一种生物多效堆肥中有害物的生物降解方法与流程
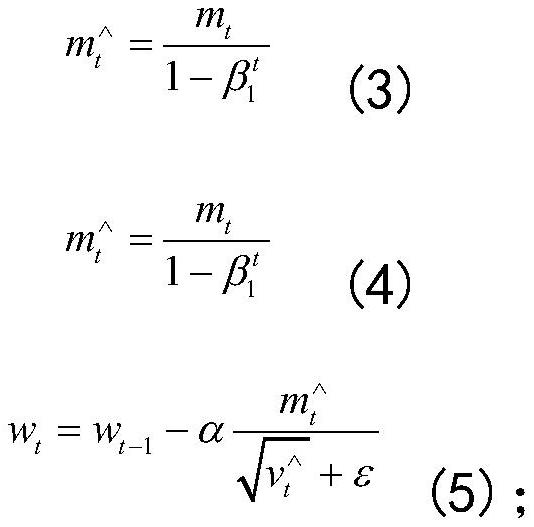
本发明涉及堆肥降解,具体为一种生物多效堆肥中有害物的生物降解方法。
背景技术:
1、生物多效堆肥是一种利用微生物和其他生物组成的多种功能群体,将有机废弃物转化为有机肥料的过程。这种堆肥方式通过模拟自然界的分解过程,利用微生物的降解作用,将有机物质转化为更稳定、更有机质的肥料,同时还能减少废弃物对环境的污染,生物多效堆肥过程中,涉及多种微生物,包括细菌、真菌和放线菌等,它们各自在不同的阶段参与有机物的分解和转化,生物多效堆肥过程通常分为初期发酵阶段、中期转化阶段和后期稳定阶段。在不同阶段,不同微生物群体起着主导作用,生物多效堆肥可以将有机废弃物转化为高质量的有机肥料,含有丰富的营养元素,有助于改善土壤结构和增加土壤肥力,生物多效堆肥可以有效减少有机废弃物对环境的污染,将废弃物转化为对植物生长有益的有机肥料,生物多效堆肥是一种环保的废弃物处理方式,有助于实现废弃物资源化利用,符合可持续发展的理念。
2、生物多效堆肥中的生物降解过程受到环境因素的影响较大,缺乏系统性和智能化,会导致缺乏系统性和智能化,无法对有害物质的降解过程进行全面、准确的分析和预测,会导致降解过程的效率较低,无法充分利用微生物的降解能力,导致有害物质在堆肥过程中无法完全清除或降解速度缓慢,同时难以优化和调整,会导致生物降解过程的优化和调整困难,无法根据实时环境变化或堆肥物质的特性进行精准的调控和优化,以及无法实现自动化控制,会导致生物降解过程无法实现自动化控制,需要人工干预和监测,增加了人力成本和工作量,生物多效堆肥过程受到环境因素的影响较大,难以应对复杂的环境变化,如温度、湿度、氧气供应等的变化,影响生物降解效果,堆肥中环状有机污染物(含氮杂环化合物、卤代芳香族化合物及抗生素类化合物等)因其结构复杂、性质稳定、生物毒性大、生物降解性差,难以通过传统的生物处理方法实现有效降解。
技术实现思路
1、针对现有技术的不足,本发明提供了一种生物多效堆肥中有害物的生物降解方法,解决了生物多效堆肥中的生物降解过程受环境因素影响大,缺乏智能化导致降解效率低,无法全面分析预测,难以优化调控和实现自动化控制,增加了人工成本,影响生物降解效果的问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:一种生物多效堆肥中有害物的生物降解方法,包括以下步骤:
3、s1、获取模型构建数据集:
4、首先需要收集包含不同降解产物、不同多效堆肥工艺参数、不同环境条件、不同有害物的化学结构、不同降解实验数据以及环境监测数据下的有机肥表面信息的数据集;
5、s2、构建初始堆肥降解分类深度学习模型:
6、在这一步骤中,首先选择一个预训练于vgg的卷积神经网络作为基础网络,然后,将随机树林算法作为主模型,随机树林算法是一个轻量级的卷积神经网络,通常用于计算机视觉任务,此外,引入协调注意力机制以增强随机树林算法模型的性能,协调注意力通常用于改善模型对不同特征的关注程度,以提高分类准确性,最后,将迁移学习应用于改进的随机树林算法模型;
7、s3、基于模型构建数据集对初始堆肥降解物自动分类模型进行训练:
8、使用模型构建数据集对初始的改进随机树林算法模型进行训练,训练过程包括向模型提供数据集中的信息和相应的标签,以便模型学习如何准确地分类堆肥降解有害物,训练后,得到一个经过训练的堆肥降解有害物分类模型;
