一种基于医学视觉问题类型引导的跨模态注意力增强方法
本发明涉及一种基于医学视觉问题类型引导的跨模态注意力增强方法,属于计算机视觉、自然语言处理、跨模态融合。
背景技术:
1、现阶段,在患者就医的过程中,医疗问诊一直是头道关卡。及时的医疗问诊一直是广大患者所急需的医疗资源,而问诊医生的培养又需要较长的培养周期,导致了现有问诊医生的超负荷运载,就医患者难以对自己的病症进行及时问诊。医学视觉问答技术旨在通过人工智能技术实现针对医学图像的自动问诊,该项技术是将医学图像和有关的临床问题作为输入,经深度模型的计算推理,用自然语言输出正确答案。医学视觉问答可以帮助患者对他们的询问得到及时的反馈,以便做出更明智的决定;它也可以减轻医疗系统的压力,从而节省下宝贵的医疗资源以满足人们更迫切的需要;它还可以帮助医生在诊断中获得第二意见,降低培养医学专业人员的高昂成本。医学视觉问答可帮助缓解我国经济发达地区的医疗挤兑现象,也有助于缓解我国经济欠发达地区的医疗资源短缺问题。
2、医学视觉问答中的问题文本被定义为两种具有明显差异的问题类型,其中closed类型问题通常比open类型问题更容易回答。在closed类型问题的推理过程中,其所需要的特征信息较为简单,而open类型问题通常需要更多的步骤推理和更多的深层次的推理信息。zhang等人利用类型条件推理(type-conditioned reasoning,tcr)对医学问题进行类型判断,然后将不同类型的问题分别输入独立的问题条件推理模型(question-conditioned reasoning module,qcr),通过区分开特定模态的推理过程,使得模型在不同类型问题的回答准确率上都获得了提升。
3、医学视觉问答中的文本信息与图像信息都具有丰富的特征信息,现有研究表明,在医学视觉问答模型中引入注意力机制可显著提高模型的回答准确率。当前的大部分医学视觉问答模型都选择在模态特征融合阶段加入注意力计算,yang等人提出一种用于视觉问答的堆叠注意力网络(stacked attention networks,san),他们在存储区域网络使用多层注意力机制,多次查询图像以定位相关的视觉区域并逐步推断答案。kim等人提出了双线性注意力网络(bilinear attention networks,ban),通过引入转置矩阵,使得注意力计算同时作用于两个模态,增强了跨模态特征融合中双模态特征的关注力。另一方面,医学视觉问答特征提取过程中的跨模态注意力交互机制也引起研究人员的关注,pan等人[35]提出一种多视图注意力机制(multi-view attention,muvam)利用图像特征信息引导文本特征信息的提取,同时在文本特征上进行注意力计算,最后得到更具细粒度的文本特征信息。hyderabad等人基于bert模型利用自然领域的大规模数据集合于额外的医学数据预训练医学图像特征提取网络,并使用transformer模型对两个模态的特征信息进行融合推理,提升了模型对复杂问题的感知能力。
4、在目前的医学视觉问答研究中,各种注意力机制的引入有效提升了医学视觉问答模型的问答准确率,但这些注意力机制往往需要大规模的数据进行模型训练,而目前医学视觉问答数据集较小,直接使用这些注意力模型存在负面效果。此外,医学视觉问答的问题文本信息往往包含诸多影响问答准确率的关键信息,也是跨模态特征对齐的关键指导因素。目前的医学视觉问答研究忽略了问题文本特征信息对图像特征信息的注意力增强作用。
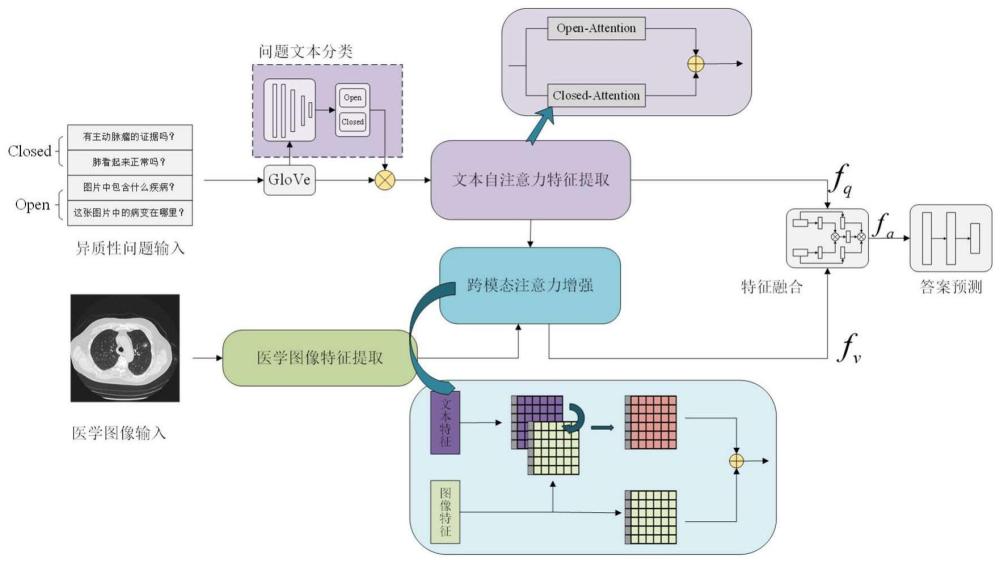
