一种基于指定属性生成分子的方法与流程
本发明涉及药物分子生成模型,特别是涉及一种基于指定属性生成分子的方法。
背景技术:
1、在过去的几十年中,计算机科学从无到有,逐渐融入了药物研发的领域,从最初的数据录入发展为辅助药物的设计,计算机辅助药物设计(computer-aided drug design,cadd)由此出现。尽管cadd技术在一些特定任务上表现出色,如药物分子的虚拟筛选,但在药物分子的设计和优化方面仍然面临一些挑战,随着技术进一步发展,人工智能逐渐成为这个问题的最优解。
2、ai制药,是以医药大数据为基础,通过运用机器学习、深度学习等ai技术替代大量实验,对药物结构、功效等进行快速分析,以达到短时、低成本开发新药目的的技术手段。与传统计算机辅助药物设计相比,ai技术能够快速识别药物靶点,从数据库中匹配合适分子,设计、合成化合物并预测药物代谢性质和理化性质,可大大缩短药物研发时间、降低研发成本并提高成功率。在人工智能发展的大背景下,预训练模型的出现和应用,再一次缩短了这一进程。
3、标注数据集、算法模型和算力是ai制药中必不可少的组成部分,也是目前分子生成面临的主要挑战的来源:
4、数据方面:高质量数据获取门槛高,制约影响明显。药物研发企业数据来源可分为公开数据和非公开数据,公开数据容易获取,但数据质量难以保证,据此进行的模型运算可靠性不足。非公开数据主要是各制药公司以往项目的积累,此类数据的精度高,但由于数据属于医药公司的核心资产,极难获得。
5、算法方面:算法与应用场景匹配要求度高。ai药物研发中算法模型的优势可以体现结果的精准度、计算速度、模型体量、泛化性能等,不同预训练模型可能有不同的侧重方向,因此优势也会不尽相同,在特定任务需求和应用场景下合理选择具有相应优势的预训练模型。
6、算力方面:微调模型可能需要大量的计算资源,尤其是在需要调整模型架构和参数时。这可能限制了方法的实际应用。
7、目前,我国ai药物研发主要应用于药物发现环节和临床前研究环节,受生物系统内在复杂性和疾病异质性特征的制约,ai技术尚不能为药物研发的效率和成功率带来革命性改变,整体仍处于探索阶段。未来,随着算法的更新、算力的突破及大数据的发展,ai技术将深入应用到新药研发的各个环节,在化合物合成、药效预测及自动化研发等阶段扮演越来越重要的角色。
技术实现思路
1、本发明目的是针对背景技术中存在的问题,提出一种基于指定属性生成分子的方法。模型将预训练模型引入药物分子生成中,通过对预训练模型的微调,将深度学习引入到分子生成的领域,从而显著加快药物研发进程。
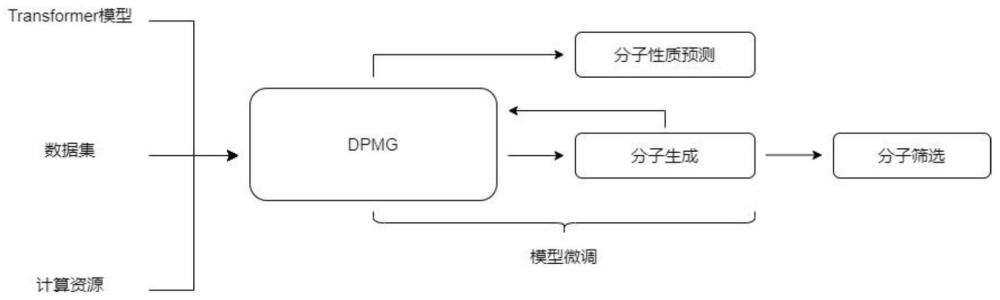
2、本发明的技术方案,1、一种基于指定属性生成分子的方法,包括以下具体步骤:
3、s1、收集药物小分子数据,针对分子生成任务制作数据集;
4、s2、建立基于预训练和模型微调的分子生成模型;
5、s3、使用s1中制作的数据集对分子生成模型进行微调训练得到两个不同的适用于分子生成下游任务的模型;
6、s4、基于分子属性预测和指定属性的目标分子生成分别对下游任务dpmg模型结构进行调整;
7、s5、对所获得的分子进行筛选;
8、s6、提出评价分子生成的指标,量化模型质量。
9、小分子结构的表述形式包括线性输入的smiles和二维无向循环图;
10、其中,s1中收集的药物小分子数据包括公开数据和实验产出数据,所收集数据的规模达到千万量级;
11、将收集到的药物分子数据制作成表格形式,包括分子的smiles表达式,脂水分配系数、药物亲和力、合成可及性;并使用rdkit工具过滤出合理的分子。
12、优选的,本发明使用文本化的smiles作为输入模型的数据;
13、所收集的smiles表达式和相应分子的属性还包括溶解率和渗透率估计、分子质量,拓扑极性表面积、氢键供受体数量、警报结构数量、可旋转体数量;
14、其中根据脂水分配系数、药物相似性定量估计、合成可及性三种分子属性生成目标为具有与指定这三个属性的值相同值的分子;
