一种能够保护患者隐私的智能医疗联邦学习方法和装置与流程
本发明涉及智能医疗,具体为一种能够保护患者隐私的智能医疗联邦学习方法和装置。
背景技术:
1、深度学习在电子健康记录(ehr)上的应用已被广泛且成功地应用于一系列目标,例如疾病风险预测、诊断支持,为了利用深度学习模型对ehr数据固有的高维度的预测能力,需要大量样本,采样不足或过度指定的模型更有可能在训练数据集上过度拟合,并且在应用于新数据集时泛化能力较差,单个医疗机构通常没有足够的能力和数据来开发预测模型,实现更复杂和更准确的模型的一种解决方案是增加可用的训练数据,这个一般通过志愿者采集更多的数据,另一种选择是机构之间数据共享,但监管带来的法律问题,例如隐私保护问题,限制了机构之间广泛的数据共享;
2、而联邦学习(fl)是支持跨站点协作学习同时最大限度地减少隐私问题的一种解决方案,fl是一种分布式机器学习方法,使多个站点能够协作训练模型,同时保持数据本地化,该过程涉及站点与中央服务器共享本地训练的模型参数,然后中央服务器聚合这些参数以创建全局模型,这个过程会重复多次训练,直到获得最终的全局模型,这些参数通过常用算法联合平均(fedavg)进行聚合,该算法使用样本大小加权平均来组合模型参数。
3、当前,联合学习(fl)是一种常用的机器学习方法,使多个组织在能够训练模型的同时,无需与中央服务器共享数据,然而,如果训练的数据样本是非同一独立分布(non-iid)的,那么fl的性能会显着下降,特别在智能医疗方面,患者群体的差异极大,导致了医院之间的样本数据分布差异,个性化fl通过考虑站点特定的分布差异来解决此问题,一般采用聚类fl的方法,通过将医院内的患者分组,并在每个组上训练单独的模型来解决此问题,技术上确实可行,但是在隐私保护问题上,仍然是一个问题,因为聚类过程需要交换患者级别的信息,fl的初衷就是每个组织独立训练,无需共享数据,当前的通用方法,是使用聚合后的数据,重新分成不同的组,但这个解决方案会导致分组不准确,以及性能下降。
4、于是,有鉴于此,针对现有的结构及缺失予以研究改良,提出一种能够保护患者隐私的智能医疗联邦学习方法和装置。
技术实现思路
1、针对现有技术的不足,本发明提供了一种能够保护患者隐私的智能医疗联邦学习方法和装置,解决了上述背景技术中提出的问题。
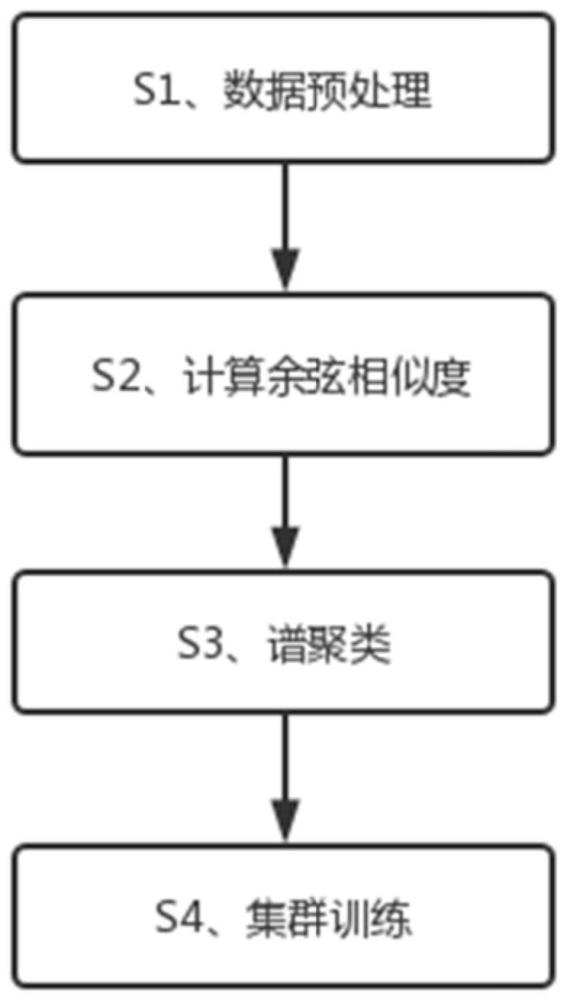
2、为实现以上目的,本发明通过以下技术方案予以实现:一种能够保护患者隐私的智能医疗联邦学习方法,所述能够保护患者隐私的智能医疗联邦学习方法包括下述操作步骤:
3、s1、数据预处理:
4、训练编码器来创建嵌入向量,联合自动编码器以获得每个特征域的潜在变量,潜在变量连接起来形成患者嵌入向量;
5、s2、计算余弦相似度:
6、采用smpc协议计算嵌入向量之间的余弦相似度,smpc使用秘密共享方案来联合计算向量对之间的点积;
7、s3、谱聚类:
8、使用由嵌入的成对余弦相似度生成的相似度矩阵对患者进行聚类;
9、s4、集群训练:
10、基于集群到fl训练,每个模型都在每个集群单独训练。
11、进一步的,所述步骤s1中,嵌入向量是将一个高纬度向量嵌入到低纬度的空间中。
12、进一步的,所述步骤s1中,数据预处理的具体操作如下:
