一种基于多模态的睡眠障碍和抑郁症评估方法
本发明涉及一种基于多模态的睡眠障碍和抑郁症评估方法,通过同时考虑多种生理和心理因素,从而有效缓解患者的睡眠问题和抑郁症状。
背景技术:
1、失眠是最为常见的睡眠问题之一,其中慢性失眠的发病率约为10%,急性失眠的发病率约为30%~35%。失眠障碍已成为全球第二大流行性精神疾病,并且是抑郁、焦虑、痴呆等疾病的高风险因素之一。
2、抑郁症是最常见的精神心境障碍,属神经官能病症之一。根据国际疾病分类(icd-10),抑郁症患者多表现出精神不济、情绪低落、兴趣和愉悦感减退、进而产生自杀观念与行为等极端症状。目前,抑郁症已是全球疾病负担的重大因素之一。据世界卫生组织统计,截至2017年全球抑郁症患者已多达3.22亿人,占世界人口的4.4%;预计到2030年,抑郁症将超过心血管疾病而上升为第一致残诱因。
3、抑郁症已经造成了严重的社会健康问题。然而在高患病、高增长率背景下,抑郁症诊断能力并不乐观。一方面,医生病患比例不足已成为精神卫生健康工作面临的一大难题。另一方面,抑郁症病因尚未明确、缺乏客观诊断生理指标,目前临床应用中对抑郁症的诊断多以主观量表为主,其测试结果的准确性依赖于医生的熟练性以及患者的配合度,故其误诊率目前居高不下。因此需要寻找客观的参数指标,以帮助提升抑郁症诊断的准确率。
4、睡眠障碍和抑郁症是现代社会普遍存在的健康问题,传统的治疗方法仅关注特定方面的症状,缺乏综合性的评估策略。因此,需要一种全面考虑患者的生理和心理状况的基于多模态的评估方法,以提高诊疗效果。
技术实现思路
1、本发明的目的在于提供一种基于多模态的睡眠障碍和抑郁症评估方法,通过同时考虑多种生理和心理因素,以实现有效缓解患者的睡眠问题和抑郁症状。
2、为了达到上述目的,本发明采用的技术方案如下:
3、一种基于多模态的睡眠障碍和抑郁症评估方法,包括以下步骤:
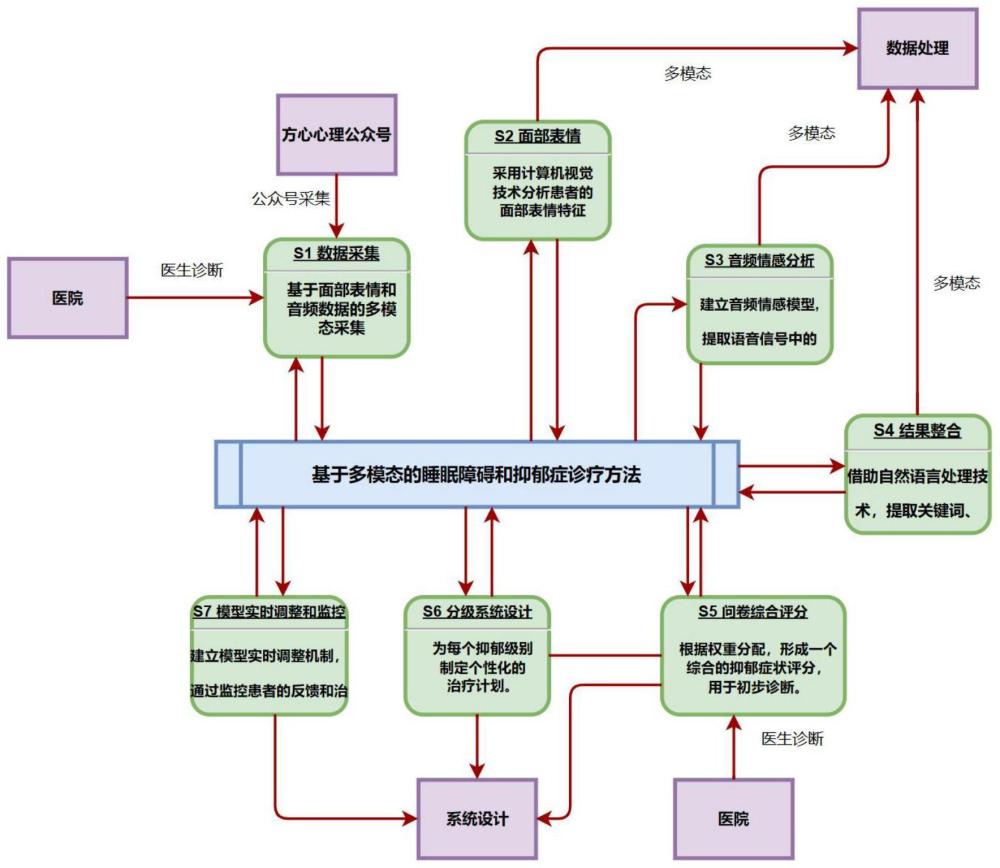
4、s1、多模态数据采集:利用公众号、心理问卷等手段采集患者的多模态数据;
5、s2、面部表情视频分析:结合面部表情特征的变化和频率,建立面部表情模型,用于量化抑郁症的程度利用面部表情视频数据,采用计算机视觉技术分析患者的面部表情特征,识别可能存在的情绪表达,如忧虑、沮丧等;
6、s3、音频情感分析:对积极、消极、中性词汇朗读音频进行情感分析,提取语音信号中的情感信息。利用声学特征(音调、语速、语调等)和情感词汇的频率,建立音频情感模型,用于评估患者的情感状态;
7、s4、视频和问卷结果整合:将患者在做问卷时采集的视频与问卷结果整合,分析患者在回答问题时的语言特征、情感倾向等信息。借助自然语言处理技术,提取关键词、情感词汇,并结合问卷得分,综合考虑患者的言语表达与抑郁症状的关联性;
