利用有效位置和反馈传送信息的方法、设备和系统与流程
本公开涉及用于改善信息传送(包括交流)的设备、系统和方法。
背景技术:
1、自从早期记载的人类历史以来,人们一直想与诸如狗、海豚、马等动物交流并更好地理解这些动物。该主题在不同文化中均有展现,见诸于我们的神话、我们的民间传说和我们的故事(包括书籍和影片)。这是一种与生俱来的渴望,但这种渴望揭示了一个问题。
2、我们和我们的动物都发现自己因沟通不明确又渴望联系而感到沮丧。我们尽最大努力通过非语言暗示了解动物的需求,但人类和动物之间的沟通历来都很困难,误解比比皆是。
3、例如,在敏捷性训练中,当狗的主人不理解它的需求时,它可能会显得烦躁,反之亦然。在家里,狗无法向其懊恼的主人解释它为什么会吠叫。在机场,安检犬可能能够向它的管理员(handler)发出信号,表明它在行李箱中闻到了需要调查的东西,但安检犬不能告诉它的管理员需要调查的物品是一个水果、一枚炸弹,还是毒品。在警察局,狗可能经过训练而能示意炸弹或毒品,但不能同时示意两者,因为狗不能将它嗅到了什么直接传达给它的人类伙伴。服务犬可能会因为各种原因需要与它的管理员沟通,包括服务犬是否需要上厕所或警告管理员。如果狗能表达出它感到不适,兽医可能会受益。与此相关的是,骑手有时意识到他们的马生病时救治时间已太晚。
4、许多动物都表现出用声音及在某些方面与人类语言有相似之处的其他提示进行交流的能力。例如,某些动物可产生类似人类“说话”的声音。已深入地研究了狐獴,发现它们会进行简单的类语言发声交流,借此识别捕食者并警告它们的群体。狐獴对人类的描述甚至可以精确到这个人穿什么衣服,这个人的身高,以及这个人衬衫的颜色。大鼠也有一套言语语法,科学家们仍在努力破译和理解。著名的是对鹦鹉alex开展的研究,结果表明它能够用人类语言交流。海豚和类人猿可以理解姿态,有时还可以使用姿态交流。海豚可以理解人类姿态。
5、狗是我们最古老的伙伴,并且可能是最早驯养的动物。这种驯养可以从狗寻求沟通或理解其人类同伴的方式中得到证明。例如,小狗会看着人类指的方向。但狼崽不会。狗跟随我们一起进化。
6、狗是一种聪明的动物。有一只狗很有名,它学会了大约一千个单词(主要是它玩具的名字)。多年来的研究表明,狗能理解人类的语言。根据狗对算术的基本理解的研究,有报道称狗的智力相当于两岁的人类。研究表明,狗能听懂人类说话的单词和语调。此外,最近还表明,狗可以通过代表特定词汇的发声按钮与主人交流。
7、神经科学告诉我们,脑就像一台计算机一样,已设定好程序来使用和适应提供给它的任何感觉输入或肢体,即“可塑性”。例如,如果加上了眼睛,脑就学习看;如果加上了鼻子,脑就学习闻;如果加上了红外传感器,脑最终会适应并学习红外“观察”。来自传感器的输入在脑中感知并随时间推移而渐渐适应。
8、动物也表现出能适应使用新的人造附器,如假肢,学习控制和移动机械臂来完成任务,如把食物送到动物的嘴里。
9、发音语音学是语音学的分支,涉及到用发音来描述世界上各种语言的语音,也就是发声器官(发音器)的运动和/或位置。发音语音学涉及到参与发出口头语言的物理机制。发音语音学的一个基本目标是将语言表征与发音器的实时运动以及随之而来的声输出联系起来,使语音成为信息传送的媒介。语音学的这一领域传统上涉及到有机发音器和人的口腔。
