基于基因检测的疾病风险筛查方法及系统与流程
本发明涉及数据处理领域,尤其涉及一种基于基因检测的疾病风险筛查方法及系统。
背景技术:
1、近年来,机器学习和人工智能技术在生物信息学领域得到了广泛应用,特别是在基因组数据分析中。利用这些先进的计算技术,可以有效地处理和分析大规模的基因组数据,识别出与疾病相关的复杂遗传模式。
2、现有方案常常受限于处理速度慢、准确度不高或无法处理复杂遗传模式的问题。因此,如何从大量的基因序列数据中准确提取出与特定疾病相关的风险因素,仍然是一个挑战。
技术实现思路
1、本发明提供了一种基于基因检测的疾病风险筛查方法及系统,用于提高基因检测的疾病风险筛查准确率。
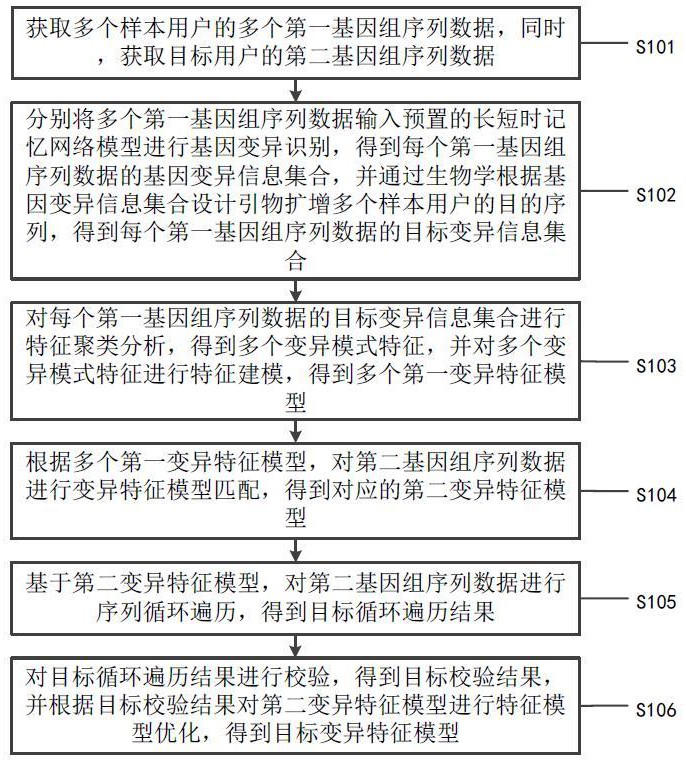
2、本发明第一方面提供了一种基于基因检测的疾病风险筛查方法,所述基于基因检测的疾病风险筛查方法包括:获取多个样本用户的多个第一基因组序列数据,同时,获取目标用户的第二基因组序列数据;分别将所述多个第一基因组序列数据输入预置的长短时记忆网络模型进行基因变异识别,得到每个第一基因组序列数据的基因变异信息集合,并通过生物学根据所述基因变异信息集合设计引物扩增所述多个样本用户的目的序列,得到每个第一基因组序列数据的目标变异信息集合;对每个第一基因组序列数据的目标变异信息集合进行特征聚类分析,得到多个变异模式特征,并对所述多个变异模式特征进行特征建模,得到多个第一变异特征模型;根据所述多个第一变异特征模型,对所述第二基因组序列数据进行变异特征模型匹配,得到对应的第二变异特征模型;基于所述第二变异特征模型,对所述第二基因组序列数据进行序列循环遍历,得到目标循环遍历结果;对所述目标循环遍历结果进行校验,得到目标校验结果,并根据所述目标校验结果对所述第二变异特征模型进行特征模型优化,得到目标变异特征模型。
3、结合第一方面,在本发明第一方面的第一种实现方式中,所述获取多个样本用户的多个第一基因组序列数据,同时,获取目标用户的第二基因组序列数据,包括:获取多个样本用户的多个第一核苷酸序列数据,并获取目标用户的第二核苷酸序列数据;创建核苷酸编码集合,所述核苷酸编码集合包括:腺嘌呤a=[1,0,0,0]、胞嘧啶c=[0,1,0,0]、鸟嘌呤g=[0,0,1,0]和胸腺嘧啶t=[0,0,0,1];分别对所述多个第一基因组序列数据以及所述第二基因组序列数据进行序列数据切片,得到每个第一基因组序列数据的n个第一切片序列数据以及所述第二基因组序列数据的n个第二切片序列数据;基于所述核苷酸编码集合,对所述n个第一切片序列数据进行序列编码和编码融合,得到对应的多个第一基因组序列数据,并对所述n个第二切片序列数据进行序列编码和编码融合,得到对应的第二基因组序列数据。
4、结合第一方面,在本发明第一方面的第二种实现方式中,所述分别将所述多个第一基因组序列数据输入预置的长短时记忆网络模型进行基因变异识别,得到每个第一基因组序列数据的基因变异信息集合,并通过生物学根据所述基因变异信息集合设计引物扩增所述多个样本用户的目的序列,得到每个第一基因组序列数据的目标变异信息集合,包括:分别将所述多个第一基因组序列数据输入预置的长短时记忆网络模型,所述长短时记忆网络模型包括第一长短时记忆层、第二长短时记忆层、全连接层以及输出层;通过所述第一长短时记忆层,对每个第一基因组序列数据进行低层次特征提取,得到每个第一基因组序列数据的低层次序列特征;通过所述第二长短时记忆层,对所述低层次序列特征进行高维特征转换和特征组合,得到每个第一基因组序列数据的目标输出特征;通过所述全连接层对所述目标输出特征进行预测输出转换,得到每个第一基因组序列数据的预测输出特征;通过所述输出层中的softmax函数,对所述预测输出特征进行特征基因变异分类,得到每个第一基因组序列数据的基因变异分类结果;对所述基因变异分类结果进行变异信息整合,得到每个第一基因组序列数据的基因变异信息集合,并通过生物学根据所述基因变异信息集合设计引物扩增所述多个样本用户的目的序列,得到每个第一基因组序列数据的目标变异信息集合。
