本技术涉及生物序列分类,特别是涉及一种宏基因组数据分类方法、装置、设备及介质。
背景技术:
1、宏基因组定义为在某一环境中所有微生物遗传物质的总和,宏基因组不仅包括微生物群落的遗传性质,也包括这些微生物之间的复杂关系。宏基因组学是对利用宏基因组测序技术直接从环境中获得的基因组序列(即宏基因组数据)的研究,宏基因组测序技术不用对宏基因组样本中的微生物进行培养,而是直接对宏基因组样本提取dna(deoxyribonucleic acid,脱氧核糖核酸),然后组装拼接获得宏基因组样本中所有微生物的基因组序列,这种方式能够有效避免培养过程中来自外界的污染。宏基因组学技术在过去十年中已成为越来越受欢迎的研究领域,在研究海水、酸性矿山排水和人体等各种环境的项目中,宏基因组学技术使研究人员无需分离和培养单个微生物即可创建环境中微生物生命的图景,结合快速测序dna的能力,宏基因组学技术可以生成大量测序序列来描述这些以前不可见的世界。许多大规模的宏基因组组装工作已经从宏基因组样本中重建了数千个未培养的新物种,极大地拓展了特定栖息地(如人类肠道)中已知的微生物群落多样性。
2、在宏基因组学的研究中,需要获取微生物的遗传信息。由于宏基因组数据是直接从环境中获取的,所以宏基因组数据通常包含多种微生物,每种微生物包含有大量测序序列,而对于微生物数量和种属关系都是未知的。因此,宏基因组学研究首先需要将不同种属关系的测序序列分离,将相同种属关系的测序序列聚集,即宏基因组装箱问题(也可称宏基因组数据分类)。宏基因组数据分类在宏基因组分析中起到至关重要的作用,只有正确合理的进行分类工作,才能进行后续的物种丰度分析、功能分析、新物种发现等研究。然而宏基因组数据量大,种类繁多,难以分类,尤其是高通量测序技术的出现,它使得测序速度更快,成本更低,与此同时产生海量的碎片化的reads(即碱基序列,也可称短读序列数据),这些reads往往长度较短,无法直接获取这些reads的来源,更无法直接获取这些reads的来源物种,这对宏基因组数据分类问题带来了空前挑战。如何从这些短小、无序化的reads中获取物种的有效信息,还原物种的相关特性,成为生物信息领域中重要的研究问题。
3、对于大多数宏基因组样本,宏基因组样本中所存在的物种、属甚至门在测序时很大程度上是未知的,测序的目标是尽可能精确地确定这种微生物种属关系,许多物种与已知物种有一些可检测的相似性,并且这种相似性可以通过敏感的比对算法来检测,最著名的此类算法是blast程序(basic local alignment search tool,基于局部比对算法的搜索工具),它可以找到大型基因组序列数据库中与待分类序列相似度最高的序列,以对待分类序列进行分类,虽然blast程序不是为宏基因组数据分类问题设计的,但它很容易适应这个问题,并且它是可用的最佳方法之一。
4、但上述方法的本质是建立一个包含多个物种的序列的大型基因组序列数据库,将待分类序列与大型基因组序列数据库中的每一个序列进行匹配,来完成分类过程,耗时长。为了解决这一问题,目前提出了基于深度学习的分类方法,深度学习是一种高级机器学习算法,它使用深度人工神经网络从输入中学习特征并预测输出,在病毒噬菌体等序列识别的相关问题上,基于深度学习的分类方法取得了重大突破,分类效率得到明显提高。
