脓毒症发生的风险预测,否则,列线图模型无效,断续更新数据集进行训练和验证。
19、一种基于机器学习的icu患者脓毒症风险预测系统,包括:
20、预处理模块:从数据库中获取全身感染或患败血症患者所对应的患者信息,并筛选符合分析条件的患者所对应的患者信息,并进行预处理;
21、因子预测模块:基于预处理后得到的患者信息构成的数据集对朴素贝叶斯、支持向量机和提升树进行训练,训练后分别得到对应的重要特征,并将各重要特征输入logistic回归模型,得到预测因子;
22、风险预测模块:基于预测因子构建列线图模型来预测icu患者脓毒症发生的风险。
23、进一步,所述预处理模块中符合分析条件的患者所对应的患者信息是指排除未入院的患者、曾入住icu的患者、年龄小于16岁的患者后,所得到的患者所对应的患者信息,其中,患者信息包括基本信息、生命体征信息、其他信息,基本信息包括年龄、性别和种族,生命体征信息包括心率、平均血压、收缩压、舒张压、呼吸频率、体温、外周血氧饱和度、24h尿量,其他信息包括疾病评估和入院后24小时内首次测量的实验室检查结果,疾病评估包括急性生理学评分iii、序贯器官衰竭评估和logistic器官功能障碍评估,实验室检查结果包括红细胞压积、血红蛋白、血小板、白细胞、中性粒细胞绝对值计数、中性粒细胞比例、淋巴细胞、白蛋白、阴离子间隙、碳酸氢盐、血尿素氮、肌酐、葡萄糖、天冬氨酸氨基转移酶、丙氨酸氨基转移酶、碱性磷酸酶、总胆红素、国际标准化比值、凝血酶原时间和部分凝血活酶时间;
24、所述预处理模块采用移除缺失值或采用k近邻插值的方式对符合条件的患者信息进行预处理。
25、进一步,所述因子预测模块将预处理后得到的数据集按照7:3的比例分为训练集和验证集并进行比较,比较后,若显著性概率p>0.05,则表示训练集和验证集分配随机性良好,能用于训练和验证,否则重新分配再进行比较,具体为:
26、采用非正态分布和正态分布的连续变量分别用中位数和平均值对训练集和验证集之间进行各变量的比较,其中,非正态分布的连续变量采用mann-whitneyu检验进行比较,正态分布的连续变量采用学生t-检验;
27、采用pearson卡方检验比较训练集和验证集中的分类变量,其中,分类变量包括性别、种族和是否发生脓毒症;
28、所述因子预测模块中,基于训练集训练朴素贝叶斯、支持向量机和提升树后,分别得到对应的重要矩阵,选择重要矩阵中排名前6位的变量作为重要特征;
29、训练后,朴素贝叶斯得到的重要特征为白蛋白、白细胞、总胆红素、体温、天冬氨酸氨基转移酶和淋巴细胞;
30、训练后,支持向量机得到的重要特征为白蛋白、白细胞、体温、淋巴细胞、总胆红素和收缩压;
31、训练后,提升树得到的重要特征为白蛋白、淋巴细胞、凝血酶原时间、白细胞、总胆红素和体温;
32、并将各重要特征输入logistic回归模型,得到的预测因子为白蛋白、白细胞、淋巴细胞、温度、总胆红素、凝血酶原时间和收缩压。
33、进一步,所述风险预测模块中,将预测因子输入列线图模型,得到预测概率阈值;
34、基于预测概率阈值建立列线图模型,并在试验组和验证集中通过采用roc曲线、偏置校准曲线和dca进行检验来检验列线图的性能,具体通过;若检验通过,基于列线图模型代入icu患者相应的指标进行icu患者脓毒症发生的风险预测,否则,列线图模型无效,断续更新数据集进行训练和验证。
35、与现有技术相比,本发明的优点在于:
36、一、本发明采用三种机器学习方法筛选出临床应用中脓毒症发生的重要特征,并将重要特征输入训练后的logistic回归模型得到精确的预测因子,便于后续能精确的预测脓毒症的发生风险;
37、二、本发明与传统评估脓毒症的sofa评分、lods评分相比,该列线图的auc更高,预测脓毒症的性能更强。
- 还没有人留言评论。精彩留言会获得点赞!