5、结合第一方面,在本发明第一方面的第三种实现方式中,所述对每个第一基因组序列数据的目标变异信息集合进行特征聚类分析,得到多个变异模式特征,并对所述多个变异模式特征进行特征建模,得到多个第一变异特征模型,包括:对每个第一基因组序列数据的目标变异信息集合进行信息提取,得到每个第一基因组序列数据的变异类型信息、变异位置信息以及变异频率信息;对所述变异类型信息、所述变异位置信息以及所述变异频率信息进行变异特征关联关系识别,得到变异特征关联关系;根据所述变异特征关联关系确定对应的多个初始聚类中心,并将所述基因变异信息集合输入预置的特征聚类分析模型;通过所述特征聚类分析模型,根据所述多个初始聚类中心对所述基因变异信息集合进行特征聚类,得到每个初始聚类中心的第一特征聚类结果;根据所述第一特征聚类结果,对所述多个初始聚类中心进行聚类中心校正,得到多个目标聚类中心;根据所述多个目标聚类中心对所述基因变异信息集合进行聚类分析,得到多个第二特征聚类结果,并对所述多个第二特征聚类结果进行变异模式解析,得到多个变异模式特征;采用随机森林算法,分别对每个变异模式特征进行特征标准化建模,得到多个第一变异特征模型。
6、结合第一方面,在本发明第一方面的第四种实现方式中,所述根据所述多个第一变异特征模型,对所述第二基因组序列数据进行变异特征模型匹配,得到对应的第二变异特征模型,包括:对所述第二基因组序列数据进行特征初步检测,得到第一特征标识信息;根据所述多个变异模式特征,分别创建每个第一变异特征模型的第二特征标识信息;对所述第一特征标识信息进行向量转换,得到第一特征标识向量,并对所述第二特征标识信息进行向量转换,得到第二特征标识向量;对所述第一特征标识向量与所述第二特征标识向量进行欧氏距离计算,得到每个第一变异特征模型的目标欧式距离;根据所述目标欧式距离对所述多个第一变异特征模型进行模型最优化选取,得到对应的第二变异特征模型。
7、结合第一方面,在本发明第一方面的第五种实现方式中,所述基于所述第二变异特征模型,对所述第二基因组序列数据进行序列循环遍历,得到目标循环遍历结果,包括:通过所述第二变异特征模型按照预设方向和预设第一编码长度,对所述第二基因组序列数据进行移动检测,得到移动检测结果;通过所述移动检测结果进行下一轮编码长度分析,得到第二编码长度,并通过所述第二变异特征模型,根据所述第二编码长度进行下一轮移动检测,直至所述第二基因组序列数据遍历完成,得到多个移动检测结果;判断所述多个移动检测结果是否满足预设退出条件;若不满足,则通过所述第二变异特征模型,对所述第二基因组序列数据进行序列循环遍历,生成目标循环遍历结果;若满足,则对所述多个移动检测结果进行结果综合分析,得到目标循环遍历结果并输出。
8、结合第一方面,在本发明第一方面的第六种实现方式中,所述对所述目标循环遍历结果进行校验,得到目标校验结果,并根据所述目标校验结果对所述第二变异特征模型进行特征模型优化,得到目标变异特征模型,包括:定义多个校验规则,并对所述多个校验规则进行集合转换,得到校验规则集合;根据所述校验规则集合对所述目标循环遍历结果进行校验,得到每个校验规则对应的初始校验结果;对每个校验规则对应的初始校验结果进行结果归集,得到目标校验结果;根据所述目标校验结果对所述第二变异特征模型进行模型参数范围确定,得到多个模型参数范围;通过所述多个模型参数范围,对所述第二变异特征模型进行随机初始值生成,得到对应的随机初始值集合,并通过预置的反向粒子传播算法对所述随机初始值集合进行粒子种群构建,得到粒子种群;对所述粒子种群进行粒子适应度计算,得到所述粒子种群对应的粒子适应度集合,同时,对所述粒子适应度集合进行迭代计算,直至满足预设条件时,生成所述粒子种群对应的最优解;通过所述最优解对所述第二变异特征模型进行特征模型优化,得到目标变异特征模型。
