CDKN2A/B纯合性缺失的分析方法及系统与流程
本发明涉及计算机,具体涉及一种cdkn2a/b纯合性缺失的分析方法、系统及电子设备。
背景技术:
1、脑癌是发生在脑组织内的癌症,大量研究表明,细胞周期蛋白依赖性激酶抑制剂2a/b(cdkn2a/b)基因的纯合缺失与多种类型的脑癌的发生发展存在密切关系。cdkn2a也被称为细胞周期蛋白依赖性激酶抑制剂2a,是一种位于人类染色体9p21.3带的基因,在许多组织和细胞类型中广泛表达;该基因编码两种蛋白质,包括ink4家族成员p16(或p16ink4a)和p14arf,这两种蛋白都通过调节细胞周期发挥肿瘤抑制作用;p16抑制细胞周期蛋白依赖性激酶4和6(cdk4和cdk6),从而激活视网膜母细胞瘤(rb)家族的蛋白质,阻止从g1期到s期的转变;cdkn2b基因与cdkn2a相邻,在多种癌症中经常发生突变、缺失或失调;该基因编码一种细胞周期蛋白依赖性激酶抑制剂,也称为p15ink4b蛋白,其可与cdk4或cdk6形成复合物,并且阻止细胞周期蛋白d激活cdk激酶,抑制细胞周期g1进程。
2、多项相关的生存分析均表明,cdkn2a/b的纯合缺失与更短的无进展生存期相关;对脑膜瘤患者的相关研究表明,携带有cdkn2a/b纯合缺失的脑膜瘤患者从手术开始就具有明显更差的预后和更快的疾病进展。因此,cdkn2a/b的缺失状态可作为鉴定高复发风险脑膜瘤患者的分子标志物;伴idh1或idh2突变的弥漫浸润性星形细胞胶质瘤中如果出现微血管增生或坏死或cdkn2a/b纯合性缺失,或这3种特征的任意组合,即为cns who 4级,而诊断cns who2或3级的idh突变型星形细胞瘤需缺少cdkn2a/b纯合性缺失;因此,cdkn2a/b的纯合缺失突变在脑膜瘤和胶质瘤的分子诊断中起着非常重要的作用。
3、传统的cdkn2a/b纯合缺失检测方法主要为fish,但是,现有的fish检测在实验环节、设置对照等有较多的限制因素,成本较高且准确率较低;
4、因此,需要一种既可以保证准确率又可以节约成本的cdkn2a/b纯合性缺失的分析方法。
技术实现思路
1、本发明实施例的目的在于提供一种cdkn2a/b纯合性缺失的分析方法、系统及电子设备,用以解决现有技术中无法准确且高效分析cdkn2a/b纯合性缺失的问题。
2、为实现上述目的,本发明实施例提供一种cdkn2a/b纯合性缺失的分析方法,所述方法具体包括:
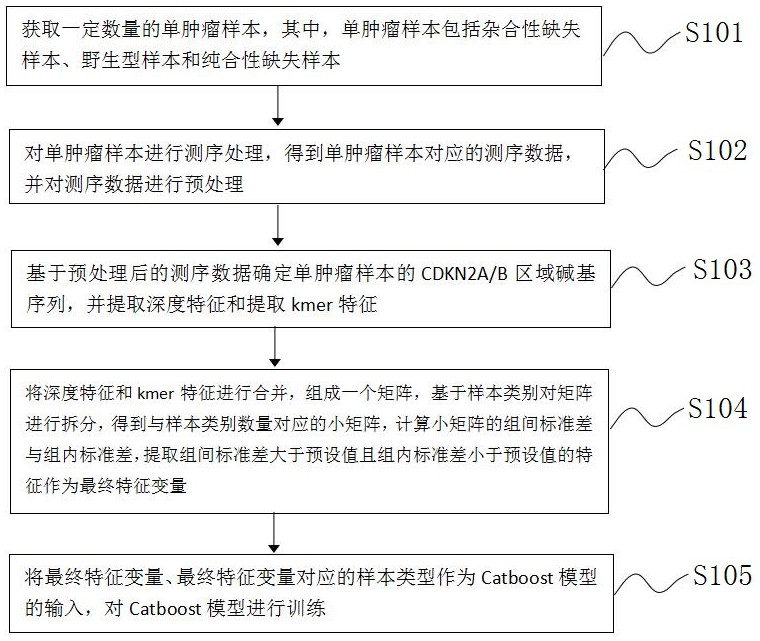
3、获取一定数量的单肿瘤样本,其中,所述单肿瘤样本包括杂合性缺失样本、野生型样本和纯合性缺失样本;
4、对所述单肿瘤样本进行测序处理,得到所述单肿瘤样本对应的测序数据,并对所述测序数据进行预处理;
5、基于预处理后的测序数据确定所述单肿瘤样本的cdkn2a/b区域碱基序列,并提取深度特征和提取kmer特征;
6、将所述深度特征和所述kmer特征进行合并,组成一个矩阵,基于样本类别对所述矩阵进行拆分,得到与所述样本类别数量对应的小矩阵,计算小矩阵的组间标准差与组内标准差,提取组间标准差大于预设值且组内标准差小于预设值的特征作为最终特征变量;