13、采用一个6层的全连接网络结构,包括一个三层编码器和一个相同的三层解码器来创建患者嵌入,为了减少过度拟合,30%的特征在训练过程中被随机破坏,即30%的特征被强制为0,为每个特征域训练了一个单独的自动编码器,隐藏层中使用relu作为激活函数,在最终输出层中使用sigmoid作为激活函数,损失函数为mse,使用学习率为1e-3且batch大小为32的adam优化器,汇总来说,输入是一个患者的所有特征,生成的嵌入向量连接了所有潜在的用户特征。
14、进一步的,所述特征域包括药物、诊断和体检。
15、进一步的,所述步骤s2中,smpc是一种加密技术,允许各方共同计算其输入的函数,同时保持输入秘密,即仅提供输出。
16、进一步的,所述步骤s2中,smpc通过数学保证保护隐私免受外部对手和其他相关方的侵害,并允许精确计算站点之间的余弦相似度,使用秘密共享计算跨站点的点积建立对手模型,主要包括以下步骤:
17、嵌入向量的维度为d,site1上有数据集a(维度n1xd),site2上有数据集b(维度n2xd),ni表示样本的数量;
18、步骤一:创建一个随机的长宽是dxd的可逆矩阵m,采用reed-hoffman编码,将m发送给site1,然后将m-1发送给site2;
19、步骤二:每个站点上,将他们的数据集划分成子矩阵,然后用m或者m-1来进行掩码操作;
20、步骤三:被掩码操作后的子矩阵,在站点之间共享;
21、步骤四:被掩码操作后的子矩阵用来生成最终的矩阵点积;
22、进一步说明以上步骤,
23、站点1计算a1=a×mleft,a2=a×mright,然后将a1发给服务器;
24、站点2计算然后将b2发给服务器;
25、服务器将b2发给站点1,将a1发给站点2;
26、站点1计算va=a2×b2,然后将va发给服务端;
27、站点2计算vb=a1×b1,然后将vb发给服务端;
28、理论分析如下面公式:
29、
30、公式说明了m的具体值并不影响最终的计算结果,只要m是可逆的矩阵即可,将a拆分成了左右两个部分;
31、b拆分成了上下两个部分即b1和b2,对应以上公式的下标left、right、top、bottom。
32、进一步的,所述步骤四中,在计算点积之前,所有嵌入向量首先经过l2归一化,因此该乘积相当于余弦相似度。
33、进一步的,所述步骤s3中,进行聚类时,首先基于wcss计算簇1-10的簇内平方和,wcss是衡量集群紧凑性的指标,再使用elbow point选择绘图的“肘”点,在此之后额外的簇不会导致wcss的实质性改进即簇的紧凑性,由此用于确定解释数据集中方差所需的最小簇数,小的wcss意味着数据点更加紧凑,表明相似点的聚类更加紧密,并选择3个集群,具体选择数量根据实际需求调整。
34、进一步的,所述步骤s4中,fl指的是联邦学习,其是一种分布式机器学习方法,使多个站点能够协作训练模型,同时保持数据本地化。
35、一种装置,该装置为服务器,所述服务器应用有如上所述的能够保护患者隐私的智能医疗联邦学习方法。
36、本发明提供了一种能够保护患者隐私的智能医疗联邦学习方法和装置,具备以下有益效果:
37、该能够保护患者隐私的智能医疗联邦学习方法和装置,对于数据的预处理方法和调度策略保证了用户的数据隐私,在达到模型训练的功能需求的同时,不同的站点之间,无法看到其他站点的个人信息,解决了联合学习中非iid数据和患者隐私保护的问题,本案用icu数据预测病人死亡情况,可以扩展到其他表型分析任务。
- 还没有人留言评论。精彩留言会获得点赞!