9、s4、使用训练后的模型进行分类与评估:
10、模型经过训练后,将待检测的信息输入该模型中,模型将根据输入的数据进行分类,并输出相应的分类结果和评估分数,这些评估结果可以用于判断输入信息是否存在堆肥降解有害物,以及它们的类型和程度;
11、s5、设备还具备对设计模型的分类输出进行后处理,包含将检测结果在原信息中进行结果可视化过程,将训练好的随机森林模型应用于生物多效堆肥中有害物的生物降解预测中,根据特定的环境条件和有害物特征,预测其降解效率和降解路径;
12、s6、挑选生物多效堆肥项目,确保它们覆盖了不同类型的有害物质、不同的环境条件和多样的堆肥过程,对每个选定的案例,收集详细的实验数据,包括但不限于有害物的种类和浓度、堆肥的环境条件、堆肥过程中的时间序列数据,使用步骤s5中优化后的随机森林模型,根据实验案例的初始条件和有害物特征,预测降解效率和可能的降解路径,并根据路径采用特效菌强化降解、功能菌剂降解、光催化耦合生物强化降解方法。
13、优选的,所述s1步骤具体包括以下详细步骤:
14、s1.1、收集包含有害物的化学结构的信息数据集:
15、从不同来源收集信息数据集,这些信息应该包含有害物的化学结构,以及包含有害物的化学结构的各种信息,这些信息可以从互联网上获得,也可以通过采集现实世界中的信息;
16、s1.2、收集信息数据标注:
17、标注收集到的信息数据,在每个信息中标记出有害物含量;
18、s1.3、标注信息数据预处理:
19、对已经标注好的信息数据进行预处理;
20、s1.4、将数据集划分为训练集、验证集和测试集:
21、数据集通常需要划分为三个部分:训练集、验证集和测试集,训练集用于训练深度学习模型,验证集用于调整模型的超参数和评估模型性能,测试集用于最终评估模型的性能;
22、s1.5、训练集数据信息增强:
23、对训练集数据进行信息增强操作,信息增强是一种数据增强技术,用于增加数据集的多样性,包括旋转、翻转、随机裁剪、添加噪声操作。
24、优选的,所述s2步骤具体包括以下子步骤:
25、s2.1、完成随机树林算法的环境模型搭建:
26、设置深度学习环境,包括合适的硬件和软件配置,选择合适的gpu或tpu用于训练,安装深度学习框架;
27、s2.2、使用随机树林算法作为基础模型:
28、随机树林算法作为主干网络,用于提取信息特征;
29、s2.3、下载随机树林算法的预训练权重文件:
30、预训练权重文件包含随机树林算法在大规模信息数据集上训练的参数,同时下载这些权重文件,在改进随机树林算法模型时使用它们作为初始权重;
31、s2.4、改进随机树林算法模型以适应有害物分类任务:
32、改善随机树林算法模型以适应有害物分类任务,在模型的顶部添加自定义的分类层,以便模型可以输出不同类别的概率分布,使用数据集对微调后的改进随机树林算法模型进行训练,使模型学习如何从信息中提取特征以正确分类有害物和非有害物;
33、s2.5、监视模型在验证数据集上的性能:
34、监视包括计算模型在验证集上的损失和准确率,以及其他性能指标,根据验证性能,可以调整模型的超参数;
35、s2.6、使用独立的测试数据集对模型进行评估:
36、使用未在训练和验证过程中见过的测试数据集来评估模型的性能,常见的性能指标包括准确率、精确度、召回率和f1分数,以确定模型在实际应用中的表现;
37、s2.7、将模型部署到应用程序或系统中,用于实时有害物检测:
38、将模型部署到实际应用程序或系统中,以用于实时的有害物的化学结构检测,同时嵌入到应用程序代码中,设置接口以接收信息数据,并输出分类结果。
39、优选的,所述s4步骤具体包括以下子步骤:
40、s4.1、输入预处理:
41、首先,输入信息被调整到预设的固定尺寸,包括缩放或扩大操作以确保一致的输入尺寸,同时归一化或数据增强,以提高模型的泛化能力;
42、s4.2、特征提取:
43、预处理后的信息通过改进的随机树林算法主干网络进行前向传播,主干网络提取信息的低级和高级特征;
44、s4.3、特征映射到分类预测:
45、提取的特征映射被送入全连接层,用于将从主干网络提取的特征转换为信息分类的预测;
46、s4.4、输出预测:
47、全连接层的输出包含多个输出神经元,通常每个输出神经元对应一个类别,这些神经元的值表示对应类别的预测概率或分数,为了得到每个类别的概率分布,通常会在全连接层的输出上应用softmax函数,将每个输出值转化为0到1之间的概率值,最后,根据这些概率值做出最终的分类决策,通常选择概率最高的类别作为信息的分类结果;
48、s4.5、最终检测结果:
49、从输出中选择置信度最高的框作为最终的检测结果,这个框包括目标的边界框坐标、类别标签以及相应的置信度信息。
50、优选的,所述s6步骤中,所述特效菌包括偶氮菌、甲烷氧化菌、多环芳烃降解菌以及脲酶菌。
51、优选的,所述s6步骤中,所述特效菌强化降解包括以下步骤:
52、{1}、针对目标有害物质,进行特效菌的筛选和鉴定,这些特效菌应该具有针对目标有害物质的高降解效率和特异性;
53、{2}、培养特效菌:
54、将筛选得到的特效菌进行培养,以获得大量的活性菌体,在培养过程中,需要提供适当的培养基和生长条件,以确保特效菌的生长和活性;
55、{3}、特效菌强化降解:
56、将培养好的特效菌引入到有害物质的降解系统中,可以是生物堆肥系统;
57、{4}、监测与优化:
58、定期监测特效菌强化降解系统中有害物质的降解情况,评估降解效率和降解产物的生成情况,根据监测结果,优化特效菌的使用方法、菌种数量和生长条件,以提高降解效率和稳定性。
59、优选的,所述s6步骤中,所述功能菌剂包括解钾菌、降解菌、有机质分解菌,所述功能菌剂降解方法包括以下:
60、a、选择适当的功能菌剂:
61、根据随机树木模型判定的有害物分类信息,选择含有具有降解目标物质能力的有益微生物的功能菌剂;
62、b、施用功能菌剂:
63、将选定的功能菌剂按照建议的用量和方法施加到目标生物堆肥系统中;
64、c、提供适宜的生长条件:
65、确保功能菌剂施用后在环境中能够生存和繁殖,为其提供适宜的生长条件;
66、d、监测降解效果:
67、定期监测目标有害物质的浓度变化,评估功能菌剂对有害物质的降解效果和速率;
68、e、优化施用策略:
69、根据监测结果调整功能菌剂的施用策略,包括施用量、频率和方式,以提高降解效率和稳定性,持续监测环境中有害物质的情况,定期评估功能菌剂的降解效果,并根据需要进行管理和调整,以确保生物堆肥质量得到改善。
70、优选的,所述s6步骤中,所述光催化耦合生物强化降解方法包括以下步骤:
71、[1]、光催化处理:
72、根据随机树林模型生产的有害物分类信息,使用二氧化钛催化剂和紫外光源产生羟基自由基;
73、[2]、生物降解处理:
74、同时引入具有生物堆肥系统目标有机污染物能力的生物降解微生物,以加速有机污染物的生物降解过程;
75、[3]、光催化与生物强化耦合:
76、将光催化和生物降解两种处理方法结合起来,使光催化产生的活性氧化物与生物降解微生物协同作用,加速有机污染物的降解过程;
77、[4]、优化处理条件:
78、调节光照强度、光照时间、光催化剂的种类和用量,以及生物降解微生物的种类和数量,优化处理条件以提高降解效率;
79、[5]、监测降解效果:
80、定期监测目标有机污染物的降解效果,评估光催化耦合生物强化降解方法的效果,并根据需要调整处理策略;
81、[6]、持续改进:
82、根据监测结果和实际情况,持续改进光催化耦合生物强化降解方法,以提高降解效率和稳定性,达到环境净化的目的。
83、优选的,所述s4步骤中的训练配置,在有害物自动分类的网络训练使用epoch=50,batchsize=10;在模型网络中的优化过程会更新权重参数以最小化损失函数,本发明选择adam方法作为本网络的优化器,adam是一种用于随机目标函数的一阶梯度优化算法,使用adam优化器进行权重更新的过程如下:
84、mt=β1mt-1+(1-β1)gt (1)
85、mt=β1mt-1+(1-β1)gt (2)
86、
87、其中,t是时间步长,gt是梯度向量,gt和gt分别是梯度的第一和第二有偏矩估计,和分别是梯度的第一和第二的无偏矫正矩估计,β1和β2是矩估计的指数衰减率,α是学习率取α=0.001,w是权重模型ε=10-8。
88、优选的,10.在优化一阶梯度优化算法中,损失函数用于评估候选解决方案,以最小化预测误差,再使用交叉熵损失函数,其表示为:
89、
90、其中,y是实际情况,y是预测值,y可以取值为0(非有害物)或1(有害物);可以在0到1的范围内取值;
91、网络的性能是基于准确性的值来评估的,准确性的定义如下:
92、
93、其中,tp、tn、fp和fn分别对应于真正例、真负例、假正例和假负例,分类是二元的,其中非有害物和有害物分别对应于负类和正类,因此,tp表示正确分类了有害物信息,而tn意味着非有害物信息被准确预测,虽然准确性是两个类的性能的平均值,但tp和tn提供了更好的洞察力,可以单独衡量每个类的分类错误。
94、本发明提供了一种生物多效堆肥中有害物的生物降解方法。具备以下有益效果:
95、1、本发明将利用特效菌强化降解的方法,选取具有高降解效率和特异性的特效菌,引入到生物堆肥系统中,加速有害物质的降解过程,提高降解效率,选择适当的功能菌剂,根据随机森林模型判定的有害物分类信息,施用含有具有降解目标物质能力的有益微生物的功能菌剂,进一步促进有害物质的降解,根据预测的降解路径,结合特效菌强化降解、功能菌剂降解以及光催化耦合生物强化降解方法,采用多种不同的降解途径,提高有害物质的降解效率和彻底程度。
96、2、本发明将协调注意力机制替换原始模型中的通道注意力模块;最后,利用迁移学习在改进的随机树林算法模型提高有害物分类效果,在生物多效堆肥表面进行有害物检测,通过上述自动分类检测技术,自动化的堆肥降解有害物检测设备可以减少人工操作,降低人力成本,提高了检测的一致性和准确性。
97、3、本发明通过基于改进的随机树林算法和迁移学习的对堆肥降解有害物自动分类的方法,是一种有效用于检测、分类生物多效堆肥表面是否存在有害物的设备,提供有效的监测手段,解决针对生物多效堆肥表面检测缺乏数据的问题,本发明制作了一个包含生物多效堆肥结构的数据集,其中包含复杂的背景和各种有害物类型和大小。
- 还没有人留言评论。精彩留言会获得点赞!