一种基于聚类分析法建立阿咖酚散鉴别模型的方法与流程
本发明属于药品检验,具体而言,涉及基于聚类分析法建立阿咖酚散鉴别模型的。
背景技术:
1、随着全球药品市场的迅速扩张和医疗保健需求的不断增长,药品的质量控制与安全性监测显得尤为关键。阿咖酚散主要是由阿司匹林、对乙酰氨基酚和咖啡因组成的复方制剂,其中阿司匹林及对乙酰氨基酚均能抑制前列腺素合成,具有解热镇痛作用;咖啡因是中枢兴奋药,能增强上列药物的解热镇痛作用。阿咖酚散是临床上用于治疗普通感冒或流行性感冒引起的发热,缓解轻至中度疼痛的临床常用药品之一,该产品产量大、市场需求量广,在日常的市场监督抽查检验中十分常见。由于该产品在市场上占有率较高,每年抽检数量较多,在检验检测中需要重复消耗大量的人力、物力和财力,且日常检验周期长,需要消耗大量的化学试剂、对照品等,对环境造成污染,造成资源的浪费。因此,阿咖酚散作为一种在临床上广泛使用的药物,其安全有效的使用依赖于严格的质量控制流程,才能确保其与其他药物之间能够被准确无误地区分。然而,传统的药品鉴别手段,包括色谱法、质谱法等,虽然精确度高,但通常涉及复杂的样品处理过程、长时间的分析周期和较高的运行成本,这些因素限制了它们在日常快速药品检测中的应用。
2、红外光谱技术作为一种非破坏性、灵敏度高、选择性好的分析方法,为化学与药品分析领域提供了创新的解决方案。通过分析分子对红外光谱的吸收特性,ir技术能够提供详细的分子结构和化学成分信息。如果能结合先进的数据处理技术和算法,将有潜力实现对复杂样品的快速、准确的分析。
3、申请号为cn202011642155.7的中国专利公开了一种基于红外光谱的山银花鉴别方法、设备和介质。该方法包括:以不同的标准山银花样品的红外光谱预处理后的数据集a及其鉴别信息通过聚类分析建立山银花的鉴别模型;预处理包括:从所述红外光谱的一维图谱中选择特征谱峰波段后,进行矢量归一化(snv)标准正态变量变换处理;将待测山银花样品的相应数据集b输入至所述鉴别模型中,得到所述待测山银花样品的鉴别信息;所述鉴别信息包括基原信息、和/或产地信息、和/或采收期信息。该申请通过采集不同标准山银花样品的红外光谱,对这些光谱数据进行预处理,并使用simca聚类分析法,根据不同基原、产地和采收期的山银花样品建立鉴别模型,也就是使用带有鉴别信息的样品集(即带有基原、产地、采收期等标注的数据集a)来“训练”聚类分析模型。过程中,模型会学习如何根据光谱数据的特征将样品分配到不同的类别中。也就是说,该申请中的山银花药材的鉴别信息是已知的,只需对不同的红外光谱数据模型进行训练达到与鉴别信息的完全匹配即可,而对于红外光谱数据复杂,主要成分的红外波普峰之间存在互相干扰且特征不明显,没有已知的鉴别信息的阿咖酚散来说,并没有办法采用该种方法根据采集的数据进行训练得到对应的模型。
4、申请号为cn200810052425.1的中国专利公开了一种用红外光谱结合聚类分析鉴定中药材的方法,包括以下步骤:(1)选取同类中药材标准样品;(2)对标准样品进行红外光谱检测,得到红外谱图;(3)对所得到的红外谱图用聚类分析方法建立该中药材的标准红外模型;(4)运用标准红外模型和待测中药材样品的红外谱图进行比对,即可直接对中药材进行分析、鉴定。