9、本发明第二方面提供了一种基于基因检测的疾病风险筛查系统,所述基于基因检测的疾病风险筛查系统包括:获取模块,用于获取多个样本用户的多个第一基因组序列数据,同时,获取目标用户的第二基因组序列数据;识别模块,用于分别将所述多个第一基因组序列数据输入预置的长短时记忆网络模型进行基因变异识别,得到每个第一基因组序列数据的基因变异信息集合,并通过生物学根据所述基因变异信息集合设计引物扩增所述多个样本用户的目的序列,得到每个第一基因组序列数据的目标变异信息集合;建模模块,用于对每个第一基因组序列数据的目标变异信息集合进行特征聚类分析,得到多个变异模式特征,并对所述多个变异模式特征进行特征建模,得到多个第一变异特征模型;匹配模块,用于根据所述多个第一变异特征模型,对所述第二基因组序列数据进行变异特征模型匹配,得到对应的第二变异特征模型;遍历模块,用于基于所述第二变异特征模型,对所述第二基因组序列数据进行序列循环遍历,得到目标循环遍历结果;优化模块,用于对所述目标循环遍历结果进行校验,得到目标校验结果,并根据所述目标校验结果对所述第二变异特征模型进行特征模型优化,得到目标变异特征模型。
10、结合第二方面,在本发明第二方面的第一种实现方式中,所述获取模块具体用于:获取多个样本用户的多个第一核苷酸序列数据,并获取目标用户的第二核苷酸序列数据;创建核苷酸编码集合,所述核苷酸编码集合包括:腺嘌呤a=[1,0,0,0]、胞嘧啶c=[0,1,0,0]、鸟嘌呤g=[0,0,1,0]和胸腺嘧啶t=[0,0,0,1];分别对所述多个第一基因组序列数据以及所述第二基因组序列数据进行序列数据切片,得到每个第一基因组序列数据的n个第一切片序列数据以及所述第二基因组序列数据的n个第二切片序列数据;基于所述核苷酸编码集合,对所述n个第一切片序列数据进行序列编码和编码融合,得到对应的多个第一基因组序列数据,并对所述n个第二切片序列数据进行序列编码和编码融合,得到对应的第二基因组序列数据。
11、结合第二方面,在本发明第二方面的第二种实现方式中,所述识别模块具体用于:分别将所述多个第一基因组序列数据输入预置的长短时记忆网络模型,所述长短时记忆网络模型包括第一长短时记忆层、第二长短时记忆层、全连接层以及输出层;通过所述第一长短时记忆层,对每个第一基因组序列数据进行低层次特征提取,得到每个第一基因组序列数据的低层次序列特征;通过所述第二长短时记忆层,对所述低层次序列特征进行高维特征转换和特征组合,得到每个第一基因组序列数据的目标输出特征;通过所述全连接层对所述目标输出特征进行预测输出转换,得到每个第一基因组序列数据的预测输出特征;通过所述输出层中的softmax函数,对所述预测输出特征进行特征基因变异分类,得到每个第一基因组序列数据的基因变异分类结果;对所述基因变异分类结果进行变异信息整合,得到每个第一基因组序列数据的基因变异信息集合,并通过生物学根据所述基因变异信息集合设计引物扩增所述多个样本用户的目的序列,得到每个第一基因组序列数据的目标变异信息集合。
12、结合第二方面,在本发明第二方面的第三种实现方式中,所述建模模块具体用于:对每个第一基因组序列数据的目标变异信息集合进行信息提取,得到每个第一基因组序列数据的变异类型信息、变异位置信息以及变异频率信息;对所述变异类型信息、所述变异位置信息以及所述变异频率信息进行变异特征关联关系识别,得到变异特征关联关系;根据所述变异特征关联关系确定对应的多个初始聚类中心,并将所述基因变异信息集合输入预置的特征聚类分析模型;通过所述特征聚类分析模型,根据所述多个初始聚类中心对所述基因变异信息集合进行特征聚类,得到每个初始聚类中心的第一特征聚类结果;根据所述第一特征聚类结果,对所述多个初始聚类中心进行聚类中心校正,得到多个目标聚类中心;根据所述多个目标聚类中心对所述基因变异信息集合进行聚类分析,得到多个第二特征聚类结果,并对所述多个第二特征聚类结果进行变异模式解析,得到多个变异模式特征;采用随机森林算法,分别对每个变异模式特征进行特征标准化建模,得到多个第一变异特征模型。
