本发明涉及核酸测序,更具体地说,涉及一种低频单核苷酸变异检测方法和装置。
背景技术:
1、随着基因组学的发展,单核苷酸变异(snv)检测技术在生物医学研究中发挥了关键作用。snv是基因组中最常见的变异类型,对许多疾病的研究和诊断具有重要意义。基因检测技术的发展经历了从传统的sanger测序到高通量的二代测序(ngs),再到最新的三代测序(tgs)。其中,以pacbio公司的hifi测序和nanopore公司的q20测序技术为代表的三代测序技术,由于其长读长和高准确性的特点,在基因组变异检测中展现出了巨大的潜力。
2、二代测序技术凭借其高通量和较低的成本,成为了生物医学研究的主流工具。目前的变异检测主要依赖于二代测序技术。基于二代测序的数据分析软件,如deepvariant和vardict,已经被广泛应用于基因组变异检测。这些软件主要通过将测序数据比对到参考基因组,提取潜在的变异位点,并进行详细的分析和过滤,以预测和鉴定突变。然而,基于二代测序数据的低频变异检测方法要求输入数据具有极高的准确性,但二代测序技术本身在读取长片段时容易产生较高的错误率,因此在低频变异特别是体细胞低频变异检测上表现不佳。例如,deepvariant在提取候选变异位点和利用卷积神经网络(cnn)模型预测突变时,由于过滤步骤可能漏掉一些低深度变异。vardict在处理二代数据时,尽管对变异位点进行多序列比对和重比对,仍然无法完全排除由于测序错误带来的假阳性结果。这导致了在低频变异检测中的灵敏度和准确性问题。
3、具体来说,deepvariant在提取候选变异位点时进行了一定的过滤,避免了过多的候选位点影响计算可靠性,但同时也可能错过了一些低频变异。在预测突变时,该方法对结果进行进一步过滤,以减少假阳性比例,但这也意味着某些真实的低频变异可能被忽略。类似地,vardict由于仅能适用于二代数据,对三代数据的误差处理缺乏有效的应对措施。该方法通过多序列比对和重比对来处理测序错误,但仍难以在保持高灵敏度的同时减少假阳性结果。
4、综上所述,现有的低频变异检测技术在处理三代测序数据时面临挑战。这些技术主要针对二代测序数据设计,无法充分利用三代测序技术的优势,特别是在长读长和高准确性方面。现有的过滤和比对方法在检测低频变异时表现出较低的灵敏度和准确性,难以满足当前肿瘤和线粒体疾病等领域对低频变异检测的需求。因此,有必要开发新的检测方法,以更好地利用三代测序技术,提升低频变异检测的性能和可靠性。
技术实现思路
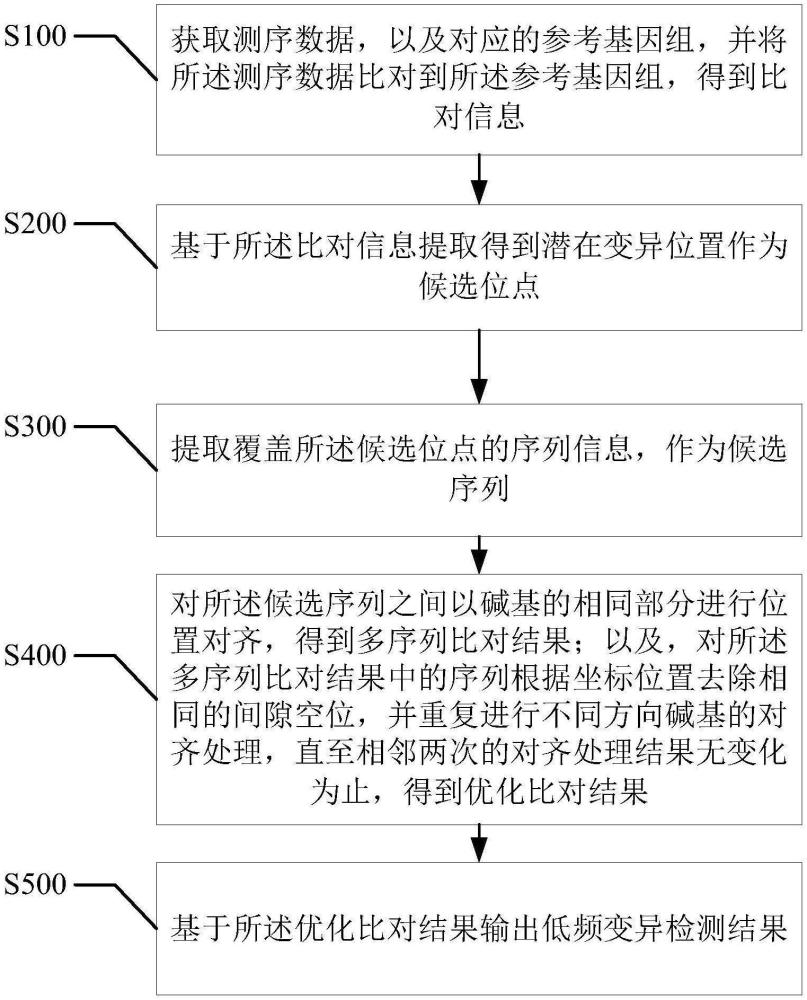
1、针对上述技术问题,本发明提供一种低频单核苷酸变异检测方法,包括:
2、s100,获取测序数据,以及对应的参考基因组,并将所述测序数据比对到所述参考基因组,得到比对信息;
3、s200,基于所述比对信息提取得到潜在变异位置作为候选位点;
4、s300,提取覆盖所述候选位点的序列信息,作为候选序列;
5、s400,对所述候选序列之间以碱基的相同部分进行位置对齐,得到多序列比对结果;以及,对所述多序列比对结果中的序列根据坐标位置去除相同的间隙空位,并重复进行不同方向碱基的对齐处理,直至相邻两次的对齐处理结果无变化为止,得到优化比对结果;