该申请介绍了将聚类分析法应用于丹参、鸡血藤、半夏等中药材的红外光谱的识别和分类中,找出一些能够度量样本之间相似程度的统计量,并以此为依据,把一些相似程度大的样品聚为一类,疏远的聚合到一个大的分类单位,最后把分类系统直观的用图形(谱系图或称分群图、聚类图等)表示出来,以清楚反映出样本或变量的亲疏关系。该方法按照不同对象之间的差异,根据距离函数的规律作模式分类,将相似的归为一类,不相似的归为一类,其关键是选取合适的特征。也就是说,该申请的聚类分析是在同类药品的红外光谱数据集里找到共性后得到建模结果,而并没有将不同种的药品一起进行聚类,找到目标药物的共性之外还找到其特异性,尤其是对细微特征能精确到什么程度,该申请并没有将药材近似物对模型准确度的破坏纳入考量。
5、申请号为cn202110448025.8的中国专利公开了一种基于中红外光谱技术及特征提取的小米产地溯源方法,包括如下步骤:步骤1,分别采集不同产地的小米样品的红外光谱,进行预处理;步骤2,将步骤1预处理后的红外光谱数据首先进行主成分分析,然后利用窗口分析法对变量数据进行分组,分别采用支持向量机建立分类模型,再利用层次聚类分析法确定相关性小的一组变量数据,构建小米产地鉴别模型;步骤3,采集未知产地的小米样品的红外光谱,进行预处理后,输入小米产地鉴别模型,输出得到小米样品的产地。该方法基于中红外光谱技术及特征提取的小米产地溯源方法,能够快速判别小米的产地。同理,该申请也是在已知分类情况的前提下简单地采用了一定的分析方法对原始数据进行建模,依然没有指出对于情况较为复杂且特征未知的阿咖酚散药品应如何处理。
6、综上所述,以上专利中虽然均指出可以采用聚类分析处理药品的红外光谱数据并建立分析模型,但由于阿咖酚散的红外光谱数据中包括大量的重叠峰对检测造成干扰,采用以上方式直接建模往往存在较多的问题,因此,找到一种阿咖酚散的红外光谱定性分析模型并建立检测方法成为本领域技术人员亟待解决的技术问题。
技术实现思路
1、针对阿咖酚散的红外光谱数据重叠峰较多,难以归类处理,尤其是采用聚类分析时需要精确的预处理和特征提取才能保证聚类的有效性,本发明的目的在于,提供一种利用层次聚类分析进行建模的方法,得到阿咖酚散的红外定性分析模型,可以有效判别未知样品是否属于阿咖酚散,从而做到定性鉴别。
2、本发明解决其技术问题所采用的技术方案是:
3、一种基于聚类分析法建立的阿咖酚散的检测方法,包括以下步骤:
4、s1:原始数据收集:收集原始数据作为建模样本,上述原始数据包括:标准阿咖酚散样品的红外光谱数据和其他标准样品的红外光谱数据;上述标准阿咖酚散样品与上述其他标准样品的个数比为90~150∶5~20,优选为:90个标准阿咖酚散样品的红外光谱数据和5个其他标准样品的红外光谱数据,其中90个标准阿咖酚散样品选自全国各地不同药厂不同批次的市售标准品,5个其他标准样品优选为:氨咖黄敏胶囊、复方氨氛烷胺片、复方氨酚那敏颗粒、维生素c和蔗糖,均为任意批次的市售标准品。