7、将所述最终特征变量、最终特征变量对应的样本类型作为catboost模型的输入,对所述catboost模型进行训练。
8、在上述技术方案的基础上,本发明还可以做如下改进:
9、进一步地,所述对所述单肿瘤样本进行测序处理,得到所述单肿瘤样本对应的测序数据,并对所述测序数据进行预处理,包括:
10、将测序数据与人类参考基因组hg19进行比对处理,以得到按照染色体顺序排序、去除重读序列后的测序数据。
11、进一步地,所述提取深度特征,包括:
12、分别计算每个单肿瘤样本对应的cdkn2a/b探针区域平均分布/样本总体平均深度,以得到深度特征。
13、进一步地,所述提取kmer特征,包括:
14、选取17bp作为kmer长度,获取cdkn2a/b区域碱基序列的kmer;
15、提取cdkn2a/b区域碱基序列的kmer中出现样本群体频率大于预设阈值的kmer,以得到kmer特征。
16、进一步地,所述矩阵的行为单肿瘤样本,列为单肿瘤样本对应的类标签,类标签设置为0.5的表示杂合性缺失,类标签设置为1表示纯合缺失,类标签设置为0的表示野生型。
17、进一步地,所述基于样本类别对所述矩阵进行拆分,得到与所述样本类别数量对应的小矩阵,计算小矩阵的组间标准差与组内标准差,提取组间标准差大于预设值且组内标准差小于预设值的特征作为特征变量,包括;
18、基于组间标准差构建组间差异矩阵,其中,所述组间差异矩阵第一列为矩阵的列名,第二列为组间标准差的均值;
19、基于组内标准差构建组内差异矩阵,其中,所述组内差异矩阵第一列为矩阵的列名,第二列为组内标准差的均值;
20、提取组间差异矩阵和组内差异矩阵第一列相同的部分,将相同的部分与第二列相除,得到差异系数;
21、将差异系数按照进行从大到小进行排序,以构建差异列表;
22、提取所述差异列表的第一列作为候选变量;
23、提取矩阵中包含所述候选变量的列,按照候选变量从上到下的顺序,构建一个新矩阵;
24、通过所述新矩阵对所述catboost模型进行训练,并计算训练完成后的所述catboost模型的平均准确率;
25、基于最大平均准确率对应的新矩阵获取特征变量。
26、进一步地,所述cdkn2a/b纯合性缺失的分析方法,还包括:
27、提取矩阵中包含特征变量的列,以得到最终数据集;
28、基于十倍交叉验证方式将所述最终数据集划分为训练集和测试集;
29、基于所述训练集训练所述catboost模型;
30、基于所述测试集评估满足性能条件的所述catboost模型的分类结果,得到所述catboost模型所对应的评价指数。
31、进一步地,所述cdkn2a/b纯合性缺失的分析方法,还包括:
32、获取待检测cdkn2a/b纯合性缺失的单肿瘤数据;
33、对所述单肿瘤数据进行测序处理,得到所述单肿瘤数据对应的测序数据,并对所述测序数据进行预处理;
34、基于预处理后的测序数据确定所述单肿瘤样本的cdkn2a/b区域碱基序列,并提取初始深度特征和初始kmer特征;
