一种三维人体康复数据集构建方法及装置与流程
本说明书涉及计算机,尤其涉及一种三维人体康复数据集构建方法及装置。
背景技术:
1、如今,在康复治疗的领域中,人体康复数据集是一种至关重要的辅助医疗手段。相比于由康复治疗师一对一地对患者的康复训练进行观察与记录的方式,引入人体康复数据集这种数字化手段来重建患者的三维人体数据能够有效节省人力资源并加快康复效率。
2、然而,随着现代化康复治疗技术的高速发展,以及医疗诊断等领域对于大规模、多样化的人体运动数据需求的日益增长,现有的数据集构建方法由于往往依赖于人工标注,存在着标注成本高昂、效率低下、标注质量参差不齐等问题,已经开始难以满足康复治疗的需求。
3、因此,如何更加高效地构建高质量的三维人体康复数据集是一个亟待解决的问题。
技术实现思路
1、本说明书提供一种三维人体康复数据集构建方法及装置,以至少部分地解决现有技术存在的上述问题。
2、本说明书采用下述技术方案:
3、本说明书提供了一种三维人体康复数据集构建方法,包括:
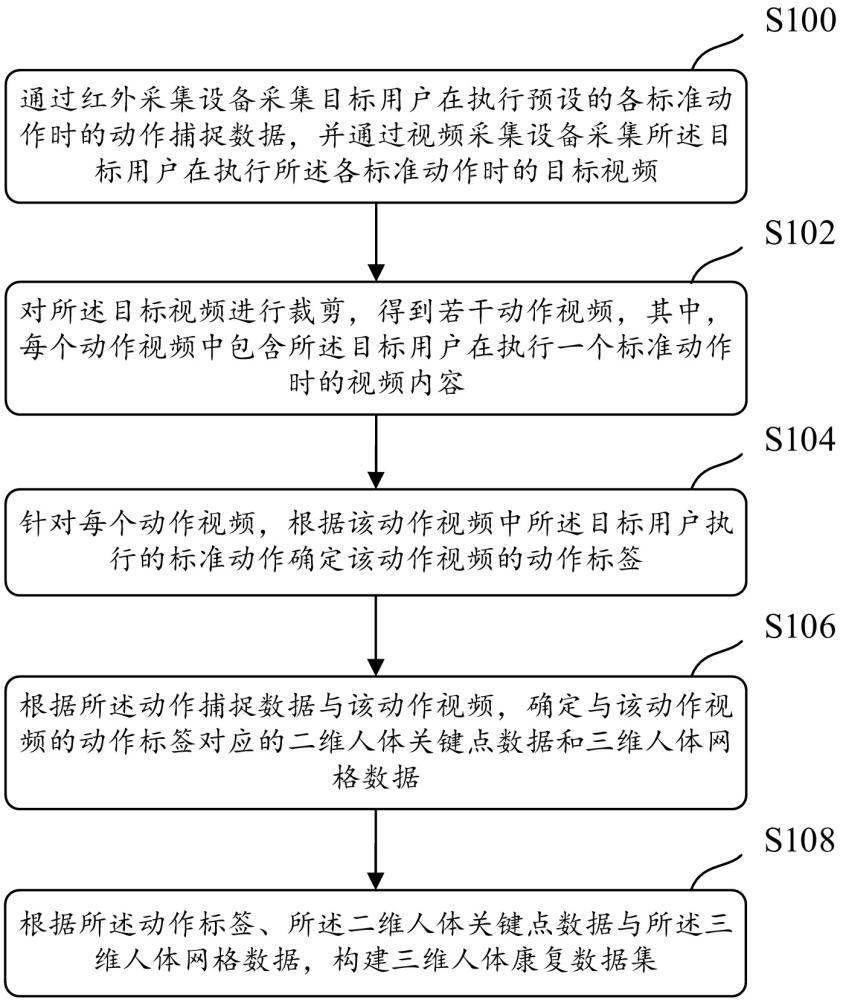
4、通过红外采集设备采集目标用户在执行预设的各标准动作时的动作捕捉数据,并通过视频采集设备采集所述目标用户在执行所述各标准动作时的目标视频;
5、对所述目标视频进行裁剪,得到若干动作视频,其中,每个动作视频中包含所述目标用户在执行一个标准动作时的视频内容;
6、针对每个动作视频,根据该动作视频中所述目标用户执行的标准动作确定该动作视频的动作标签;
7、根据所述动作捕捉数据与该动作视频,确定与该动作视频的动作标签对应的二维人体关键点数据和三维人体网格数据;
8、根据所述动作标签、所述二维人体关键点数据与所述三维人体网格数据,构建三维人体康复数据集。
9、可选地,对所述目标视频进行裁剪,得到若干动作视频,具体包括:
10、提取所述目标视频的音频数据;
11、根据预设的指定词在所述音频数据中出现的位置,对所述目标视频进行裁剪,得到若干动作视频。
12、可选地,根据该动作视频中所述目标用户执行的标准动作确定该动作视频的动作标签,具体包括:
13、将该视频输入预先训练的匹配模型,使所述匹配模型识别该动作视频中所述目标用户执行的标准动作,并将所述目标用户执行的标准动作的动作名称作为该动作视频的动作标签进行输出。
14、可选地,根据所述动作捕捉数据与该动作视频,确定与该动作视频的动作标签对应的二维人体关键点数据,具体包括:
15、对该动作视频进行切割,得到该动作视频的图像帧序列;
16、针对所述图像帧序列中的每个图像帧,确定该图像帧中所述目标用户的人物位置;
17、根据所述动作捕捉数据与所述人物位置,确定该图像帧中各人体关键点的位置;
18、根据该动作视频的图像帧中包含的各图像帧中各人体关键点的位置,确定与该动作视频的动作标签对应的二维人体关键点数据。
19、可选地,确定该图像帧中所述目标用户的人物位置,具体包括:
20、在该图像帧中确定完全包含所述目标用户的最小矩形框架;
21、将所述最小矩形框架的中心点确定为所述目标用户的位置。
22、可选地,根据所述动作捕捉数据与该动作视频,确定与该动作视频的动作标签对应的三维人体网格数据,具体包括:
23、将所述图像帧序列中的各图像帧与所述各图像帧中所述目标用户的人物位置输入预先训练的重建模型,使所述重建模型输出所述各图像帧中所述目标用户的三维人体模型;
24、根据该动作视频的图像帧序列包含的所述各图像帧中所述目标用户的三维人体模型与所述二维人体关键点数据,确定与该动作视频的动作标签对应的三维人体网格数据。
