一种基于非对称自编码器的单细胞蒸馏判别聚类方法、系统、电子设备及介质
本发明涉及单细胞聚类,尤其是涉及一种基于非对称自编码器的单细胞蒸馏判别聚类方法、系统、电子设备及介质。
背景技术:
1、单细胞rna测序(scrna-seq)技术能够测量单个细胞的基因表达量,提供了极高的细胞差异分辨率,以便研究人员更好的研究组织内部的细胞异质性。近十年来,scrna-seq广泛应用于肿瘤、微生物和发育生物学等多个研究领域。细胞聚类是scrna-seq数据分析中的关键步骤,根据细胞的基因表达模式对细胞分组,进一步完成细胞功能识别和细胞类型注释任务。然而,scrna-seq数据的稀疏性、批次效应和高维性给细胞聚类带来了巨大挑战。技术偏差导致rna捕获率低,scrna-seq转录表达谱极其稀疏,并且存在大量dropout事件,增加了数据中的噪声和缺失值,从而影响细胞聚类分析的准确性。同时,由于组织在不同批次、不同时间、不同操作者等导致测得的基因表达量不同,从而使得数据分析存在误差。此外,scrna-seq数据通常具有极高维度,这使得提取细胞类型特异性信息和描述细胞间特征关系变得非常复杂,进一步增加了细胞聚类分析的难度。
2、为了克服上述挑战,研究人员在早期已经提出了许多传统的无监督聚类方法应用在单细胞数据上。这些方法主要通过降维技术从原始数据中学习重要特征,然后根据不同方式计算细胞之间的相似性或者距离,并使用k-means、louvain等聚类方法完成聚类任务。sc3通过不同的特征提取方法生成多个细胞间相似性矩阵,然后采用不同的聚类方法对每个相似性矩阵进行聚类,并通过共识聚类得到最终的稳定聚类。simlr利用常见的降维方法对单细胞数据降维后,基于欧氏距离、高斯核等方法初始化相似性矩阵,通过交替优化策略学习细胞间关系的局部和全局信息,从而实现最终聚类。cidr通过插补恢复丢失的基因表达值,以减轻数据稀疏性带来的影响,然后再插补后的数据上进行主成分分析,并使用层次聚类来识别细胞亚群。尽管这些方法能够有效揭示细胞间的多样性,但由于缺乏先验知识,聚类结果对数据噪声和高维稀疏性的鲁棒性较差,且在处理异质性较强的复杂样本时容易产生误分类。
3、为了弥补无监督方法在聚类准确性上的不足,许多研究团队引入半监督学习策略,通过利用少量标注良好的细胞类型信息来引导聚类。单细胞半监督聚类方法可以分为两类:基于机器学习和基于深度学习。基于机器学习的单细胞聚类方法通常利用部分已知的细胞标签来训练机器学习模型,然后根据训练好的模型对目标数据进行预测。scmap利用多个相似性函数比较目标数据和参考数据的基因表达模式,从而找出最相似的细胞类型,从而实现最终聚类。seurat 3.0利用互交式最近邻构建共享网络,从而捕捉细胞间的局部邻近关系,然后使用louvain算法识别细胞亚群。这类方法能够有效提高对稀有细胞类型的识别能力,且对噪声的鲁棒性有所提升。然而,这类方法对标注数据的依赖使其在标签数量不足或标签分布与目标数据差异较大时易受到域偏移的影响,导致模型泛化能力下降。
