基于大语言模型与知识蒸馏的随访数据采集方法和系统
本发明属于医疗数据采集,具体涉及一种基于大语言模型与知识蒸馏的随访数据采集方法和系统。
背景技术:
1、患者的随访数据能够客观地反映患者对于治疗手段的主观感受,被广泛应用于药物评估、不良事件监测等多个临床应用场景。早期研究通过纸质表单收集随访信息,然而这种方法面临数据一致性以及交互即时性的问题。随着个人电脑、智能手机等电子交互媒介的普及,电子表单随访数据采集系统通过在移动平台与患者交互,并将数据结构化存储,有效地突破了先前的困境。然而,电子表单的滥用使得患者对该类交互产生疲劳,并且单向输入信息缺乏足够的反馈维持患者对系统的依从性,此外,一些涉及隐私的随访内容可能引起患者的抵触或者迷惑,在缺乏澄清的情况下进一步降低了患者的依从性。
2、近年来,dialogueflow等聊天机器人低代码构建平台的兴起使得构建规则问答的随访数据采集对话系统成为了可能,通过人为定义规则和知识库,对话系统可以帮助患者在问答过程中获得额外的信息,并得到鼓励和反馈。一些研究认为对话系统能够简化操作,便于与用户建立深度关系,从而提高用户依从度和数据质量,然而,规则式对话系统需要针对特定目标人工构建足够规模的规则系统和知识库才能完成智能问答过程,其前期人工成本进一步阻碍了该方法的推广。例如,giuseppe fenza在2023年构建的healthconversational agents被应用于患者报告结局(patient-reported outcome,pro)随访数据的采集,该系统需要由研究人员预先定义一组虚拟决策树用于对话内容的推进,并且需要训练意图识别、实体提取、回应生成等多个自然语言处理组件连接用户的自然语言输入与虚拟决策树,使得对话系统前期需要投入大量人力成本,此外,受限于有限的决策分支,该系统存在无法理解输入的情况,需要采用备用意图来处理意外事件,难以模拟真实对话场景。
3、大语言模型(llm)的出现为随访数据采集对话系统带来了新的生成式解决方案。网络规模和语料知识的骤增使得llm能够正确理解复杂的自然语言文本,并在医学数据集上能够给出近似专业医师的回应,以随访表单信息采集作为目标驱动llm主动与患者交流,将能够帮助患者在对话中无感采集数据,更重要的是,该过程无需针对特定临床应用场景构建复杂的规则和知识库,极大地降低了聊天机器人的前期研发成本。然而,llm无法主动发起交流,长多轮对话过程中缺乏对复杂表单持续的注意力并且无法将对话内容与结构化随访数据库直接对接,因此基于llm构建随访数据采集对话系统需要开展进一步的研究。
4、在随访数据采集领域,jing wei等人在2023年尝试使用提示工程基于gpt-3采集用户的自报告信息,该研究重点分析了不同提示对语言模型生成问题的影响以及总结了gpt-3在生成自报告问题时可能出现的错误,为提示工程的设计进行了探索,但是其工作局限于4~5个自报告问题,缺乏对大语言模型的尝试并且没有考虑对话系统与数据库的交互,因此对于较长随访表单(>10个条目)的对话系统构建缺乏指导意义。
5、综上,迫切需要一种系统构建方法驱动大语言模型通过自然语言交互准确高效地采集患者复杂随访数据。
技术实现思路