10、在应用于人类的语音学领域,“发音部位”是被动发音器和主动发音器可能相遇而产生声音的位置,或者是有机器官(organic instrument)中可能产生声音的部位位置。此外,在语音学领域,人类的“发音方式”可能是指将会做出什么样的收缩。例如,在人类中,主动发音器和被动发音器的运动可集中在一起,形成完全闭塞,使得从口中流出的气流被切断,这也称为“塞音”。
11、诸如狗之类的动物没有我们人类所使用的相同人类有机发音器,并且它们不能像我们彼此之间那样对我们说话。狗还没有能力在语音上建立言语,包括与人类说话相同或相似的方式。原因是狗不能利用像我们复杂的舌头和嘴那样的东西。
12、本公开介绍了涉及改善诸如交流之类的信息传送的设备、方法和/或系统。本公开的一个应用是建立信息传送媒介,使得动物和人类可以互动。本发明的新型设备、系统和方法可以允许用户使用目标导向姿态达到有效空间性位置,这些有效空间性位置与构成言语的元素和/或其他信息传送媒介相对应,这些元素包括但不限于从语言学和语音学领域使用的国际语音字母表(“ipa”)中获得的声音。在一些非限制性实施方案中,将语音声分配给有效空间性位置,从而产生言语和/或其他信息传送媒介的运动。
13、通过提供新型设备、方法和/或系统,本发明可以允许动物(如狗和其他动物)进行交流。该设备、方法和/或系统可以允许佩戴者以与人类构建语音的方式相同或相似的方式进行语音谈话。以这种方式,狗可以学习使用人工语音工具与人类和其他(诸如与其他动物)进行交流。本公开还可以允许与接受口头输入的其他技术交互,诸如与语音助理或与人工智能交互。该设备、方法和/或系统也可以由缺乏言语能力的人类使用,以在语音上建立言语。
14、我们可以问fido一个问题,而它可以用我们理解的方式回答。fido不再是沉默的被动接受者。相反,fido拥有决定权,可有意告诉我们它想要我们知道的事情。本公开的设备允许它与我们交流。
技术实现思路
1、本公开呈现了用于促进信息传送(包括通过用户与一个或多个有效空间性位置和/或有效姿态之间的交互)的系统、方法和设备。这种交互可以产生输出,包括但不限于触觉反馈、振动、声音、数据等。在一些实施方案中,人类或动物可以使用该系统、方法和设备来交流,包括通过为动物提供系统、方法和设备来在语音上构建言语和/或使用预先录制的单词或短语来交流。
2、一种装置,包括:
3、一个或多个传感器,该一个或多个传感器被配置为生成指示用户的空间性位置和取向中的至少一者的信号;以及
4、一个或多个处理器,该一个或多个处理器被配置为接收该信号,其中该一个或多个处理器执行用于以下操作的指令:
5、确定用户的至少一部分已与定义的空间区域相交或用户已呈现定义的取向;以及
6、基于该确定来生成一个或多个输出信号。
7、该装置还包括:
8、一个或多个部件,该一个或多个部件被配置为存储数据,其中该数据包括与一个或多个预先录制的声音相对应的声音数据;
9、一个或多个扬声器;
10、其中该指令还包括用于以下操作的指令:
11、选择与定义的空间区域相对应的该一个或多个预先录制的声音中的至少一者;
12、基于该选择,根据与该一个或多个预先录制的声音中的至少一者相对应的声音数据来生成输出信号;