4、随着深度学习技术的兴起,研究人员将深度表示学习与半监督策略相结合,提出了半监督深度聚类方法。这类方法通过深度神经网络的非线性映射能力进行特征提取,能够捕捉scrna-seq数据的复杂表达模式,从而提升聚类性能。scdeepcluster利用基于零膨胀负二项分布(zinb)模型的自编码器有效捕捉数据中的非线性结构,并实现数据去噪,然后利用深度嵌入聚类使数据点向聚类中心靠拢,从而完成时聚类任务。itclust通过自编码器学习数据的特征,并使用相似性度量构建细胞间的相似性矩阵,最后通过结合迭代优化和基于图的聚类策略,能够在复杂的高维数据中有效识别细胞亚群(实现高质量的细胞聚类)。scsemiaae结合半监督学习和对抗自编码器的思想以实现更好的特征学习和聚类效果。scsemicluster在参考数据中加入结构相似性正则化来约束目标数据的聚类结果,并引入成对约束,以增强聚类的紧密度。scmckc在零膨胀负二项模型自编码器的基础上,考虑相似细胞之间的关联,构建细胞级的约束,并利用先验信息构建成对约束,使用加权的软k-means算法进行最终聚类。scdecl引入混合数据增强策略和插值损失来提高数据集的多样性和模型的鲁棒性,并将先验信息转化为增强的成对约束来指导聚类。sctpc基于零膨胀负二项分布预训练去噪自编码器。然后使用由部分标记细胞生成的三重约束和成对约束进行深度聚类。尽管这些半监督深度聚类方法能够在一定程度上提升聚类的效果,但在处理跨域数据集时依然面临源域与目标域分布不一致的问题。此外,大多数现有方法依赖于复杂的特征对齐策略,而忽略了对目标域数据内部结构的深度挖掘,导致目标数据的判别能力不足。
技术实现思路
1、本发明的目的是在于提供一种基于非对称自编码器的单细胞蒸馏判别聚类方法、系统、电子设备及介质,在细胞聚类性能上表现优秀,有助于推断细胞组织内部的复杂细胞组成和功能特征。
2、为实现上述目的,本发明提供了一种基于非对称自编码器的单细胞蒸馏判别聚类方法,包括以下步骤:
3、步骤s1、基于非对称自编码器对原始数据进行训练;其中,原始数据包括源数据和目标数据;
4、步骤s2、利用源数据标签信息和特征距离信息,使同类细胞聚集、不同的细胞簇远离;
5、步骤s3、利用源数据和目标数据的低维表示计算聚类中心,使细胞簇边界附近的细胞向聚类中心靠近,隐式完成域对齐任务。
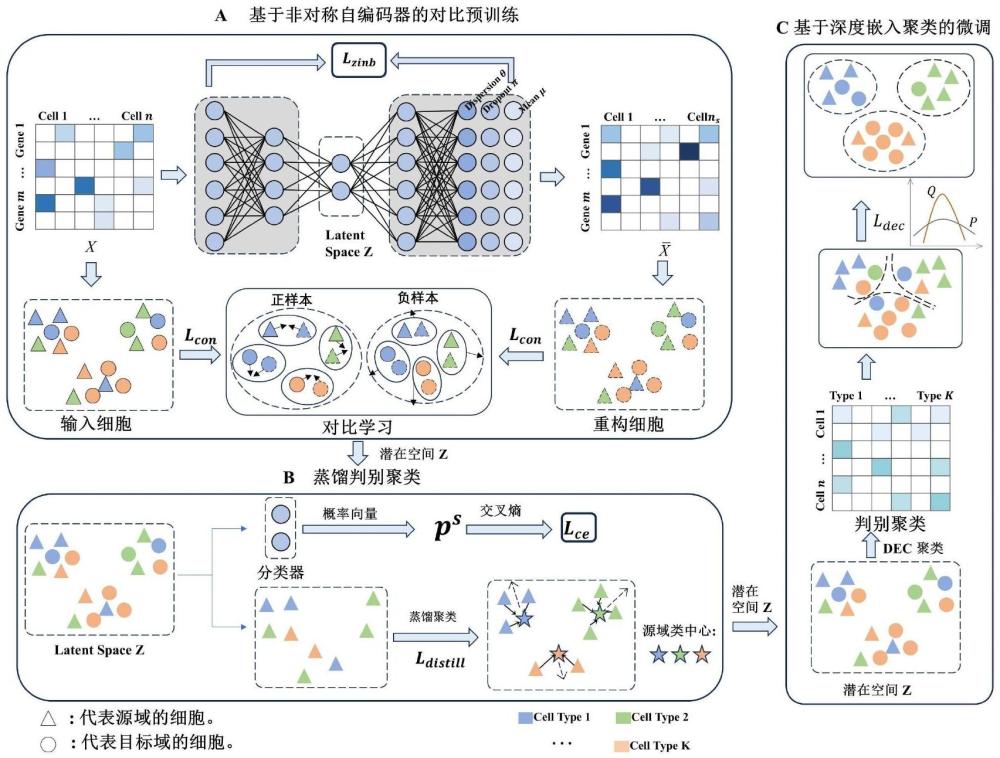
6、优选的,步骤s1中,基于非对称自编码器对原始数据进行训练,包括以下步骤:
7、步骤s11、将原始数据的基因表达矩阵x={x1,x2,...,xn}∈rn×m输入到非对称自编码器估计zinb分布的三个参数矩阵,包括零膨胀参数矩阵π={π1,π2,...,πn}∈rn×m、平均值参数矩阵μ={μ1,μ2,...,μn}∈rn×m和色散参数矩阵θ={θ1,θ2,...,θn}∈rn×m;