5、本发明提出一种医学视觉问题类型引导的跨模态注意力增强方法,通过引入基于“rnn+attention”的文本类型分类网络,对输入的问题文本进行类型识别。然后,根据类型标签指导文本输入两个参数不共享的自注意力特征提取网络,其次将文本特征注意力信息与由医学图像特征提取网络得到的图像特征输入到跨模态特征注意力增强网络中进行跨模态的注意力增强,最后,将两个都得到注意力增强的模态信息进行融合对齐,以进行答案的推理计算。在医学视觉问答公共数据集上得到的实验结果表明,本发明能有效提高医学视觉问答模型的准确率。
技术实现思路
1、本发明涉及一种基于医学视觉问题类型引导的跨模态注意力增强方法,有效提高医学视觉问答模型的准确率。
2、本发明的技术方案是:一种基于医学视觉问题类型引导的跨模态注意力增强方法,所述方法具体包括如下:
3、step1、在问题文本输入端,采用基于“rnn+attention”的文本类型分类模块对输入的不同类型的问题进行类型识别;
4、step2、根据分类标签由两个参数不共享的文本自注意力特征提取模块分别进行文本特征提取;
5、step3、采用医学图像降噪网络与resnet32主干网络组合构成的医学图像特征提取网络进行医学图像特征提取;
6、step4、将文本特征与图像特征一起输入到跨模态注意力增强网络中进行跨模态注意力增强;
7、step5、采用双线性注意力网络ban进行特征融合并且采用答案预测网络进行答案预测。
8、作为本发明的进一步方案,所述step1中的基于“rnn+attention”的文本类型分类模块具体包括如下:
9、经过glove词嵌入得到的问题文本向量将首先被送入一个1048维的长短期记忆网络lstm中进行特征提取,然后再将由lstm输出得到的特征向量输入一个多头自注意力网络进行特征注意力增强,其次利用一个三层的多层感知机mlp进行分类运算,最后得到问题文本的分类标签open或者closed;该过程由公式进行表示:
10、lq=fmlp(fmsa(flstm(qw)))
11、其中,qw表示问题文本向量输入,lq表示问题文本分类标签,flstm()表示lstm网络运算,fmsa()表示多头自注意力网络运算,fmlp()表示多层感知机网络运算。
12、作为本发明的进一步方案,所述step2中的文本自注意力特征提取模块具体包括如下:
13、采用输入文本向量与位置编码向量组合的方式补充了attention计算过程对文本位置信息的计算;模型的位置编码方式为相对位置编码方式sinusoidal positionencoding;该方法的计算过程由公式表示:
14、
15、
16、i=∈[0,1,2,3,···,dmodel-1]
17、其中w表示输入向量赋予的权重,t表示当前信息在句子向量中的实际位置,pet表示当前信息的位置向量,dmodel表示句子向量的长度,根据位置向量中元素的次序i的奇偶性不同,分别采用sin()或者cos()函数进行计算;
18、问题文本特征向量在与位置编码向量进行组合后,组合向量被输出一个多头自注意力网络,然后将多头自注意力网络的输出向量与输入向量进行残差连接后,由一个前馈网络进行归一化计算和前馈运算,最后重复一次上述计算进行输出;该过程由公式表示:
19、qa=fmsa(fmsa(fpe(qw)))
20、其中,qa表示模型输出的文本注意力特征向量,fmsa()表示多头自注意力计算和前馈运算,fpe()表示位置编码计算。
21、作为本发明的进一步方案,所述step3中的医学图像特征提取模块具体包括如下:
22、原始图像在降噪网络中经过卷积与最大池化实现两次下采样,然后以反卷积的方式进行两次上采样,其中进行了两次残差和连接,最终达到还原特征并抑制噪声的目的;该过程由公式表示:
23、f1=subsamp(f)
24、
25、
26、其中,f表示输入图像,subsamp()表示一次最大池化与卷积组成的下采样计算,upsamp()表示一次以反卷积实现的上采样计算,表示残差和计算,f1,f2表示中间变量,fd表示最终降噪后的图像;
27、经过4次残差模块提取特征后的原始特征将送入cbam网络模块进行注意力强化;cbam由通道注意力模块与空间注意力模块组成;其计算过程由公式表示:
28、fr=fresnet(fd)
29、
30、
31、
32、
33、其中,mc表示通道注意力,ms表示空间注意力,fr表示经过残差网络提取的输入特征;fc表示通道注意力特征,fs表示空间注意力特征;和分别表示经过全局平均池化计算后的通道注意力特征和空间注意力特征,和分别表示经过全局最大池化计算后的通道注意力特征和空间注意力特征;w0,w1表示mlp的两层参数,σ表示sigmoid激活函数,f7×7表示卷积核为7×7的卷积操作。
34、作为本发明的进一步方案,所述step4中的跨模态注意力增强网络具体包括如下:
35、跨模态注意力增强网络有两个多头自注意力模块,其中第一个多头自注意力模块有两个输入源码,医学图像特征向量vw和文本注意力特征向量qa;在第一个多头自注意力模块中,vw作为query和value的数据源,qa作为key的数据源;第一个多头自注意力模块的输出在经过与vw进行残差连接后作为输出,该输出作为第二个多头自注意力模块中query、value、key的数据源;同样将第二个多头自注意力模块的输出与输入进行残差连接后输出到一个线性层,最后得到跨模态医学图像注意力增强特征向量va;该运算过程由公式进行表示:
36、va=fmsa(fmsa(qa,vw))
37、医学图像特征向量vw在经过由文本注意力特征向量qa引导的跨模态注意力增强运算后得到跨模态医学图像注意力增强特征向量va,qa与va中都包含了经过attention机制注意力增强的两个模态的关键特征信息,他们将在进一步的特征融合后用于医学视觉问答的答案预测。
38、作为本发明的进一步方案,所述step5中的双线性注意力网络ban具体包括如下:
39、ban通过引入转置矩阵,将注意力图同时在两个模态上计算,从而实现对跨模态信息的关注;如公式:
40、
41、
42、
43、
44、其中,a表示双线性注意力图billinear attention map,x和y分别表示输入的问题特征和视觉特征,x∈rn×ρ,ρ和分别表示两个输入的通道数,u和v是线性向量嵌入,表示同位素乘法运算,xi表示x的第i个通道,yj表示y的第j个通道,p是一个可学习的投影向量,fk表示第k个元素的中间表示。
45、作为本发明的进一步方案,所述step5中的答案预测网络具体包括如下:
46、答案预测网络为一个两层的多层感知机,其两层网络之间以relu激活函数连接;在输入跨模态融合特征fa后,经过模型计算得到答案预测的结果;其计算过程如公式:
47、h=relu(fawh+bh)
48、out=hwo+bo
49、其中,h表示隐藏层,relu(*)表示激活函数,wh表示隐藏层权重,bh表示隐藏层偏差参数,out表示输出,wo表示输出层权重,bo表示隐藏层权重。
50、本发明的有益效果是:本发明有效利用了医学视觉问答中问题文本特征信息对图像特征的注意力增强潜力,针对attention机制在医学视觉问答模型中的应用做出优化,经在两个公共医学视觉问答数据集vqa-rad和slake上的消融实验和对比实验证明,本方法有效提升了医学视觉问答模型在open类型与closed类型问题上的回答准确率。
- 还没有人留言评论。精彩留言会获得点赞!