1、鉴于上述,本发明的目的是提供一种基于大语言模型与知识蒸馏的随访数据采集方法和系统,基于随访表单获取大语言模型与用户问答的对话历史,并通过知识蒸馏得到的意图提取语言模型根据对话历史提取用户意图,从而完成随访表单的数据采集,提高患者院外随访数据采集的效率、可交互性和数据质量。
2、为实现上述发明目的,本发明提供的技术方案如下:
3、第一方面,本发明实施例提供的一种基于大语言模型与知识蒸馏的随访数据采集方法,包括以下步骤:
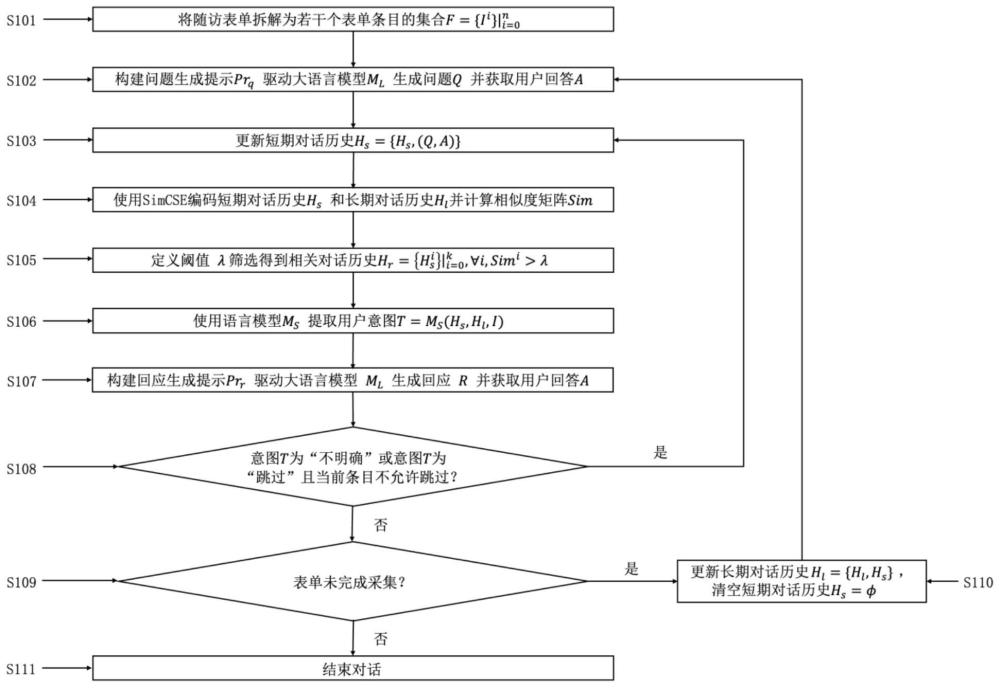
4、将随访表单拆解为若干条目的集合,其中每个条目包含随访问题及其对应的选项列表;
5、根据随访问题及其对应的选项列表构建问题生成提示并输入大语言模型,将生成的自然语言问题发送给用户并获取用户回答;
6、将每个条目对应的自然语言问题和用户回答作为短期对话历史,将所有条目的短期对话历史拼接作为长期对话历史,根据短期对话历史和长期对话历史的相似度对短期对话历史进行筛选得到相关对话历史;
7、将大语言模型作为教师模型并生成标注对话数据集,结合下游任务对作为学生模型的意图提取语言模型进行知识蒸馏;
8、基于短期对话历史、相关对话历史和条目信息,使用知识蒸馏后的意图提取语言模型提取用户意图,并构建回应生成提示输入大语言模型生成自然语言回应发送给用户,实现随访表单的一次随访数据采集。
9、优选地,所述问题生成提示包括人格提示和条目提示,人格提示用于构建具有特定人格特质的提问者并遵循预设规则生成问题,预设规则包括目标、交流方式和注意事项,条目提示用于确定每个问题的标识和属性,标识包括问题内容和选项列表,属性包括设定是否为必答题。
10、优选地,所述根据短期对话历史和长期对话历史的相似度对短期对话历史进行筛选得到相关对话历史,包括:
11、使用语言模型simcse将短期对话历史和长期对话历史编码为短期对话历史嵌入向量和长期对话历史嵌入向量,计算短期对话历史嵌入向量与长期对话历史嵌入向量中每个对话历史嵌入向量的相似度得到相似度矩阵,根据相似度矩阵定义阈值对短期对话历史进行筛选,得到相关对话历史。
12、优选地,所述将大语言模型作为教师模型并生成标注对话数据集,结合下游任务对作为学生模型的意图提取语言模型进行知识蒸馏,包括:
13、将大语言模型作为教师模型,根据每个条目中包含的随访问题及其对应的选项列表对所有条目构建基于大语言模型的虚拟医生和虚拟患者对话,得到未标注对话数据集;
14、基于未标注对话数据集先标注少量对话数据集,将少量对话数据集作为示例并结合条目信息通过上下文学习方式构建意图提取提示,使大语言模型根据示例提取对话中的意图,根据意图完成未标注对话数据集的标注,形成标注对话数据集;
15、根据标注对话数据集构建包含结构化输入的意图提取语言模型数据集,其中结构化输入包括对话历史、任务描述和特殊标记,特殊标记包括输入的开头、语句分割点和预测目标位置;
16、根据意图提取语言模型数据集对预测目标位置的意图进行预测并结合下游任务对作为学生模型的意图提取语言模型进行知识蒸馏,得到知识蒸馏后的意图提取语言模型,用于对意图的自动提取。
17、优选地,所述下游任务包括多标签分类任务、语义匹配任务和对比学习任务。
18、优选地,所述意图包括选项列表、跳过或不明确。