8、其中,n表示所有数据的样本数量;m表示输入数据的维度;xn表示第n个细胞的基因表达向量;πn表示第n个细胞对应的零膨胀参数向量;μn表示第n个细胞对应的平均值参数向量;θn表示第n个细胞对应的色散参数向量;
9、步骤s12、设xij表示第i个细胞中第j个基因的表达值,πij、μij、θij分别表示第i个细胞中第j个基因对应的零膨胀参数、平均值参数和色散参数,使其服从zinb分布:
10、pzinb(xij;πij,μij,θij)=πijδ0(xij)+(1-πij)pnb(xij;μij,θij);
11、
12、其中,γ(·)是gamma函数;δ0(·)是狄拉克函数,当xij=0时δ0(xij)取值为1,当xij≠0时δ0(xij)取值为0;
13、步骤s13、根据zinb分布的负对数似然函数重构数据的损失:
14、
15、其中,lzinb表示基于zinb分布的重构损失;pzinb(xij)表示zinb分布函数;
16、步骤s14、根据平均值参数矩阵m和大小因子向量s计算得重构数据计算公式如下:
17、
18、其中,s是每个细胞对应的大小因子向量,计算方法是细胞i的基因表达量总数除以所有细胞基因表达量总数的中位数;diag(·)表示将向量转为方阵中的对角线元素的函数;
19、对于每个样本xi,构造一个正对和2n-2个负对
20、
21、步骤s15、根据构造的正对和负对计算对比损失:
22、
23、其中,表示第i个细胞的原始数据构造的对比损失;表示第i个细胞的重构数据构造的对比损失;lcon表示总体对比损失;xa表示第a个细胞的基因表达向量;sim(·)是余弦相似性函数,
24、优选的,步骤s2中,利用源数据标签信息和特征距离信息,使同类细胞聚集、不同的细胞簇远离,包括以下步骤:
25、步骤s21、在非对称自编码器中的编码器后面加一个分类器,以源数据的基因表达矩阵作为输入,从分类器中得到参考数据的预测概率矩阵其中,ns表示源数据的样本数量,k表示细胞类型的数量,表示源数据中第i个细胞属于第k个细胞类型的预测概率;利用标准的交叉熵函数作为分类损失函数:
26、
27、其中,lce表示分类损失;表示源数据中细胞i的真实标签;i(·)表示指示函数;
28、步骤s22、以源数据的基因表达矩阵作为输入,通过非对称自编码器获得源数据的特征表示根据源数据的标签信息计算聚类中心:
29、
30、其中,φk表示细胞类型为k的聚类中心;表示源数据中第i个细胞的低维特征向量;φ={φ1,φ2,...,φk}∈rk×d表示聚类中心矩阵;d表示低维表示的维度;聚类中心在网络训练的每次迭代中更新,具体公式如下:
31、
32、其中,表示第epoch次迭代的细胞类型为k的聚类中心,表示第epoch-1次迭代的细胞类型为k的聚类中心;表示源数据中细胞类型为k的样本集合,α∈[0,1]表示移动平均系数;表示源数据中第a个细胞的低维特征向量;
33、步骤s23、利用标准交叉熵作为蒸馏聚类的损失函数,具体公式如下,
34、
