一种基于药物代谢组学的药品分类方法与流程
本发明涉及信息处理,尤其涉及一种基于药物代谢组学的药品分类方法。
背景技术:
1、目前,现有的药品分类方法可以根据不同的标准和目的进行分类,主要包括以下几种:
2、按照药物化学结构分类:这是最常见的分类方法之一,药物按照其化学结构的相似性进行分类。例如,抗生素、抗癌药物、抗抑郁药物等都是按照其化学结构的相似性进行分类的。
3、按照治疗作用分类:药物也可以根据其主要的治疗作用进行分类,例如抗生素、镇痛药、抗抑郁药等。这种分类方法主要侧重于药物的治疗目的。
4、按照靶点分类:这种分类方法将药物根据其作用的生物学靶点进行分类,例如β受体阻滞剂、ace抑制剂等。这种分类方法主要侧重于药物对生物分子的影响。
5、按照药物用途分类:这种分类方法将药物根据其在临床上的使用目的进行分类,例如抗生素、镇痛药、抗抑郁药等。这种分类方法主要侧重于药物在临床上的应用范围。
6、按照药物的毒性分类:这种分类方法将药物根据其毒性程度进行分类,例如有毒药物、低毒药物等。这种分类方法主要侧重于药物的安全性。
7、然而目前现有的药品分类方法存在以下缺点:
8、1.忽略代谢动力学差异:传统的药品分类方法未能充分考虑不同个体对药物的代谢速率、代谢产物种类及含量的差异。这些差异可能导致相同类别的药物在不同个体中的药效和毒性表现不同。
9、2.精确度与精细度不足:现有的药品分类方法无法充分利用药物代谢组学的详细数据,导致在识别不同药品间的细微差异时精确度不高,分类体系不够精细,难以满足个性化医疗的需求。
10、3.个性化医疗应用受限:传统分类方法缺乏基于代谢组学特征的个性化用药指导。这限制了治疗方案的针对性,降低了治疗效果,同时也可能导致不必要的医疗资源浪费和不良反应风险增加。
11、4.药物研发效率低下:在药物研发流程中,现有的分类方法可能未能有效利用药物代谢数据加速药物筛选和优化,导致临床试验阶段的高成本和长周期,增加了新药研发的不确定性和失败风险。
12、5.安全性与有效性评估不足:现有的分类方法在评估药物的安全性和有效性方面不够全面,未能系统地分析药物代谢产物与不良反应的关联,使得药物相互作用和潜在副作用的识别不够及时和准确,影响了患者的用药安全。
13、因此需要一种可以解决上述问题的一种基于药物代谢组学的药品分类方法。
技术实现思路
1、本发明提供了一种基于药物代谢组学的药品分类方法,本发明通过分析药物代谢产物数据以及建立药品分类模型,利用代谢组学数据和药物效果信息训练模型,通过评估模型性能并调整参数,可以实现对药品的个性化分类,本发明通过综合药物代谢产物的详细数据,结合先进的数据预处理、特征选择和降维技术,以及聚类和分类模型的应用,能够更精确地识别药品之间的细微差别,提高分类的准确性和精细度。
2、本发明为解决上述技术问题所采用的技术方案是:一种基于药物代谢组学的药品分类方法,包括以下步骤:
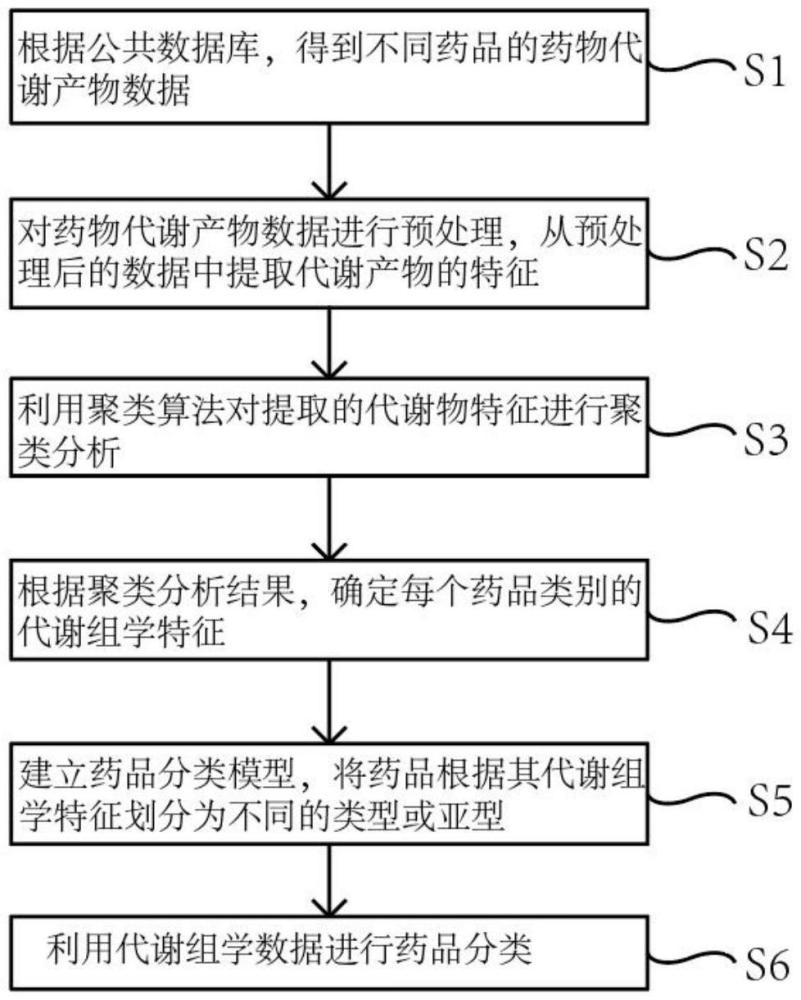
3、步骤s1:根据公共数据库,得到不同药品的药物代谢产物数据;
4、步骤s2:对药物代谢产物数据进行预处理,从预处理后的数据中提取代谢产物的特征;
5、步骤s3:利用聚类算法对提取的代谢物特征进行聚类分析;
6、步骤s4:根据聚类分析结果,确定每个药品类别的代谢组学特征;
7、步骤s5:建立药品分类模型,将药品根据其代谢组学特征划分为不同的类型或亚型;