5、本步骤中,分别收集标准阿咖酚散样品和其他标准样品,并进行红外扫描得到对应的光谱数据,将其他标准品的红外光谱数据一起作为建模的原始数据,并选择氨咖黄敏胶囊、复方氨氛烷胺片、复方氨酚那敏颗粒、维生素c和蔗糖作为优选的六个其他标准样品。以上五种药品通常可以作为阿咖酚散药品生产过程中的掺假物,其中,氨咖黄敏胶囊本品为粉末状,且颜色与阿咖酚散相似,制剂中含有与阿咖酚散相同的对乙酰氨基酚、咖啡因成分,红外光谱近似,功能主治和使用适应症与阿咖酚散相似;复方氨氛烷胺片本品为粉末状,且颜色与阿咖酚散相似,制剂中含有与阿咖酚散相同的对乙酰氨基酚、咖啡因成分,红外光谱近似,功能主治和使用适应症与阿咖酚散相似;复方氨酚那敏颗粒本品为粉末状,且颜色与阿咖酚散相似,制剂中含有与阿咖酚散相同的对乙酰氨基酚、咖啡因成分,红外光谱近似,功能主治和使用适应症与阿咖酚散相似;维生素c和蔗糖则作为制药过程中的一般添加物,原材料来源途径广泛,生产流通使用监管不严,且价格便宜、使用范围广泛,易被用于假劣药的生产。此外,由于与阿咖酚散存在相似的红外吸收峰,加入以上药品作为分类依据,并对应调整建模策略能使聚类分析分类的结果更加准确,使得到的红外定性分析模型的可信度更高。
6、s2:数据预处理和标准化:对上述原始数据进行z-score标准化预处理,得到标准化数据。
7、本步骤中,对于通过红外光谱技术(ir)采集的光谱数据,采用了z-score标准化作为数据预处理的关键步骤。z-score标准化,也称为标准差标准化,是一种数据标准化方法,旨在通过调整数据的尺度来消除量纲的影响,同时减少不同样本之间的变异性。具体来说,每个光谱数据点的z-score值是通过其原始值减去整个数据集在该波数点的平均值,然后再除以该波数点的标准差计算得到的。数学公式表示为:z=(x-μ)/σ,其中,x对应每个样本在特定波数(或频率)下的光谱强度值,μ是在该波数下所有样本的平均光谱强度值,σ是在该波数下所有样本的光谱强度值的标准差。通过这种方式,每个波数点的数据都被转换为以0为中心的分布,其分布的标准差为1。
8、z-score标准化处理后的数据具有统一的量纲和尺度,这对于后续的模型建立和分析至关重要。它不仅有助于提高模型的收敛速度,而且可以增强模型对于不同尺度特征的适应性,尤其是在使用距离计算的算法时。此外,z-score标准化还可以改善模型的泛化能力,使其更加鲁棒,对未知样本具有更好的预测性能。通过对优选的95个样本的光谱数据进行z-score标准化,能够确保数据的一致性和可比性,为建立准确有效的ir定性分析模型创造了有利条件。这一预处理步骤是本研究数据处理流程中不可或缺的一部分,为深入分析和理解样本间的光谱差异提供了坚实的基础。
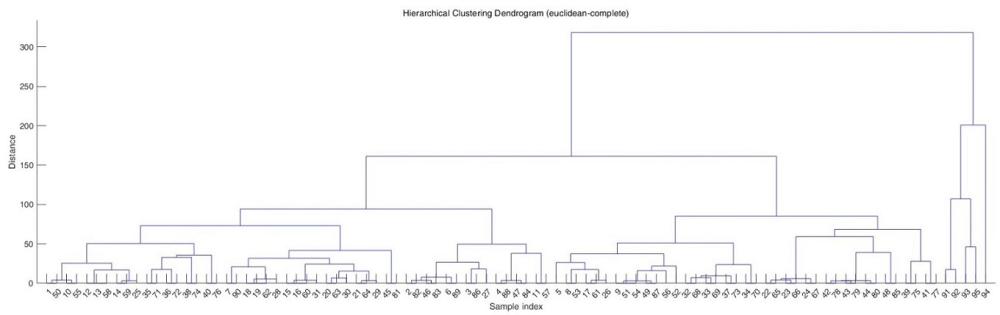
9、s3:聚类分析:采用euclidean欧几里得距离度量和complete linkage完全链接对上述标准化数据执行层次类聚,制树状图。
10、本技术中,使用的聚类分析方法是层次聚类(hierarchical clustering),并采用了完全链接(complete linkage)方法,这是一种凝聚聚类策略,可以在每一步聚类过程中合并最远距离的聚类。凝聚聚类适用于小到中等规模的数据集,能够生成详尽的层次结构,并且在实际应用中,具有一定的直观性和操作简便性。
11、在具体的数据处理过程中,首先计算所有样本之间的距离,形成一个距离矩阵。然后,根据选择的链接策略,逐步合并最相似的样本或样本群。通过重复这一合并过程,最终所有样本被合并为一个群组,并记录下整个合并历史,以树状图(dendrogram)的形式展示。本技术选择了欧几里得距离和完全链接的方法,并选择添加的其他标准样品的红外光谱数据中,与阿咖酚散相比,针对其主要成分,也就是咖啡因、对乙酰氨基酚和阿司匹林部分的红外光谱,采用欧氏距离和完全链接的分类策略,能够较好地避免对数据结构的误解。