13、结合第二方面,在本发明第二方面的第四种实现方式中,所述匹配模块具体用于:对所述第二基因组序列数据进行特征初步检测,得到第一特征标识信息;根据所述多个变异模式特征,分别创建每个第一变异特征模型的第二特征标识信息;对所述第一特征标识信息进行向量转换,得到第一特征标识向量,并对所述第二特征标识信息进行向量转换,得到第二特征标识向量;对所述第一特征标识向量与所述第二特征标识向量进行欧氏距离计算,得到每个第一变异特征模型的目标欧式距离;根据所述目标欧式距离对所述多个第一变异特征模型进行模型最优化选取,得到对应的第二变异特征模型。
14、结合第二方面,在本发明第二方面的第五种实现方式中,所述遍历模块具体用于:通过所述第二变异特征模型按照预设方向和预设第一编码长度,对所述第二基因组序列数据进行移动检测,得到移动检测结果;通过所述移动检测结果进行下一轮编码长度分析,得到第二编码长度,并通过所述第二变异特征模型,根据所述第二编码长度进行下一轮移动检测,直至所述第二基因组序列数据遍历完成,得到多个移动检测结果;判断所述多个移动检测结果是否满足预设退出条件;若不满足,则通过所述第二变异特征模型,对所述第二基因组序列数据进行序列循环遍历,生成目标循环遍历结果;若满足,则对所述多个移动检测结果进行结果综合分析,得到目标循环遍历结果并输出。
15、结合第二方面,在本发明第二方面的第六种实现方式中,所述优化模块具体用于:定义多个校验规则,并对所述多个校验规则进行集合转换,得到校验规则集合;根据所述校验规则集合对所述目标循环遍历结果进行校验,得到每个校验规则对应的初始校验结果;对每个校验规则对应的初始校验结果进行结果归集,得到目标校验结果;根据所述目标校验结果对所述第二变异特征模型进行模型参数范围确定,得到多个模型参数范围;通过所述多个模型参数范围,对所述第二变异特征模型进行随机初始值生成,得到对应的随机初始值集合,并通过预置的反向粒子传播算法对所述随机初始值集合进行粒子种群构建,得到粒子种群;对所述粒子种群进行粒子适应度计算,得到所述粒子种群对应的粒子适应度集合,同时,对所述粒子适应度集合进行迭代计算,直至满足预设条件时,生成所述粒子种群对应的最优解;通过所述最优解对所述第二变异特征模型进行特征模型优化,得到目标变异特征模型。
16、本发明提供的技术方案中,获取多个样本用户的多个第一基因组序列数据以及目标用户的第二基因组序列数据;进行基因变异识别,得到每个第一基因组序列数据的基因变异信息集合;进行特征聚类分析,得到多个变异模式特征并进行特征建模,得到多个第一变异特征模型;进行变异特征模型匹配,得到对应的第二变异特征模型;基于第二变异特征模型,对第二基因组序列数据进行序列循环遍历,得到目标循环遍历结果;对目标循环遍历结果进行校验,得到目标校验结果,并根据目标校验结果对第二变异特征模型进行特征模型优化,得到目标变异特征模型,本发明通过使用长短时记忆网络模型对基因组序列数据进行分析,能够更精确地识别基因变异。lstm的层级结构使其在处理序列数据时能够捕捉到长期依赖关系,从而提高变异识别的准确性。通过对基因组序列数据进行切片和编码处理,能够高效地处理大规模基因组数据,通过对基因变异信息进行特征聚类分析,能够识别出不同的变异模式。这种深入分析有助于理解变异背后的复杂模式,为疾病风险的预测提供更丰富的信息。通过将目标用户的第二基因组序列数据与已建立的变异特征模型进行匹配,该方法能够提供定制化的疾病风险评估,使得结果更加个性化和准确。通过对模型匹配结果的循环遍历和校验,并根据校验结果优化变异特征模型,能够持续提升模型的准确性和可靠性,确保了筛查结果的时效性和准确性,进而提高了基因检测的疾病风险筛查准确率。
- 还没有人留言评论。精彩留言会获得点赞!