25、可选地,所述重建模型至少包含提取层、空间解耦层、时间解耦层、输出层;
26、将所述图像帧序列中的各图像帧与所述各图像帧中所述目标用户的人物位置输入预先训练的重建模型,使所述重建模型输出所述各图像帧中所述目标用户的三维人体模型,具体包括:
27、将所述图像帧序列中的各图像帧与所述各图像帧中所述目标用户的人物位置输入预先训练的重建模型;
28、采用所述提取层提取所述各图像帧的图像特征;
29、将所述各图像帧的图像特征分别输入所述空间解耦层与所述时间解耦层,分别得到所述空间解耦层输出的空间解耦特征与所述时间解耦层输出的时间解耦特征;
30、通过所述输出层,根据所述空间解耦特征、所述时间解耦特征与所述各图像帧中所述目标用户的人物位置输出所述各图像帧中所述目标用户的三维人体模型。
31、本说明书提供的一种三维人体康复数据集构建装置,所述装置包括:
32、采集模块,用于通过红外采集设备采集目标用户在执行预设的各标准动作时的动作捕捉数据,并通过视频采集设备采集所述目标用户在执行所述各标准动作时的目标视频;
33、裁剪模块,用于对所述目标视频进行裁剪,得到若干动作视频,其中,每个动作视频中包含所述目标用户在执行一个标准动作时的视频内容;
34、标注模块,用于针对每个动作视频,根据该动作视频中所述目标用户执行的标准动作确定该动作视频的动作标签;
35、确定模块,用于根据所述动作捕捉数据与该动作视频,确定与该动作视频的动作标签对应的二维人体关键点数据和三维人体网格数据;
36、构建模块,用于根据所述动作标签、所述二维人体关键点数据与所述三维人体网格数据,构建三维人体康复数据集。
37、本说明书提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述三维人体康复数据集构建方法。
38、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述三维人体康复数据集构建方法。
39、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
40、在本说明书提供的三维人体康复数据集构建方法中,通过红外采集设备采集目标用户在执行预设的各标准动作时的动作捕捉数据,并通过视频采集设备采集所述目标用户在执行所述各标准动作时的目标视频;对所述目标视频进行裁剪,得到若干动作视频,其中,每个动作视频中包含所述目标用户在执行一个标准动作时的视频内容;针对每个动作视频,根据该动作视频中所述目标用户执行的标准动作确定该动作视频的动作标签;根据所述动作捕捉数据与该动作视频,确定与该动作视频的动作标签对应的二维人体关键点数据和三维人体网格数据;根据所述动作标签、所述二维人体关键点数据与所述三维人体网格数据,构建三维人体康复数据集。
41、在采用本方法构建人体三维康复数据集时,可通过一套全自动的流程,采集到多视角、多目标环境的数据,增加了数据的泛化性与实用性,避免了训练时容易过拟化的情况,同时减少了繁琐的人力消耗,加快了数据集标注的效率。通过全自动的音频裁剪,可以将冗长的目标视频全自动地裁剪为大量的细化动作视频,避免了繁琐的多次开关拍摄与人力视频裁剪过程,大幅度提升了数据集制作效率。通过对每种动作以及完成程度均进行采集,本方法所采集的数据可以直接用来训练用于判断动作完整性的模型,可以直接应用到数字化康复技术之中。同时,本方法中地的动作标签、二维人体关键点数据、三维人体网格数据均通过模型生成,有效减少了人力消耗以及数据集的构造时间。
- 还没有人留言评论。精彩留言会获得点赞!