13、其中该一个或多个扬声器被配置为响应于输出信号而产生包括该一个或多个预先录制的声音中的至少一者的声音。
14、该装置还包括一个或多个预先录制的声音,该一个或多个预先录制的声音存储在被配置为存储包括语音声的数据的一个或多个部件上。
15、作为预先录制的声音的替代或补充,该装置还包括用于语音或声音合成的部件或编程。
16、该装置还包括附加声音,诸如音调、钟声、铃声、音乐等。
17、该装置还包括挽具、含条带的挽具、可调式条带、弹性部件、带扣、d形环、o形环或维可牢(velcro),还包括可释放的附接点,包括用于电子部件的附接点。
18、该装置还包括用于显示虚拟现实和/或增强现实的头戴式显示器。
19、该装置还包括:
20、一个或多个触觉反馈部件,该一个或多个触觉反馈部件被配置为产生触觉反馈;
21、其中该指令还包括用于基于该确定来生成输出信号的指令,该输出信号被配置为激活该一个或多个触觉反馈部件;
22、其中该一个或多个触觉反馈部件被配置为响应于输出信号而生成第一触觉反馈。
23、该装置还包括:
24、一个或多个部件,该一个或多个部件被配置为存储数据,其中该数据包括与一个或多个预先录制的声音相对应的声音数据;
25、一个或多个扬声器;
26、其中该确定包括确定用户的该部分已与定义的空间区域相交或者用户已呈现定义的取向达超过表示时间段的阈值的时间段;
27、其中该指令还包括用于以下操作的指令:
28、基于该确定来选择与定义的空间区域相对应的该一个或多个预先录制的声音中的至少一者;
29、基于该选择来生成与该一个或多个预先录制的声音中的至少一者相对应的输出信号;
30、其中该一个或多个扬声器被配置为响应于输出信号而生成包括该一个或多个预先录制的声音中的至少一者的声音。
31、该装置还包括片上系统。
32、该装置还包括感测用户的取向、位置或运动的一个或多个传感器。
33、该装置还包括触觉反馈,该触觉反馈可包括一个或多个轻拍感觉。
34、该装置还包括触觉反馈,该触觉反馈可包括一个或多个振动。
35、该装置还包括用于振动反馈的部件。
36、该装置中的一个或多个输出包括数据。
37、该装置还包括收发器,其中该收发器可接收和传输数据。
38、该装置的用户可以是人类或动物,诸如狗、猫、马、海豚、猴等。该系统的用户也可以是人工智能或软件算法。
39、一种系统,包括:
40、一个或多个传感器,该一个或多个传感器被配置为生成指示用户的附器的空间性位置和取向中的至少一者的信号,其中附器在相对于用户的注视方向固定的三维空间中的路径或旋转对应于一个或多个姿态;以及
41、一个或多个处理器,该一个或多个处理器被配置为接收该信号,其中该一个或多个处理器执行用于以下操作的指令:
42、确定用户已进行如下步骤中的至少一个步骤:(i)沿着与这些姿态中的第一姿态相对应的这些路径中的第一路径移动附器,以及(ii)以与这些姿态中的第二姿态相对应的方式旋转附器;
43、基于该确定来生成与第一姿态和第二姿态中的至少一者相对应的输出信号。
44、该系统还包括:
45、一个或多个部件,该一个或多个部件被配置为存储数据,其中该数据包括与一个或多个预先录制的声音相对应的声音数据;
46、一个或多个扬声器;
