一种基于机器学习的孤独症快速评估方法与流程
本发明涉及孤独症筛查评估,具体涉及一种基于机器学习的孤独症快速评估方法。
背景技术:
1、孤独症谱系障碍(autism spectrum disorder,asd),简称孤独症或自闭症,是一类以社会交往障碍、狭隘兴趣和重复刻板行为、以及感知觉异常为主要特征的发育性神经系统疾病,其发病机制复杂且尚不完全明确,以康复干预为主要治疗手段。全球孤独症患病率显著上升(美国超过2%),我国接近1%,孤独症人群超1000万,孤独症儿童超250万,孤独症的症状通常伴随终生,是影响人口健康的重大问题之一,世界卫生组织建议“早发现、早诊断、早治疗”。美国平均孤独症诊断年龄为4岁3个月,我国平均孤独症诊断年龄也超过3岁,诊断年龄的前移及孤独症亚型的准确分类是及时、有效利用1岁半至5岁黄金干预期的前提和基础。
2、当前孤独症评估多选用标准化评估工具,从大运动、精细动作、适应能力、语言、社交行为等部分或单一能区描述患者的功能障碍。一些常见的工具包括:ados(自闭症诊断观察量表),用于通过观察和与患者的互动来评估社交互动、交流、游戏和兴趣等方面的行为特征。adi-r(自闭症诊断面谈),一种针对患者家庭成员的面谈,旨在详细了解患者的发展历史和行为表现。基于icf(国际功能、残疾和健康分类)体系架构的评估,针对患者身体结构、身体功能、活动功能、参与功能、环境等因素的全面系统评估。
3、现有评估方法最大的缺点是需要专业人员进行长时间的评估。例如ados评估需要由受过培训的专业人员在临床机构进行60至90分钟的评估。icf根据评估类型的不同,其评估时间在30-120分钟不等。临床机构和受过培训的专业人员数量有限,且往往分布在城市。不能及时对需要筛查评估患者提供服务,尤其是地处偏远地区的患者。这会导致儿童患者由于不能及时被评估筛查错过最佳干预期。为了能够进行快速评估筛查,又不损失评估工具的效力。为此,提出一种基于机器学习的孤独症快速评估方法。
技术实现思路
1、本发明所要解决的技术问题在于:如何能够进行快速评估筛查,又不损失评估工具的效力,提供了一种基于机器学习的孤独症快速评估方法,基于机器学习方法,大幅缩减标准评估工具的题目数量,同时保证缩减后题目评估结果的有效性,通过这种方法,可以将评估时间减少到5-10分钟,而不明显降低评估有效性。
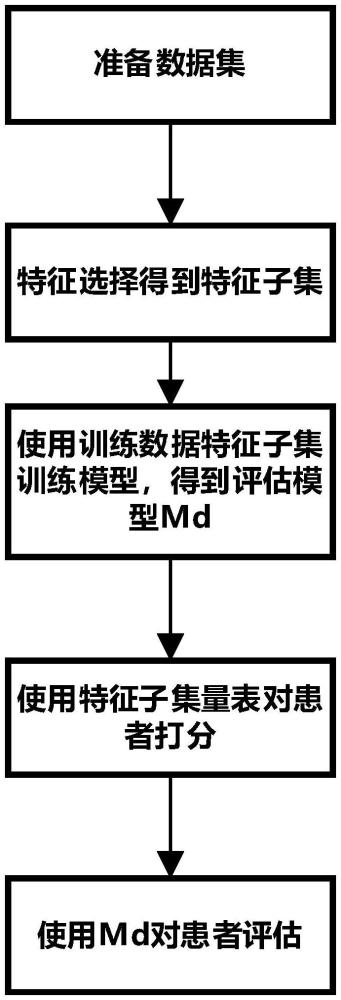
2、本发明是通过以下技术方案解决上述技术问题的,本发明包括以下步骤:
3、s1:数据收集及预处理
4、收集数据,形成数据集,对数据集进行缺失值处理和归一化,确定特征集并添加标签,得到处理后的特征集;
5、s2:特征集缩减
6、先选择机器学习模型构成模型集;然后划分特征集,定义网格搜索目标函数;并在训练集上对机器学习模型集执行k折交叉验证;最后获得缩减后的特征子集;
7、s3:获取最终评估模型
8、基于缩减后的特征子集重新对模型集中性能指标达到设定标准的部分模型进行训练,并使用测试集对上述部分模型进行测试,选择训练集和测试集综合表现最好的模型作为最终评估模型;
9、s4:模型应用
10、使用特征子集f中的题目所形成量表对患者进行测试,得到题目得分,将题目得分输入最终评估模型,得到评估结果。
11、更进一步地,在所述步骤s1中,具体处理过程如下:
12、s11:收集数据,形成数据集