35、将所述初始深度特征和所述初始kmer特征进行合并,组成一个矩阵,基于样本类别对所述矩阵进行拆分,得到与所述样本类别数量对应的小矩阵,计算小矩阵的组间标准差与组内标准差,提取组间标准差大于预设值且组内标准差小于预设值的特征作为目标特征变量;
36、将所述目标特征变量以及相应的单肿瘤数据对应的类型输入,进行模型训练,通过训练后的模型对待检测cdkn2a/b纯合性缺失的单肿瘤数据进行预测,输出待检测的单肿瘤数据样本对应的纯杂合性缺失类型,其中,所述类型包括杂合性缺失、野生型和纯合性缺失。
37、一种cdkn2a/b纯合性缺失的分析系统,包括:
38、获取模块,用于获取一定数量的单肿瘤样本,其中,所述单肿瘤样本包括杂合性缺失样本、野生型样本和纯合性缺失样本;
39、测序处理模块,用于对所述单肿瘤样本进行测序处理,得到所述单肿瘤样本对应的测序数据,并对所述测序数据进行预处理;
40、特征提取模块,用于基于预处理后的测序数据确定所述单肿瘤样本的cdkn2a/b区域碱基序列,并提取深度特征和提取kmer特征;
41、特征变量获取模块,用于将所述深度特征和所述kmer特征进行合并,组成一个矩阵,基于样本类别对所述矩阵进行拆分,得到与所述样本类别数量对应的小矩阵,计算小矩阵的组间标准差与组内标准差,提取组间标准差大于预设值且组内标准差小于预设值的特征作为最终特征变量;
42、模型训练模块,用于将所述最终特征变量、最终特征变量对应的样本类型作为catboost模型的输入,对所述catboost模型进行训练;
43、预测模块,用于将待检测cdkn2a/b纯合性缺失的单肿瘤数据对应的目标特征变量输入至训练完成的catboost模型中,输出所述单肿瘤数据对应的类型,其中,所述类型包括杂合性缺失、野生型和纯合性缺失。
44、一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如所述方法的步骤。
45、本发明实施例具有如下优点:
46、本发明中cdkn2a/b纯合性缺失的分析方法,获取一定数量的单肿瘤样本,其中,所述单肿瘤样本包括杂合性缺失样本、野生型样本和纯合性缺失样本;对所述单肿瘤样本进行测序处理,得到所述单肿瘤样本对应的测序数据,并对所述测序数据进行预处理;基于预处理后的测序数据确定所述单肿瘤样本的cdkn2a/b区域碱基序列,并提取深度特征和提取kmer特征;将所述深度特征和所述kmer特征进行合并,组成一个矩阵,基于样本类别对所述矩阵进行拆分,得到与所述样本类别数量对应的小矩阵,计算小矩阵的组间标准差与组内标准差,提取组间标准差大于预设值且组内标准差小于预设值的特征作为特征变量;将所述最终特征变量作为catboost模型的输入、所述最终特征变量对应的样本类型也作为catboost模型的输入,对所述catboost模型进行训练,训练后的模型可用于未知样本预测;解决了现有技术中无法准确且高效分析cdkn2a/b纯合性缺失的问题。
- 还没有人留言评论。精彩留言会获得点赞!