一种基于在线强化学习的血糖调控方法
本发明涉及血糖调控,特别涉及一种基于在线强化学习的血糖调控方法。
背景技术:
1、糖尿病(diabetes mellitus, dm)是一种由多因素引起且无法根治的慢性病,其主要特点是高血糖、糖尿。近年来,人们生活质量逐渐提高、生活节奏不断加快,导致生活方式不健康化程度加剧,全球糖尿病的发病率随之迅速增长。糖尿波已经成为了慢性病中严重威胁人类生活及健康的一大疾病。
2、糖尿病的治疗目标是控制血糖水平以保证患者良好的生活质量,目前主要有四种调控方法:
3、1、传统治疗方法。目前中国糖尿病主要治疗模式是通过医生根据随机临床试验结果、治疗指南和医生自身的经验定期定量为患者注射胰岛素来实现,当患者的血糖值可控后,患者可以自行注射胰岛素进行自我管理。患者需学会定期自行监测血糖,根据情况及时调整治疗方案,促使血糖达标。
4、2、基于生理模型的方法。生理模型利用了有关于血糖-胰岛素系统生理原理的先验知识,bergman 最小模型 (bergman minimal model,bmm) 是迄今为止应用最广泛的模型。该模型运用了常微分方程描述血糖-胰岛素之间的动态过程,对于后人建立血糖调控模型产生了深远的影响。该模型包括葡萄糖系统和胰岛素系统两大子模型。模型不是针对整个系统而是针对两个子系统分别独立提出的,从而降低了建模的难度。
5、3、基于数据模型的方法。随着现代医学产生的大规模的、复杂的生物医学信息数据的引入,各类基于数据的机器学习技术在血糖调控模型中的血糖预测方面得到了广泛的研究和应用。这类血糖预测研究可以用于预警糖尿病患者血糖未来将变化至高血糖或低血糖的范围,让患者或医生采取预防措施(如注射胰岛素或摄入碳水化合物)以达到血糖调控的目的。
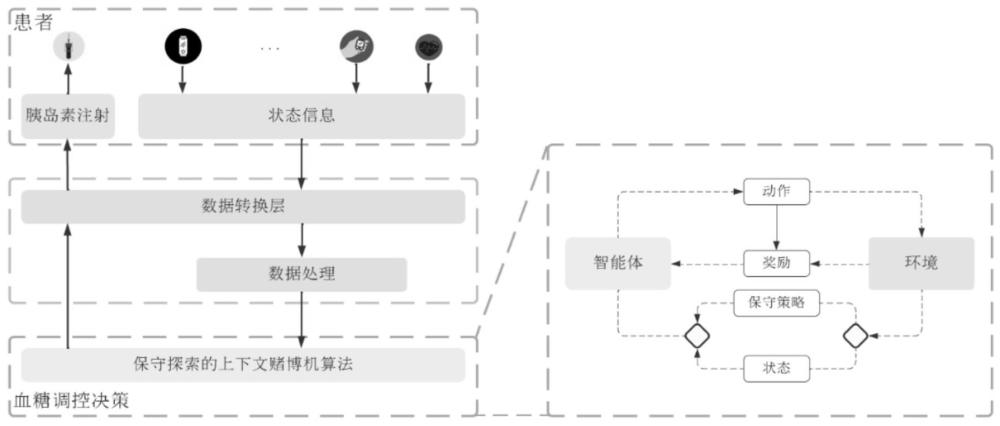
6、4、基于强化学习的方法。在血糖调控场景中,强化学习框架中的环境为糖尿病患者的血糖系统,智能体为强化学习算法,状态空间为患者的血糖水平,行动空间为胰岛素使用剂量,奖励函数由调控决策后患者的血糖水平与理想的血糖水平的差异决定。
7、然而现有血糖调控方法有如下缺陷和不足:
8、1、目前糖尿病血糖调控方法多依赖医生以往的诊疗经验和患者的自我管理。然而这并不具有普遍性和适用性。不同的患者患病情况、体质、发病原因和个人情况均不相同,因此,个性化的、针对性强的疗法才是未来的方向。
9、2、基于生理模型的血糖调控模型建模过程繁琐。生理模型的构建涉及大量参数,且不同的患者有不同的参数,这些参数很难精准测量,建模过程十分复杂。
10、3、基于数据驱动的血糖调控模型对数据要求高。在现有的糖尿病血糖调控研究中,基于数据驱动的血糖预测是受欢迎的焦点。但它需要足量、完整的历史数据,这在现实世界中很难获得。
11、4、现有的基于强化学习的血糖调控研究很难保证模型的准确性和安全性。虽然相比于基于生理模型的血糖调控方法,强化学习模型更加简洁;而相比于基于数据模型的血糖调控方法,强化学习算法无需大量数据驱动。然而现有的多数在基于线强化学习的血糖调控方法都只考虑到了少量的变量,而且在应用初期很难保证其安全性,无法应用于实际。
12、总结来说,国内目前糖尿病血糖调控方法多依赖医生以往的诊疗经验和患者的自我管理。由于各个患者的血糖系统是十分复杂的,难免会出现对病情判断出错,治疗方案有误的情况。基于生理模型的血糖调控模型建模过程繁琐。基于数据驱动的血糖调控模型对数据要求高。现有的基于强化学习的血糖调控研究很难保证模型的准确性和安全性。
技术实现思路
1、有鉴于此,本发明旨在提出一种基于在线强化学习的血糖调控方法,以构建一个安全、可靠的个性化血糖调控模型。