8、s5、问卷综合评分:结合sds抑郁测评问卷、sas焦虑测评问卷、hcl躁狂自评问卷、shaps斯奈思-汉密尔顿快感量表、ctq童年创伤问卷和中文frost多维度完美主义问卷的结果,制定一个综合评分系统;根据权重分配,将各个问卷的得分汇总,形成一个综合的抑郁症状评分,并结合医生诊断给出结果,用于初步诊断;
9、s6、分级系统设计:设计多级分级系统,根据综合评分将抑郁症状分为轻度、中度、重度等级别。制定不同级别的干预方案,以更好地满足患者的个性化治疗需求;
10、s7、模型实时调整和监控:建立模型实时调整机制,通过监控患者的反馈和治疗效果,对诊断模型进行调整和优化,以提高准确性和实用性;
11、进一步地,所述步骤s1中采集的多模态数据具体为,包括但不限于包括一段患者的基本面部表情视频、一段积极词汇朗读音频、一段中性词汇朗读音频、一段消极词汇朗读音频、一段短文朗读音频、一段患者在做问卷时采集的视频以及问卷结果等;
12、进一步地,所述步骤s2中面部表情视频分析首先对mp4格式的面部表情视频进行帧提取,将视频切分成一系列图像帧。提取每一帧中的面部特征,包括眼睛、眉毛、嘴巴等关键点的位置。然后利用计算机视觉技术,使用面部关键点追踪算法提取每一帧中的面部表情特征。分析面部表情的变化,包括眨眼频率、微笑程度、额头皱纹等,以捕捉患者的情感表达;
13、进一步地,所述步骤s2还包括利用深度学习方法,建立面部表情与情感之间的映射关系,训练一个情感分类模型;使用已标记的训练数据集,包含不同情感状态的面部表情,以训练模型辨识抑郁症状的面部表情特征;
14、进一步地,所述步骤s3中音频情感分析包括利用音频处理技术,对wav格式的音频进行情感分析,提取语音信号中的情感信息;
15、进一步地,所述步骤s3还包括使用深度学习或机器学习算法,建立音频与情感之间的关系模型,训练一个情感分类模型;利用已标记的训练数据集,包含不同情感状态的音频样本,以训练模型来自动识别抑郁症的语音特征;
16、进一步地,所述步骤s4将患者在做问卷时采集的面部表情视频数据与相应的问卷结果进行时间同步,确保视频和文本数据的一致性。利用自然语言处理技术,提取患者言语中的关键词,包括问题的关键词以及患者自身表达的关键内容。分析关键词的出现频率和关联性,深入了解患者在特定问题上的关注点;
17、进一步地,所述步骤s4还包括结合问卷得分和自然语言处理的结果,建立一个综合模型。考虑问卷中问题的权重,结合情感分析、关键词提取和语言特征分析结果,给出一个更全面的患者言语表达与抑郁症状关联性的评估;
18、进一步地,所述步骤s5根据专业评估确定设定权重:sds权重=x;sas权重=y;hcl权重=z。shaps权重=w。ctq权重=u。frost权重=v。综合得分=sds得分*sds权重+sas得分*sas权重+hcl得分*hcl权重+shaps得分*shaps权重+ctq得分*ctq权重+frost得分*frost权重;