19、优选地,所述回应生成提示包括人格提示、催促提示、条目提示和对话历史提示,人格提示用于构建具有特定人格特质的提问者并生成问题,催促提示用于督促用户尽快回答表单条目,条目提示用于确定每个问题的标识和属性,标识包括问题内容和选项列表,属性包括设定是否为必答题,对话历史提示用于引入短期对话历史和相关对话历史。
20、第二方面,为实现上述发明目的,本发明实施例还提供了一种基于大语言模型与知识蒸馏的随访数据采集系统,包括:随访表单预处理模块、大语言模型问答模块、相关对话历史筛选模块、意图提取语言模型知识蒸馏模块、用户意图提取及回应模块;
21、所述随访表单预处理模块用于将随访表单拆解为若干条目的集合,其中每个条目包含随访问题及其对应的选项列表;
22、所述大语言模型问答模块用于根据随访问题及其对应的选项列表构建问题生成提示并输入大语言模型,将生成的自然语言问题发送给用户并获取用户回答;
23、所述相关对话历史筛选模块用于将每个条目对应的自然语言问题和用户回答作为短期对话历史,将所有条目的短期对话历史拼接作为长期对话历史,根据短期对话历史和长期对话历史的相似度对短期对话历史进行筛选得到相关对话历史;
24、所述意图提取语言模型知识蒸馏模块用于将大语言模型作为教师模型并生成标注对话数据集,结合下游任务对作为学生模型的意图提取语言模型进行知识蒸馏;
25、所述用户意图提取及回应模块用于基于短期对话历史、相关对话历史和条目信息,使用知识蒸馏后得到的意图提取语言模型提取用户意图,并构建回应生成提示输入大语言模型生成自然语言回应发送给用户,实现随访表单的一次随访数据采集。
26、第三方面,为实现上述发明目的,本发明实施例还提供了一种基于大语言模型与知识蒸馏的随访数据采集设备,包括存储器和处理器,所述存储器用于存储计算机程序,所述处理器用于当执行所述计算机程序时,实现上述的基于大语言模型与知识蒸馏的随访数据采集方法。
27、第四方面,为实现上述发明目的,本发明实施例还提供了一种计算机可读的存储介质,所述存储介质上存储有计算机程序,当所述计算机程序被计算机执行时,实现上述的基于大语言模型与知识蒸馏的随访数据采集方法。
28、与现有技术相比,本发明具有的有益效果至少包括:
29、(1)本发明通过将随访表单拆解为若干条目的集合并构建问题生成提示驱动大语言模型生成问题并获取用户回答,能够实现由大语言模型主动发起交流,实现帮助用户在对话中无感采集数据,并支持构建回应生成提示驱动大语言模型生成回应发送给用户,增强了可交互性。
30、(2)本发明通过设计基于上下文学习的提示工程,在语言模型输入中加入提示词、示例以及对话历史信息,能够根据任意随访表单生成高准确率的问答内容,并能够生成符合临床应用环境的对话内容,能够在长表单多轮对话过程中保持对复杂表单的持续注意力,提高对话质量和效率。
31、(3)本发明通过将大语言模型作为教师模型,将意图提取语言模型作为学生模型,根据构建的数据集采用离线知识蒸馏方式训练并得到知识蒸馏后的意图提取语言模型,实现对意图的自动提取,能够高精度高效地提取意图并形成高质量结构化随访数据库。
32、(4)本发明获取的知识蒸馏后的意图提取语言模型能够在低成本条件下实现高效推理,大大降低了算力开销和时间开销。
- 还没有人留言评论。精彩留言会获得点赞!