2、为达到上述目的,本发明的技术方案是这样实现的:
3、一种基于在线强化学习的血糖调控方法:将血糖调控问题形式化为多臂老虎机框架,并利用核心控制算法cnucb算法,即一种带有保守探索机制的神经老虎机算法构建个性化血糖调控模型,患者的生理状态即为状态信息,血糖调控药物及用量即为动作,而用药后患者的血糖均值即为评估指标转化为奖励反馈给算法;
4、在每次时间步骤中,多臂老虎机的流程是:
5、mab算法观测本轮的上下文信息得到状态信息;
6、mab算法根据和决策记录在可选动作集合中选择一个动作;
7、mab算法收到奖励反馈<msub><mi>r</mi><mi>t</mi></msub><mi>∈[0,1]</mi>并更新决策记录;
8、其中,从血糖值到奖励值的转换基于血糖风险函数:
9、
10、cnucb算法包括:保守探索机制和神经上下文学习;
11、所述cnucb控制算法所构建血糖调控方法:每当患者的血糖值高于设定预警值或患者需要用餐前后,血糖调控模型遵循以下流程:
12、从该患者的可穿戴医疗设备中获取上下文信息并得到保守策略的胰岛素注射量;
13、将和输入至cnucb算法并输出推荐胰岛素注射量;
14、通过胰岛素泵输注给患者后得到胰岛素注射后30分钟到120分钟期间的血糖平均值转换为奖励后并反馈给cnucb算法。
15、进一步的,所述保守探索机制:所述cnucb算法引入了基线政策;每轮会给出一个可供选择的基线动作和它的期望奖励;算法需要在最佳动作和中选择一个作为本轮决策,标准如下:
16、
17、其中,保守系数,越小表示算法的保守程度越高,更偏向选择基线政策;
18、所述保守探索机制设置包括pid控制算法或真实医生决策作为基线策略;根据决策标准式计算按照基线策略注射后的血糖值:
19、
20、其中,是上下文信息中的当前血糖值,是胰岛素注射后血糖值,cho表示膳食碳水化合物摄入量,icr表示患者的碳水化合物与胰岛素比率指数,isf是患者的胰岛素敏感因子。
21、进一步的,所述神经上下文学习:所述cnucb算法引入深度神经网络学习多臂老虎机问题的奖励函数;本算法的探索策略基于ucb,在此设置中,每轮选择作为最佳动作:
22、
23、其中,神经网络函数的梯度,探索系数,越大表示算法探索的意愿越高,更偏向选择探索次数少的动作。
24、进一步的,所述状态信息:患者生理状态,包括但不限于血糖值、膳食碳水化合物摄入量、运动评分、心率、皮肤电反应。
25、所述动作:餐前餐后或高血糖时胰岛素用量。
26、所述奖励反馈:胰岛素注射后30分钟到120分钟期间的血糖平均值。
27、相对于现有技术,本发明具有以下优势:
28、本发明所述的基于在线强化学习的血糖调控方法,通过引入保守探索机制增强模型安全性;现有的基于在线强化学习的血糖调控模型,忽略了早期决策时的算法广泛探索胰岛素注射量的情况,这导致了这类模型无法应用在真实医疗场景中。针对本项目所研究的医学治疗领域,从伦理学和道德层面做出深刻考量,任何可能造成患者健康状况出现问题的方案都是不可容忍的。为保证医学治疗的全流程安全性,糖尿病血糖调控模型在多臂老虎机算法的基础上引入保守探索机制,即在算法应用前期加上探索限制,保持算法表现不能过多差于人为设置的最低界限从而保证算法的安全性,最大程度实现对模型安全性的保障。
29、扩展一般人工胰岛框架提高模型精确性;一般的人工胰岛的血糖控制流程为患者血糖水平由连续血糖监测测量后,控制算法基于血糖值确定胰岛素给药量,该胰岛素剂量再由胰岛素泵输注给患者。我们将该框架扩展,本研究将患者血糖水平、膳食碳水化合物摄入量、运动量、心率等影响血糖的因素纳入考虑范围,作为算法的输入,算法会同时给出合适的胰岛素给药量。
- 还没有人留言评论。精彩留言会获得点赞!