5、但在宏基因组数据分类领域,基于深度学习的分类方法应用比较局限。现有基于深度学习的分类方法包括基于cnn(convolutional neural network,卷积神经网络)和基于lstm(long short term memory,长短期记忆网络)的生物序列分类方法,上述方法仅仅是对生物序列进行简单的二分类或三分类,对于多分类乃至宏基因组数据上更全面的分类,分类精度低;而且,上述方法局限于对生物序列的简单分类拟合,忽略了生物序列数据本身所具有的“界、门、纲、目、科、属、种”之间的分类层级语义关系,可解释性较差。
6、因此,亟需一种能够实现准确的多分类且可解释性强的分类技术。
技术实现思路
1、本技术的目的是提供一种宏基因组数据分类方法、装置、设备及介质,能够实现准确的多分类,且可解释性强。
2、为实现上述目的,本技术提供了如下方案。
3、第一方面,本技术提供了一种宏基因组数据分类方法,所述宏基因组数据分类方法包括:
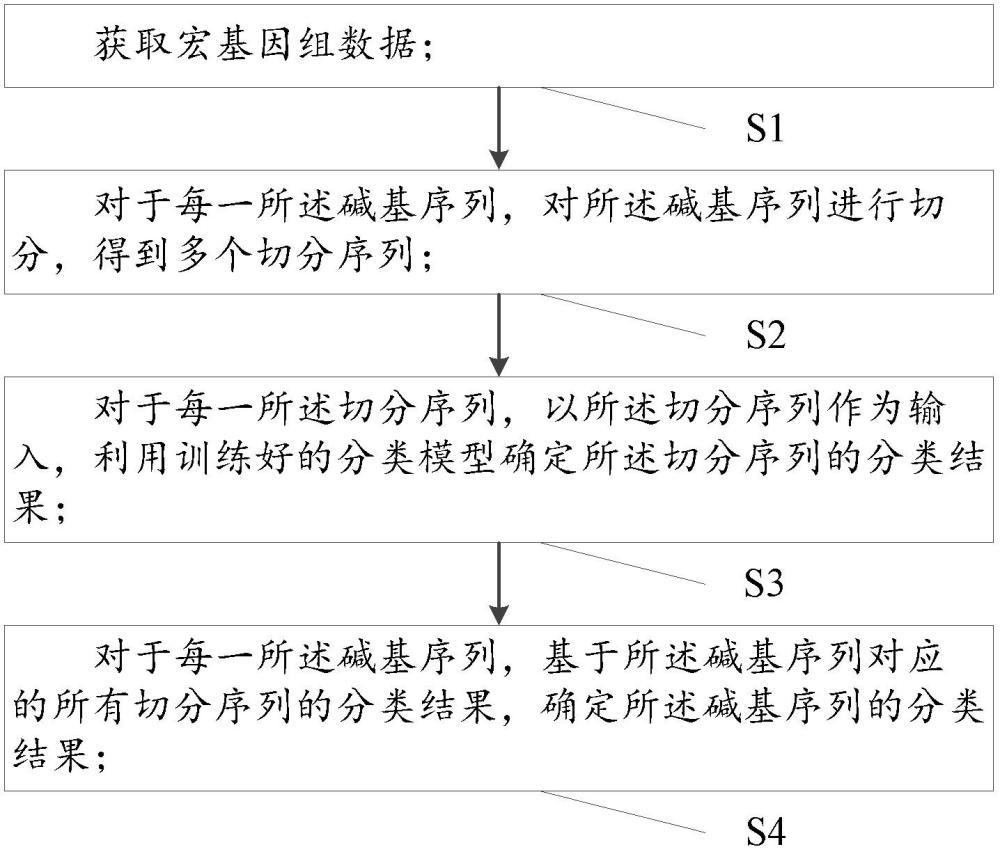
4、获取宏基因组数据;所述宏基因组数据包括多个碱基序列;
5、对于每一所述碱基序列,对所述碱基序列进行切分,得到多个切分序列;
6、对于每一所述切分序列,以所述切分序列作为输入,利用训练好的分类模型确定所述切分序列的分类结果;所述训练好的分类模型包括多个并联连接的分类层,每一所述分类层对应一个分类层级,不同所述分类层对应的分类层级不同,所述分类层级为界、门、纲、目、科、属或种;所述切分序列的分类结果包括每一所述分类层输出的初始类别,所述初始类别为所述分类层对应的分类层级中的一种类别;
7、对于每一所述碱基序列,基于所述碱基序列对应的所有切分序列的分类结果,确定所述碱基序列的分类结果;所述碱基序列的分类结果包括每一所述分类层输出的最终类别。
8、可选地,所述训练好的分类模型还包括:输入层和共享卷积层;所述输入层的输出端连接所述共享卷积层的输入端;所述共享卷积层的输出端分别连接每一所述分类层的输入端;其中,所述共享卷积层包括依次连接的多个卷积层;所述分类层包括依次连接的卷积层、池化层、激活函数层和全连接层;所述卷积层采用一维卷积。
9、可选地,在基于所述碱基序列对应的所有切分序列的分类结果,确定所述碱基序列的分类结果之前,所述宏基因组数据分类方法还包括:对所述切分序列的分类结果进行筛选,得到筛选后结果,并以所述筛选后结果作为新的分类结果;
10、其中,对所述切分序列的分类结果进行筛选,得到筛选后结果,具体包括:
11、对于每一所述分类层,判断所述切分序列的分类结果中,所述分类层输出的初始类别的概率是否大于所述分类层对应的概率阈值;若否,则在所述切分序列的分类结果中去除所述分类层输出的初始类别,以对所述切分序列的分类结果进行筛选,得到筛选后结果;所述概率是由所述训练好的分类模型输出的。
12、可选地,基于所述碱基序列对应的所有切分序列的分类结果,确定所述碱基序列的分类结果,具体包括:
13、对于每一所述分类层,执行步骤1和步骤2:
14、步骤1,对于所述分类层对应的分类层级中的每一种类别,根据所述碱基序列对应的所有切分序列的分类结果,确定所述分类层输出的初始类别与所述类别相同的切分序列的总个数,得到所述类别的权重;对所述分类层输出的初始类别与所述类别相同的切分序列的概率进行相加,得到所述类别的总概率;对所述类别的权重和所述类别的总概率进行相乘,得到所述类别的权重评分;所述概率是由所述训练好的分类模型输出的;