8、步骤s6:利用代谢组学数据进行药品分类。
9、进一步的,所述步骤s1中的公共数据库包括但不限于geo、tcga、ncdb、pubchem、drugbank、chembl、hmdb数据库。
10、进一步的,所述步骤s2对药物代谢产物数据进行预处理,从预处理后的数据中提取代谢产物的特征包括:
11、步骤s2-1:首先对药物代谢产物数据进行清洗,去除存在的噪声、异常值或缺失值;
12、步骤s2-2:对清洗后的药物代谢产物数据进行数据归一化;
13、步骤s2-3:筛选出具有代表性和区分性的特征数据;
14、步骤s2-4:对于高维度的药物代谢产物数据,为了降低计算复杂度和减少模型过拟合的风险,采用主成分分析或线性判别分析方法对特征数据进行降维处理。
15、进一步的,所述步骤s3利用聚类算法对提取的代谢物特征进行聚类分析包括:
16、步骤s3-1:选择k均值聚类、层次聚类或dbscan中的任意一种聚类算法;
17、步骤s3-2:对特征数据进行标准化处理,确保不同特征之间的数值范围一致;
18、步骤s3-3:对于特征数据的每个数据点,计算其与各个聚类中心的距离;
19、步骤s3-4:将每个数据点分配到与其距离最近的聚类中心所对应的群体中;
20、步骤s3-5:更新聚类中心,重新计算每个群体的聚类中心,将群体内所有数据点的均值作为新的聚类中心;
21、步骤s3-6:对于聚类算法中需要事先确定聚类的数目,通过计算不同聚类数目下的聚类性能指标来确定最优聚类数目,达到聚类分析结果;
22、步骤s3-7:对聚类分析结果进行评估。
23、进一步的,所述步骤s3-7中对聚类分析结果进行评估包括内部评估指标计算、外部评估指标计算、可视化分析与稳定性分析。
24、进一步的,步骤5中建立药品分类模型包括:
25、步骤s5-1:根据公共数据库中的代谢组学数据建立用于建立药品分类模型的数据集;
26、步骤s5-2:将数据集分为训练集和测试集;
27、步骤s5-3:选择基于梯度提升树的分类模型;
28、步骤s5-4:通过训练集训练所选分类模型;
29、步骤s5-5:使用测试集评估分类模型性能;
30、步骤s5-6:根据评估结果调整分类模型的参数,通过调整参数后的分类模型将药品根据其代谢组学特征划分为不同的类型或亚型。
31、本发明的优点在于:
32、1.本发明通过分析药物代谢产物数据以及建立药品分类模型,利用代谢组学数据和药物效果信息训练模型,通过评估模型性能并调整参数,可以实现对药品的个性化分类,本发明通过综合药物代谢产物的详细数据,结合先进的数据预处理、特征选择和降维技术,以及聚类和分类模型的应用,能够更精确地识别药品之间的细微差别,提高分类的准确性和精细度。
33、2.本发明可以确定代谢组学特征与药品效果之间的关联性,为个体化用药提供指导,包括使用相关分析、回归分析等方法,评估代谢组学特征与药物治疗效果或不良反应的相关性和影响程度,通过了解特定代谢路径和药物效应,可以为特定患者群体推荐最适合的治疗方案。
34、3.本发明能够快速识别药物的代谢模式和活性特征,加快药物的筛选和优化过程,减少临床试验阶段的失败风险,缩短新药上市时间,并且通过分析药物代谢产物与不良反应的关联,可以提前识别潜在的药物相互作用和副作用,增强药物的安全性评估,同时优化药物的疗效。
- 还没有人留言评论。精彩留言会获得点赞!