47、其中该指令还包括用于以下操作的指令:
48、选择与第一姿态和第二姿态中的至少一者相对应的一个或多个预先录制的声音中的至少一者;
49、基于该选择来生成与该一个或多个预先录制的声音中的至少一者相对应的输出信号;
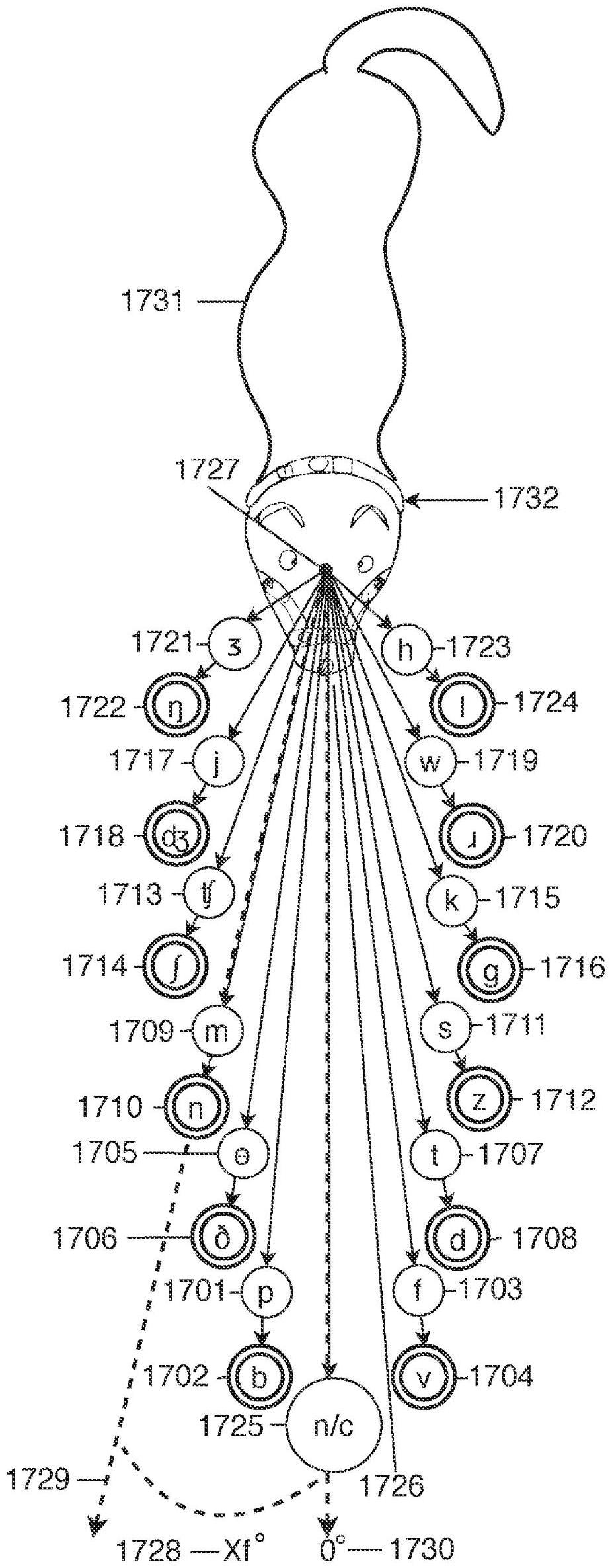
50、其中该一个或多个扬声器被配置为响应于输出信号而生成包括该一个或多个预先录制的声音中的至少一者的声音。
51、该系统还包括:
52、一个或多个部件,该一个或多个部件被配置为产生触觉反馈;
53、其中该指令还包括用于基于该确定来生成输出信号的指令,该输出信号被配置为激活该一个或多个触觉反馈部件;
54、其中被配置为产生触觉反馈的一个或多个部件响应于输出信号而生成第一触觉反馈。
55、该系统还包括一个或多个预先录制的声音,该一个或多个预先录制的声音存储在被配置为存储包括一个或多个语音声的数据的一个或多个部件上。
56、该系统的用户可以是人类或动物,诸如狗、猫、马、海豚、猴等。该系统的用户也可以是人工智能或软件算法。
57、该系统还包括片上系统。
58、该系统还包括感测用户的取向、位置或运动的一个或多个传感器。
59、该系统还包括触觉反馈,该触觉反馈可包括一个或多个轻拍感觉。
60、该系统还包括触觉反馈,该触觉反馈可包括一个或多个振动。
61、该系统还包括用于振动反馈的部件。
62、该系统中的一个或多个输出包括数据。
63、该系统还包括收发器,其中该收发器可接收和传输数据。
64、该系统还包括服务器,其中该收发器与该服务器接收和传输数据。
65、该系统还包括一个或多个电源,诸如电池、可再充电电池、电源插座、太阳能等。
66、该系统还包括能够发送用户的嘴是闭着还是张开的传感器,其中当用户的嘴张开时,输出可以被激活,并且当用户的嘴闭着时,输出可以被去激活。
67、该系统还包括语音空间,该语音空间将诸如辅音和元音之类的某些语音声组织到某些定义的空间区域。
68、该系统还包括用户与所述语音空间的交互。
69、该系统还包括用户使用附器与所述语音空间的交互,其中传感器跟踪用户附器的位置、运动和取向。
70、该系统中用户的附器是鼻部或口鼻部。
71、一种与狗一起使用的装置,该装置包括:
72、挽具,该挽具适于配合在狗的口鼻部和身体上;
73、附接到挽具的一个或多个处理器;
74、附接到挽具的一个或多个传感器,该一个或多个传感器操作地连接到该一个或多个处理器;
75、附接到挽具的一个或多个触觉电机,该一个或多个触觉电机操作地连接到该一个或多个处理器;
76、附接到挽具的一个或多个扬声器,该一个或多个扬声器操作地连接到该一个或多个处理器;以及
77、一个或多个电源,该一个或多个电源附接到挽具并且电耦接到至少该一个或多个处理器和该一个或多个触觉电机。
78、该装置还包括:
79、一个或多个存储部件,该一个或多个存储部件操作地连接到该一个或多个处理器;
80、一个或多个预先录制的声音,该一个或多个预先录制的声音存储在该一个或多个存储部件上;
81、该一个或多个电源,该一个或多个电源进一步电耦接到该一个或多个存储部件。
82、该装置中的一个或多个预先录制的声音包括一个或多个语音声或者一个或多个预先录制的声音或短语。