15、或指定溶解率和渗透率估计、分子质量、拓扑极性表面积、氢键供受体数量、警报结构数量、可旋转体数量六种属性中的一种或多种组合。
16、优选的,本模型需要在指定相应的属性基础上生成药物分子,为了确保神经网络能够辨认出各个属性和分子结构以及smiles文本信息之间的关系,因此s1中针对同一分子结构的不同属性制作不同的数据集,从而保证神经网络学习关联信息的能力。
17、s3的预训练过程中在同一个语义空间内采用了12层transformer,768个隐藏层和12个注意力箭头对文本数据进行编码操作;
18、其中,通过指定注意力箭头的指向对文本顺序信息和分子结构信息进行学习。
19、s4中在分子属性预测过程中,分子生成结束后,生成的分子作为输入进入dpmg模型,对分子的其余属性进行预测,补全分子的所有属性;在得出结果后会与先前给出的属性进行比较,计算预测的偏差程度;
20、本分子属性预测过程中使用回归模型作为结尾,得到一个数值,并采用mse作为损失函数:
21、对于均方差损失,其一般式为:
22、
23、上述公式中,yi为真实测量值,为模型预测值,在回归模型中,令其损失函数表达为:
24、
25、训练的目标函数即为寻找下列函数的最小值时a,b的取值:
26、
27、s4中指定属性的目标分子生成过程中根据给出的属性参数生成符合要求的药物分子;
28、将分子属性的数值输入编码器,将编码器中的得到的word embedding输入解码器,得到输出的smiles文件;
29、输出的过程中,引入教师模型,每生成一个原子,将已有的smiles部分与作为参考的正确的smiles分子文件作对比,完成训练模型的微调操作;
30、在每一个原子与参考smiles文件比对完成后,将参考smiles文件作为下一轮生成原子的前置条件,每生成一个原子,就会通过比对计算损失值,通过反向传播来微调参数。
31、数据在计算损失函数时采用二元交叉熵作为损失函数:
32、
33、
34、数据集呈现出data=(x1,y1)(x2,y2)(x3,y3)(x4,y4)……的样式,其中,是输入变量,也即模型中生成的一个字符,是观测值,也就是期待模型的输出,在这里我们令y取0或1,当y=1的概率为θ时,即pθ(y=1)=θ时,这些数据点被观察到的对数似然可以被上式表示,此时似然函数l(θ)就是目标函数;
35、若在它前面加上负号,即转变成损失函数,该损失函数即为yi与θ的交叉熵;
36、对单个样本的交叉熵形式的损失函数:
37、loss=-[yilogp+(1-yi)log(1-p)]
38、yi是第i个样本的观察值,p为预测的概率。
39、优选的,s5中对基于qed与sascore多所生成的分子基本的类药性进行初步过滤。
40、优选的,s6中使用moses与guacamol对药物分子进行打分,并对分子结构的合理性进行筛选;
41、其中,
42、生成分子合理性:分子的合理性指的是分子的结构、性质和设计是否与预期的生物学活性或药物性质相符合,是否符合化学、生物学和药物学的基本规律,是否对应于真实的分子;如若分子结构为smiles,使用rdkit工具包的molfromsmiles方法,检验其是否能从smiles格式转换为rdmol对象,若可以,即为合理分子。
43、与现有技术相比,本发明具有如下有益的技术效果:
44、1、本发明根据所需要的药物分子的属性进行生成,简洁明了,便于理解和操作。
45、2、本发明深度学习生成指定属性的分子并非都符合其他要求,在传统方法流程中,筛选与优化的环节需要经历多轮实验和计算模拟,通过在生成完成后加入能根据指定条件来进行筛选的小型神经网络,达到加快筛选过程,减少模拟和实验的工作量的目的。
46、3、本发明由于预训练任务针对的是海量无标签数据,对于模型参数量的需求较大,导致模型训练所需资源、时间变长。本发明,通过在训练完成的预训练模型上进行微调参数来实现对下游任务的适配,从而缩减训练大型模型的计算成本。
- 还没有人留言评论。精彩留言会获得点赞!