13、当以孤独症评估为目的时,收集j例以上的评估数据,每例评估数据均包括题目得分和评估结果;当以孤独症筛查为目的时,收集j例以上的量表数据,每例量表数据均包括题目得分和筛查结果;
14、s12:数据预处理
15、为每个题目增加一个二元特征,特征值为0表示题目“未缺失”,特征值为1表示题目“缺失”,并增加年龄和性别为特征;
16、s13:特征数据归一化
17、将题目得分、年龄、性别全部归一化到区间[0,1],使特征数据具有统一的尺度;
18、s14:为数据添加标签
19、当以孤独症筛查为目的时,标签为0和1,分别表示asd阴性与asd阳性;当以评估为目的时,量表题目评估总分根据需要划分为m档,标签分别赋值为1~m;
20、s15:进而得到经过步骤s11-s14处理后的特征集。
21、更进一步地,在所述步骤s11中,在j例数据中,asd和非asd样本数量相同。
22、更进一步地,在所述步骤s2中,模型集的机器学习模型包括线性回归模型、逻辑回归模型、随机森林模型、决策树模型。
23、更进一步地,在所述步骤s2中,按照设定比例划分特征集,得到训练集和测试集,网格搜索目标函数如下:
24、
25、其中,aucroc表示受试者工作特征曲线下面积,w为惩罚因子,n表示被选用的特征个数。
26、更进一步地,在所述步骤s2中,在训练集上对机器学习模型集执行k折交叉验证的具体过程如下:
27、s201:第一次交叉验证中执行网格搜索,确定超参数w;
28、s202:以确定的w执行k折交叉验证和网格搜索;
29、s203:统计当前机器学习模型使用的各个特征的频次;
30、s204:对机器学习模型集中的所有机器学习模型执行步骤s201-s203。
31、更进一步地,在所述步骤s2中,获得缩减后的特征子集的具体过程如下:
32、s211:选择多个aucroc值排名靠前的模型,构成选择模型集s;
33、s212:比较选择模型集s中模型所使用的特征子集,得到各模型间的特征子集f。
34、更进一步地,在所述步骤s212中,特征子集f的选择方法如下:
35、s2121:将所有特征使用频次总和从大到小排序;
36、s2122:截取前t名特征或者根据频次阈值p截取特征,进而得到特征子集f。
37、更进一步地,在所述步骤s3中,具体处理过程如下:
38、s31:训练集上以特征子集f重新训练选择模型集s中的模型,并执行k折交叉验证,网格搜索目标函数使用aucroc;
39、s32:使用测试集对选择模型集s中的模型进行测试,选择训练集和测试集上综合表现最优的模型作为最终评估模型。
40、更进一步地,在所述步骤s32中,训练集和测试集上综合表现最优的模型即在训练集和测试集上aucroc值均排名在设定位之前的模型。
41、本发明相比现有技术具有以下优点:该基于机器学习的孤独症快速评估方法,通过大幅减少评估题目,使评估时间由1-2小时降低至5-10分钟,提高了评估效率;其次,本发明缺失值编码方法利用了缺失值信息,以受试者工作特征曲线下的面积为目标函数训练模型,降低了样本类型不平衡性的影响,提高了模型准确度,保证评估不会显著降低评估精度;最后本发明中评估题目很少(如icf由149特征降低为27特征),有利于对评估师的专业培训,同时有利于形成轻量化工具,如手机app,从而更方便的服务与农村等远离专业评估机构的人群。
- 还没有人留言评论。精彩留言会获得点赞!