83、该装置还包括:
84、一个或多个存储部件,该一个或多个存储部件操作地连接到该一个或多个处理器并且被配置为存储与一个或多个预先录制的声音相对应的声音数据;
85、该一个或多个电源,该一个或多个电源进一步电耦接到该一个或多个存储部件。
86、该装置还包括能够发送用户的嘴是闭着还是张开的传感器。
87、一种系统,包括:
88、第一装置,该第一装置包括:
89、一个或多个部件,该一个或多个部件被配置为存储和播放声音;
90、一个或多个收发器,该一个或多个收发器能够无线地通信;
91、第二装置,该第二装置包括:
92、一个或多个收发器,该一个或多个收发器能够无线地通信;
93、一个或多个麦克风,该一个或多个麦克风能够录制声音;
94、一个或多个部件,该一个或多个部件被配置为存储和播放声音;
95、非暂态计算机可读存储介质,该非暂态计算机可读存储介质体现计算机程序,该计算机程序包括用于以下操作的计算机指令:
96、使用该一个或多个麦克风录制一个或多个声音;
97、无线地连接到第一装置;
98、将录制的声音传输到第一装置。
99、其中第二装置将录制的声音传输到第一装置,其中第一装置存储录制的声音。
100、一种系统,包括:
101、处理器,该处理器被配置为:
102、确定社交网络情境,其中所述社交网络情境包括关于宠物的信息,包括以下的至少一者:
103、宠物姓名;
104、宠物年龄;
105、训练统计信息;
106、言语统计信息;
107、至少部分地基于社交网络情境来生成至少一个视图;
108、显示生成的视图。
109、一种涉及训练者和受训者的训练方法,其中训练者是人并且受训者是狗,该训练方法包括:
110、由训练者观察受训者与装置交互,其中该装置包括响应于受训者的一个或多个预定义的动作而可听地生成至少一个预先录制的声音的部件;
111、由训练者倾听该装置可听地生成至少一个预先录制的声音;
112、由训练者向受训者提供奖励。
113、一种涉及训练者和受训者的训练方法,其中训练者是人并且受训者是佩戴装置的狗,该装置包括:
114、一个或多个传感器,该一个或多个传感器被配置为生成指示受训者的空间性位置和取向中的至少一者的信号;
115、一个或多个数据存储部件;
116、一个或多个扬声器,该一个或多个扬声器被配置为接收信号并生成声音;
117、一个或多个预先录制的声音,该一个或多个预先录制的声音包括存储在该一个或多个数据存储部件上的语音字母表;
118、一个或多个处理器,该一个或多个处理器被配置为接收该信号,其中该一个或多个处理器执行用于以下操作的指令:
119、确定受训者的至少一部分已与定义的空间区域相交或用户已呈现定义的取向;
120、基于该确定来生成包括该一个或多个预先录制的声音的输出信号;
121、其中被配置为接收信号并生成声音的该一个或多个扬声器接收包括该一个或多个预先录制的声音的所述输出信号,并且生成包括选择的一个或多个预先录制的声音的声音。
122、该训练方法包括:
123、由训练者观察该装置生成包括选择的一个或多个预先录制的声音的声音;
124、由训练者向受训者提供奖励。
125、根据详细描述和附图,本发明的其他方面和优点将变得显而易见。
- 还没有人留言评论。精彩留言会获得点赞!