12、由图1可以看出,在本技术所选择的原始数据和分类策略下,实施例得到的树状图易于剪枝,之后通过选择不同的高度数值切割树状图,形成不同数量的簇;此外,使用完全链接方法时,由于是基于最远点的距离来合并簇,异常值或离群点可能对聚类结果产生较大影响,使得建模结果对异常值更为敏感,从而可以增强其可信度。
13、s4:模型建立和评估:采用cutoff切割参数距离,也就是距离阈值为201~318,优选为201,对上述树状图进行切割,将所述标准化数据划分为不同的簇,得到两个主要的簇,分别为阿咖酚散类和非阿咖酚散类,从而建立红外定性分析模型。
14、本步骤中,在所得的树状图中,寻找较长的垂直线段,在此高度进行切割形成较为合理的簇。在实际操作过程中,还需要评估模型的稳定性,通过评估测试,可以检验模型是否能准确地捕捉到数据中的模式和关系,从而验证模型的有效性,确保模型能够有效地定性鉴别未知样品是否属于阿咖酚散类。由于评估测试通常涉及将数据分为训练集和测试集,模型在训练集上建立,在测试集上进行评估,检查模型在未见数据上的表现,从而评估其泛化能力,防止模型过度拟合训练数据。通过对多个模型或同一模型的不同参数设置进行评估测试,可以比较它们的性能,选择最佳的模型或参数,有助于提高模型的预测准确性和可靠性。
15、综上,聚类分析作为一种无监督学习方法,采用其对原始数据进行处理能够将一组对象分组,使得组内成员比组间成员更相似。在本技术中,聚类分析则用于发现包括阿咖酚散为主的多组药品的红外光谱数据中的内在结构。阿咖酚散作为一种含有多种化学成分的药物,其红外光谱包含了复杂的波形和各种化学成分的峰值,在实际检测过程中这些峰值往往会产生相互干扰,尤其是存在掺假、掺杂的情况时,红外光谱吸收峰之间的干扰会致红外检测过程出现困难。而结合层次聚类分析的特点,由于复杂数据本身会根据其特征自然形成一系列群体,这些分组往往无法预先设定,但可以通过算法来自动发现,即使这些群组在红外光谱数据上非常接近。进一步地,层次聚类分析能够识别出在不同层级上的相似性,这对于化学分析中识别不同化学结构的变体是尤其重要的,也就使得层次聚类分析能有效处理阿咖酚散及其类似物的红外光谱数据,在找到其中的共性的同时,做出个性的区分。
16、相对于现有技术,本发明的实施例至少具有如下有益效果:
17、1、阿咖酚散的红外光谱数据中包括大量的重叠峰,本技术利用聚类分析,在无监督学习的框架下探索以阿咖酚散的红外光谱样本为主的多组药品间的自然分组情况,得到了阿咖酚散该种药品的红外定性分析模型。
18、2、在层次聚类分析之前,采用z-score标准化使得聚类分析能够更加敏感地捕捉到样本间的细微差异,从而提高聚类的准确性和可靠性;并且在层次聚类分析过程中,选用合适的距离度量和链接方法,避免由于选择不当导致误解数据结构的情况发生。
19、3、由于除阿咖酚散之外,本身申请还添加了其他的常见掺假物参与建模过程,所得到的鉴别模型不仅可以用于优化药品生产过程中的质量控制,提高药物检验的效率,还可以在药品流通和消费环节中作为一种重要的安全保障措施,极大地减少药品混淆和误用的风险,保护消费者健康。
- 还没有人留言评论。精彩留言会获得点赞!