19、进一步地,所述步骤s5还包括设定该值为基准值,超过该值可被初步诊断为抑郁症状。初步诊断标准=threshold(根据专业评估确定,例如综合得分超过某个阈值,如50);
20、进一步地,所述步骤s6分级系统设计根据综合评分,设定不同的分级标准,将抑郁症状分为轻度、中度、重度等级别。例如,0-30分为轻度,31-60分为中度,61及以上为重度。针对每个分级别,制定个性化的治疗计划,满足患者独特的需求;包括心理治疗、药物治疗、生活方式干预等方面的个性化建议;
21、进一步地,所述步骤s6还包括对患者的治疗计划进行定期评估,根据病情的发展和患者的反馈进行调整。确保治疗计划的灵活性,以适应患者在治疗过程中的变化;
22、进一步地,所述步骤s7收集患者的实时反馈数据,包括治疗过程中的感受、症状变化、药物副作用等信息。利用问卷、面谈、移动应用等多种方式,定期获取患者的反馈。将患者的实时反馈数据纳入模型输入,确保模型能够充分考虑个体差异和治疗过程中的变化;定期更新模型的输入数据,以保持模型的时效性;
23、进一步地,所述步骤s7的自适应学习模型详细步骤如下:
24、1)时序性数据处理的深度强化学习模型lstm,设计状态、动作、奖励的表示方式,以适应患者反馈数据的时序性;
25、2)对实时收集的患者反馈数据进行实时预处理,包括面部表情特征、语音情感分析结果、治疗计划反馈;
26、3)将处理后的数据作为模型的输入,使用神经网络表示模型,其中模型的参数用权重矩阵和偏置向量表示;
27、4)训练模型时,使用梯度下降法更新模型参数,引入深度确定性策略梯度算法,用于处理连续动作空间和时序性数据;
28、5)定义状态空间、动作空间、奖励函数,并建立状态-动作-奖励-状态序列,设计奖励函数,考虑患者的症状变化、治疗反馈以及模型输出的准确性;治疗计划的有效性和患者症状的改善被赋予正奖励,相反则为负奖励;
29、6)设定一个更新频率,定期触发模型的自适应学习,根据新的数据进行参数更新;利用经验回放机制,从历史经验中抽样数据,以平稳更新模型;
30、7)设计实时评估指标;
31、8)利用持续收集的患者数据进行验证,确保模型在不同个体和治疗阶段的适应性;设计一个反馈回路,将模型输出的治疗建议实施给患者,观察患者的响应;
32、9)将患者的实际反馈数据加入到模型训练数据中,以不断优化模型的性能;
33、10)引入差分隐私技术,通过在模型训练中添加噪声来保护患者隐私;使用加密技术确保患者数据在传输和存储过程中的安全性。
34、与现有技术相比,本发明的益处是:
35、全面考虑抑郁症患者患者的生理和心理状况,以提高评估及诊疗效果,本发明的系统能通过这一多模态的方法,综合考虑患者的面部表情、语音特征、言语表达和问卷结果,为抑郁症的诊断和分级提供了更全面、个性化的评估手段。
- 还没有人留言评论。精彩留言会获得点赞!