35、其中,τ表示温度系数;表示源数据中细胞i的低维表示和聚类中心之间的距离向量;表示源数据中聚类中心φk和其他聚类中心之间的距离向量。
36、优选的,步骤s3中,利用源数据和目标数据的低维表示计算聚类中心,使细胞簇边界附近的细胞向聚类中心靠近,隐式完成域对齐任务,包括以下步骤:
37、步骤s31、以源数据和目标数据作为非对称自编码器的输入,得到源数据的低维特征和目标数据的低维特征及其对应的伪标签结合源数据的真实标签,计算最终的聚类中心:
38、
39、其中,ck表示微调阶段细胞类型为k的聚类中心,c={c1,c2,...,ck}是特征空间中源数据和目标数据的聚类中心;ns表示源数据的细胞数量;nt表示目标数据的细胞数量,n=ns+nt;表示源数据中第i个细胞的低维特征向量;表示目标数据中第i个细胞的低维特征向量;
40、步骤s32、利用t分布计算低维特征z和聚类中心c之间的相似度,即软聚类分配概率:
41、
42、其中,β表示t分布的自由度;表示软聚类分配概率分布;表示第i个细胞属于第k个细胞类型的软聚类分配概率;zi表示第i个细胞的低维特征向量;cl表示第l个聚类中心;利用高置信度的细胞来提高聚类质量,基于软聚类分配概率的分布定义辅助概率分布:
43、
44、其中,表示细胞i属于细胞类型l的软聚类分配概率;表示辅助概率分布,表示细胞i属于细胞类型k的辅助概率;
45、步骤s33、利用标准交叉熵函数作为聚类损失:
46、
47、其中,ldec表示聚类损失。
48、一种基于非对称自编码器的单细胞蒸馏判别聚类系统,包括:
49、对比预训练模块,用于基于非对称自编码器对原始数据进行训练;
50、蒸馏判别聚类模块,用于利用源数据标签信息和特征距离信息,使同类细胞聚集、不同的细胞簇远离;
51、深度嵌入聚类微调模块,用于利用源数据和目标数据的低维表示计算聚类中心,使细胞簇边界附近的细胞向聚类中心靠近,隐式完成域对齐任务。
52、一种计算机设备,包括:存储器和处理器;存储器存储有计算机程序,处理器执行计算机程序时实现上述的基于非对称自编码器的单细胞蒸馏判别聚类方法的步骤。
53、一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述的基于非对称自编码器的单细胞蒸馏判别聚类方法的步骤。
54、因此,本发明采用上述的一种基于非对称自编码器的单细胞蒸馏判别聚类方法、系统、电子设备及介质,有益技术效果如下:该方法通过非对称自编码器的训练,有效地捕捉了单细胞数据的复杂表达模式,并结合源数据的标签信息和特征距离信息,使同类细胞聚集、不同细胞簇远离。同时,利用源数据和目标数据的低维表示计算聚类中心,进一步优化了细胞簇的边界,隐式完成了域对齐任务。这些技术特点共同作用下,使得该方法在细胞聚类上表现出色,有助于更准确地推断细胞组织内部的复杂细胞组成和功能特征,为单细胞rna测序(scrna-seq)数据的分析提供了有力的支持。
- 还没有人留言评论。精彩留言会获得点赞!