一种用于监控自主健康的方法及系统与流程
本发明涉及健康监测,特别涉及一种用于监控自主健康的方法及系统。
背景技术:
1、信息时代的到来,使得信息技术得到了极好的发展,在多个领域被广泛关注和应用,尤其是医疗领域。医院信息系统、临床信息系统、电子病历等相继建立完成,再加之移动医疗、自动化分析检测仪等设备的普及,医院、医生与患者均成为了数据的直接创造者,健康数据呈现指数级别增长的趋势。与此同时,医疗数据交换平台、区域医疗平台的构建,打破了医疗数据的区域限制,形成了多种多样的数据库,例如基因组数据库、癫痫病数据库、心脏病数据库等,通过数据共享使得数据体量飞速增长。健康数据具有实时性强、数据量大、潜藏价值高、种类丰富等特点,如何对其潜藏价值进行深度挖掘,是提高医疗服务质量、加强个人健康管理的关键所在。
2、因此,随着信息时代的发展,大量的电子健康记录被搜集整理,其涵盖患者全面的医疗健康信息,包含疾病诊断信息、药物处方情况和采取的治疗手段等。电子健康记录是带有时间戳的动态数据,通过长期跟踪患者病情的进展情况获得。它可以为增强临床决策和促进医疗保健服务提供海量有价值的信息。
3、随着老龄化的加剧、疾病年轻化,健康数据受到了前所未有的重视,虽然健康数据中蕴藏着庞大的潜藏价值,但健康分析领域,大多数数据仅仅用于医生对患者的历史就诊情况进行查看和了解,没有发挥其真正的价值作用,造成了资源数据的浪费。
技术实现思路
1、本发明提供了一种用于监控自主健康的方法及系统,获取用户历史健康数据,并对健康数据进行不断的处理、分析,以预测用户未来的健康状态,实现对用户健康的精准把控,提高了数据利用价值。
2、本发明提供了一种用于监控自主健康的方法,包括:
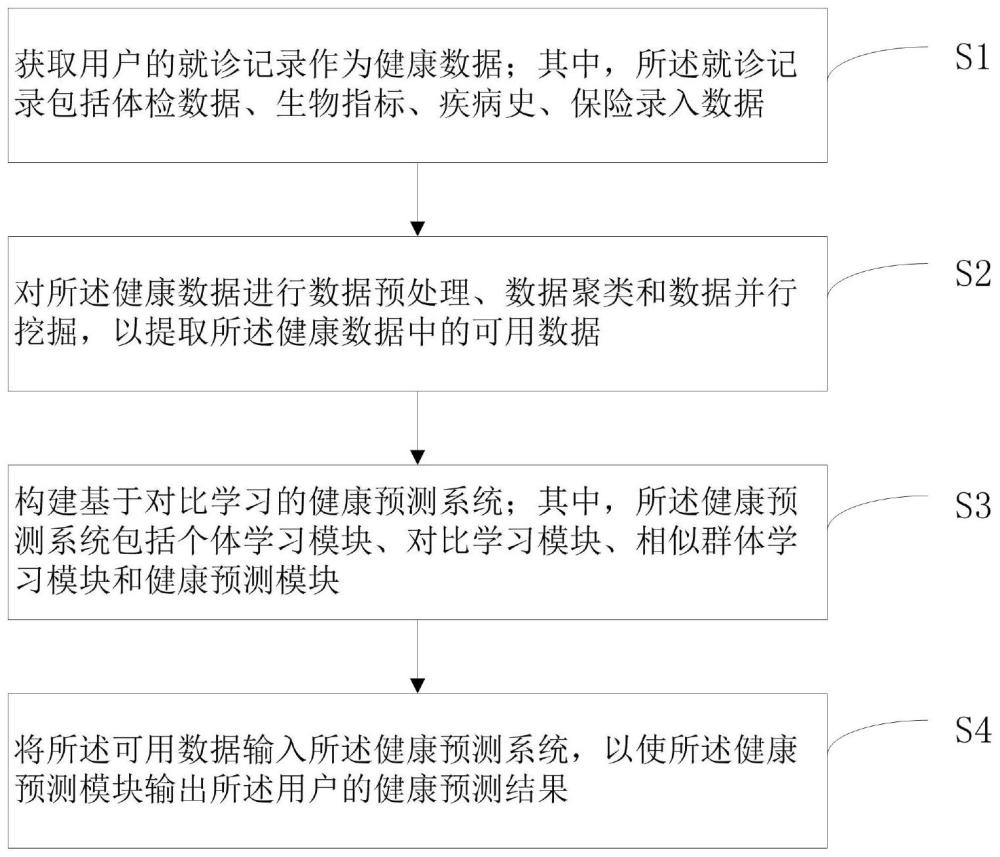
3、获取用户的就诊记录作为健康数据;其中,所述就诊记录包括体检数据、生物指标、疾病史、保险录入数据;
4、对所述健康数据进行数据预处理、数据聚类和数据并行挖掘,以提取所述健康数据中的可用数据;
5、构建基于对比学习的健康预测系统;其中,所述健康预测系统包括个体学习模块、对比学习模块、相似群体学习模块和健康预测模块;
6、将所述可用数据输入所述健康预测系统,以使所述健康预测模块输出所述用户的健康预测结果。
7、进一步地,所述对所述健康数据进行数据预处理、数据聚类和数据并行挖掘,以提取所述健康数据中的可用数据的步骤中,数据预处理包括:
8、采用预设的去噪公式对所述健康数据进行去噪处理;其中,所述预设的去噪公式为:
9、
10、其中,y'i表示去噪处理后的所述健康数据,yi表示去噪处理后的所述健康数据,α0表示双边滤波因子,ni表示所述健康数据对应的法向量,β1、β2分别表示距离权重函数、特征保持权重函数;
11、采用预设的规范化公式对去噪后的健康数据进行规范化,并利用损失函数等高线进行规范化处理效果进行展示;其中,所述规范化公式为:
12、
13、其中,x、y分别表示最小、最大规范化处理前、后的健康数据,xmin、xmax表示原始健康数据的最小值、最大值;
14、损失函数为:
15、
16、等高线定义为:
17、
18、其中,m表示样本数,w表示变量,xi表示横坐标,yi表示纵坐标。
19、进一步地,所述对所述健康数据进行数据预处理、数据聚类和数据并行挖掘,以提取所述健康数据中的可用数据的步骤中,数据聚类包括:
20、将数据预处理后的所述健康数据记为集合z={z1,z2,…,zm};
21、获取初始簇中心,度量健康数据之间的距离,并以此为基础将健康数据划分为多个类别。
22、进一步地,所述获取初始簇中心,度量健康数据之间的距离,并以此为基础将健康数据划分为多个类别的步骤,包括:
23、将健康数据维度空间均匀划分为2m个网格单元,计算每个维度网格的边长,公式为:
24、
25、其中,l表示维度网格边长,zmax与zmin表示维度空间内健康数据的最大值与最小值;p表示维度网格空间内健康数据的数量;
26、根据健康数据之间的最小距离计算网格密度阈值,网格密度阈值计算公式为:
27、
28、其中,δ*表示网格密度阈值,p0表示最小维度网格空间内健康数据的数量,zi与zj表示任意两个健康数据;
29、以网格密度阈值δ*为基础,将小于或者等于δ*的健康数据进行删除处理,计算剩余健康数据的平均数值,认定其为初始簇中心,记为{o1,o2,…ot};
30、应用欧氏距离方法衡量健康数据与初始簇中心之间的距离,表达式为:
31、dij=sqrt(oi-zj)2
32、其中,dij表示健康数据zj与初始簇中心oi之间的距离;当dij小于或者等于距离阈值d时,将健康数据zj归于初始簇中心oi的类别ci,将健康数据划分为多个类别{c1,c2,…,cq}。
33、进一步地,构建基于对比学习的健康预测系统的步骤中,个体学习模块包括:
34、获得所述用户每次的就诊记录vi的低维嵌入表示:
35、zi=σ(w0vi+b0)
36、其中,w0和b0是需要学习的参数,zi∈rd,d是向量维度,σ是激活函数;
37、将嵌入表示输入rnn模型中,生成每一个时间步t的隐状态表示:
38、ht=rnn(zi,ht-1),t=1,2,…,n
39、其中,h0=0;
40、选择最终时间步的隐状态hn作为患者个体表征向量。
41、进一步地,构建基于对比学习的健康预测系统的步骤中,对比学习模块包括:
42、针对每个患者,使用由所述个体学习模块构成的编码器生成查询向量:
43、q=encoder(v)
44、从历史就诊记录中随机掩盖一次就诊记录,记作vmask,用于构造正实例:
45、k=encoder(vmask)
46、对于目标患者p而言,正实例对是(q,k),再从剩余患者中选择l个患者,构造l个负实例对采用infonce损失函数训练模型:
47、
48、其中,τ是温度超参;通过最小化infonce损失函数,识别出相似患者的共性,保留不相似患者的判别信息。
49、进一步地,构建基于对比学习的健康预测系统的步骤中,相似群体学习模块包括:
50、对所述个体学习模块学习到的所有患者表征hindi进行多次k-means聚类操作,每次选择不同数目的簇,从而获得目标患者的多个相似患者群体。
51、进一步地,构建基于对比学习的健康预测系统的步骤中,健康预测模块包括:
52、采用自适应融合机制将患者个体表征和相似患者群体表征组合在一起进行预测;首先计算出二者的权重:
53、β1=sigmoid(w1hindi+b1)
54、β2=sigmoid(w2hindi+b2)
55、获得患者最终表征为:
56、hfinal=β1hindi+β2hsimi
57、通过softmax获得预测结果:
58、
59、其中,是预测概率;用yr∈{0,1}代表真实标签,计算交叉熵作为损失函数。
60、本发明还提供了一种用于监控自主健康的系统,包括:
61、获取模块,用于获取用户的就诊记录作为健康数据;其中,所述就诊记录包括体检数据、生物指标、疾病史、保险录入数据;
62、提取模块,用于对所述健康数据进行数据预处理、数据聚类和数据并行挖掘,以提取所述健康数据中的可用数据;
63、构建模块,用于构建基于对比学习的健康预测系统;其中,所述健康预测系统包括个体学习模块、对比学习模块、相似群体学习模块和健康预测模块;
64、输出模块,用于将所述可用数据输入所述健康预测系统,以使所述健康预测模块输出所述用户的健康预测结果。
65、本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
66、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
67、本发明的有益效果为:
68、本发明获取用户的就诊记录作为健康数据,对健康数据进行数据预处理、数据聚类和数据并行挖掘,以提取健康数据中的可用数据,构建基于对比学习的健康预测系统,并将可用数据输入健康预测系统,以输出用户的健康预测结果。实现对用户健康的精准把控,快速进行健康诊断和风险评估,提高了数据利用价值。
- 还没有人留言评论。精彩留言会获得点赞!