15、步骤2,选取所述权重评分最高的类别作为所述分类层输出的最终类别;
16、将所有所述分类层输出的最终类别组成所述碱基序列的分类结果。
17、可选地,在以所述切分序列作为输入,利用训练好的分类模型确定所述切分序列的分类结果之前,所述宏基因组数据分类方法还包括:对初始分类模型进行训练,得到训练好的分类模型;其中,在对初始分类模型进行训练时,所用的损失函数为每一分类层的交叉熵损失函数的加权和。
18、可选地,以所述切分序列作为输入,利用训练好的分类模型确定所述切分序列的分类结果,具体包括:
19、对所述切分序列进行独热编码,得到所述切分序列对应的编码特征;
20、以所述编码特征作为输入,利用训练好的分类模型确定所述切分序列的分类结果。
21、可选地,在对所述碱基序列进行切分,得到多个切分序列之前,所述宏基因组数据分类方法还包括:对所述碱基序列进行反向互补处理,得到双链序列,并以所述双链序列作为新的碱基序列。
22、第二方面,本技术提供了一种宏基因组数据分类装置,所述宏基因组数据分类装置包括:
23、数据获取模块,用于获取宏基因组数据;所述宏基因组数据包括多个碱基序列;
24、切分模块,用于对于每一所述碱基序列,对所述碱基序列进行切分,得到多个切分序列;
25、分类模块,用于对于每一所述切分序列,以所述切分序列作为输入,利用训练好的分类模型确定所述切分序列的分类结果;所述训练好的分类模型包括多个并联连接的分类层,每一所述分类层对应一个分类层级,不同所述分类层对应的分类层级不同,所述分类层级为界、门、纲、目、科、属或种;所述切分序列的分类结果包括每一所述分类层输出的初始类别,所述初始类别为所述分类层对应的分类层级中的一种类别;
26、整合模块,用于对于每一所述碱基序列,基于所述碱基序列对应的所有切分序列的分类结果,确定所述碱基序列的分类结果;所述碱基序列的分类结果包括每一所述分类层输出的最终类别。
27、第三方面,本技术提供了一种计算机设备,包括:存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述中任一项所述的宏基因组数据分类方法。
28、第四方面,本技术提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述中任一项所述的宏基因组数据分类方法。
29、根据本技术提供的具体实施例,本技术公开了以下技术效果:
30、本技术提供了一种宏基因组数据分类方法、装置、设备及介质,训练好的分类模型包括多个并联连接的分类层,每一分类层对应一个分类层级,不同分类层对应的分类层级不同,分类层级为界、门、纲、目、科、属或种,在对宏基因组数据进行分类时,对于每一碱基序列,对碱基序列进行切分,得到多个切分序列,以切分序列作为输入,利用训练好的分类模型确定切分序列的分类结果,基于碱基序列对应的所有切分序列的分类结果,确定碱基序列的分类结果,碱基序列的分类结果包括每一分类层输出的最终类别,从而通过设计训练好的分类模型的结构,可同时完成碱基序列在多分类层级的准确分类,且能够确定碱基序列在界、门、纲、目、科、属或种上的类别,可解释性强。