6、s500,基于所述优化比对结果输出低频变异检测结果。
7、优选地,所述s100包括:
8、s110,获取所述测序数据和所述参考基因组,将所述测序数据基于所述参考基因组进行比对分析,得到包含所述测序数据在所述参考基因组中定位位置的比对结果文件;其中,所述比对结果文件为排序处理并构建索引后的文件;
9、s120,对所述比对结果文件进行堆积统计处理,得到所述比对信息。
10、优选地,所述s120,包括:
11、s121,对所述参考基因组进行切分,得到多个分析窗口;
12、s122,对所述分析窗口上的所述测序数据的逐个碱基进行cigar字符串的解析,得到解析结果;其中,所述解析结果中的比对事件类型包括同配、错配、插入和缺失中的至少一种;
13、s123,将所述解析结果基于每个碱基对应的碱基位置,作为所述比对信息。
14、优选地,所述s200包括:
15、s210,统计每个碱基位置对应的所述比对事件类型的数量;
16、s220,判断是否存在所述比对事件类型的数量不小于2,且每个所述比对事件类型支持的reads数目都不小于预设过滤标准的碱基位置;
17、s230,若是,则所述碱基位置为潜在变异位置,将所述碱基位置作为所述候选位点;
18、s240,若否,则所述碱基位置不为潜在变异位置,不作为所述候选位点;
19、所述s220中,预设过滤标准的确定方法包括:
20、s221,获取当前区域的测序深度;
21、s222,若所述测序深度不小于10条,则所述预设过滤标准为2条;
22、s223,若所述测序深度小于10条,则所述预设过滤标准为1条;
23、所述s200之后,还包括:
24、s600,确定相邻的两个候选位点之间的位置间隔;
25、s700,将所述位置间隔小于2的两个相邻的候选位点,合并作为一个候选位点。
26、优选地,所述s300包括:
27、s310,获取所述候选位点的坐标位置;
28、s320,以所述坐标位置为中心,提取包括所述坐标位置对应的碱基,以及相邻的前后预设间隔位置数的碱基,构成覆盖所述候选位点的序列,并将所述序列作为所述候选序列。
29、优选地,所述s400包括:
30、s410,将所述候选序列两两进行比对,确定序列中的相同部分碱基,作为相同组件;
31、s420,以所述相同组件为基准,利用间隙空位补齐所述候选序列不匹配的位置,使所述候选序列通过所述相同组件对齐,得到所述多序列比对结果;其中,所述多序列比对结果中的每个序列的碱基和所述间隙空位的总长度相等;
32、s430,删除所述多序列比对结果中序列之间相同位置的间隙空位;
33、s440,进行不同方向碱基的对齐处理,得到第一优化结果;
34、s450,对所述第一优化结果再次进行所述不同方向碱基的对齐处理,得到第二优化结果;
35、s460,判断所述第二优化结果是否与所述第一优化结果一致;
36、s470,若是,则将所述第一优化结果或所述第二优化结果作为所述优化比对结果;
37、s480,若否,则将所述第二优化结果返回执行s450。
38、优选地,所述s450中的所述不同方向碱基的对齐处理包括:
39、s451,将每个候选序列分别进行左对齐处理和右对齐处理,得到整理结果;
40、s452,删除所述整理结果中序列之间相同位置的间隙空位;
41、s453,将每个所述候选序列的末端的间隙空位进行修复处理。
42、优选地,所述左对齐处理包括:
43、在所述多序列比对结果中,确定所述多序列比对结果的候选序列中的间隙空位;并以所述候选序列作为第一原始序列,以所述第一原始序列中的所述间隙空位右边相邻的碱基作为右碱基;以相比较的所述多序列比对结果中的另一个候选序列作为第一比较序列,以所述第一比较序列中与所述间隙空位的位置对应的碱基作为第一比较碱基;
44、若所述右碱基与所述第一比较碱基相同,则将所述第一原始序列中的所述右碱基与所述间隙空位的位置调换,使所述第一原始序列中的右碱基的位置与所述第一比较序列中的第一比较碱基位置相同且碱基相同;
45、所述右对齐处理包括:
46、在所述多序列比对结果中,确定所述多序列比对结果的候选序列中的间隙空位;并以所述候选序列作为第二原始序列,以所述第二原始序列中的所述间隙空位左边相邻的碱基作为左碱基;以相比较的所述多序列比对结果中的另一个候选序列作为第二比较序列,以所述第二比较序列中与所述间隙空位的位置对应的碱基作为第二比较碱基;
47、若所述左碱基与所述第二比较碱基相同,则将所述第二原始序列中的所述左碱基与所述间隙空位的位置调换,使所述第一原始序列中的左碱基的位置与所述第二比较序列中的第二比较碱基位置相同且碱基相同。
48、优选地,所述s500包括:
49、s510,以所述优化比对结果的序列中出现突变的碱基作为突变信息,并对所述突变信息进行合并去冗余处理;
50、s520,将合并去冗余处理后的所述突变信息根据预设过滤标准进行过滤,得到所述低频变异检测结果。
51、此外,本发明还提供一种低频单核苷酸变异检测装置,包括:
52、数据比对模块,用于获取测序数据,以及对应的参考基因组,并将所述测序数据比对到所述参考基因组,得到比对信息;
53、位点提取模块,用于基于所述比对信息提取得到潜在变异位置作为候选位点;
54、位点覆盖模块,用于提取覆盖所述候选位点的序列信息,作为候选序列;
55、多重比对模块,用于对所述候选序列之间以碱基的相同部分进行位置对齐,得到多序列比对结果;以及,对所述多序列比对结果中的序列根据坐标位置去除相同的间隙空位,并重复进行不同方向碱基的对齐处理,直至相邻两次的对齐处理结果无变化为止,得到优化比对结果;
56、结果输出模块,用于基于所述优化比对结果输出低频变异检测结果。
57、本发明提供了一种低频单核苷酸变异检测方法和装置。其中,所述方法通过改进比对和分析流程,显著提高了检测的准确性和灵敏度。通过多序列比对和重比对,能够有效区分真实变异和伪变异,减少了因测序错误导致的假阳性结果,从而提高了结果准确率;无支持突变的reads数目最小要求,从而保持低频突变的鉴定灵敏性,不会漏掉变异;同时利用堆积分析全面识别低频变异位点,特别适用于三代测序数据的处理;且系统化和自动化的流程提升了检测效率,为基因组学研究和临床应用提供了更加可靠和高效的技术支持。