结合先验知识的深度强化学习对抗方法
本发明涉及深度强化学习领域中的游戏对抗领域,尤其涉及一种结合先验知识的深度强化学习对抗。
背景技术:
1、随着深度强化学习进程的加快,人与万物之间的联系也越来越密切。对抗作为人类社会发展的主旋律,广泛存在于人与自然以及机器之间,它是人类智能的重要表现形式。人类在面对复杂庞大以及瞬息万变的对抗环境时,往往不能保证及时有效的处理问题,因此运用深度强化学习的思想研究对抗问题,形成更为合理的决策成为必然。以对抗关系为主的相关研究,为智能对抗的理论研究提供了有效工具,高速发展的智能对抗技术逐渐成为了游戏、交通、金融甚至是军事等领域前进的重要动力。
2、目前,智能对抗技术在复杂对抗环境中的挑战主要为非完全信息博弈、状态空间规模大以及对抗问题难以求解等。首先,环境的不确定性会增加游戏中决策的难度,如战争迷雾造成的信息不完整问题会直接影响了智能体对环境状态的认知,间接增加了形势评估的复杂程度,由于信息不完整导致的错误信息进一步增加了问题的难度。此外,环境的不确定性将会给现有的优势造成不利的影响,在这种情况下,如何根据当前态势做出合适的动作,以使收益最大化是要面临的另一个重大挑战。在复杂的对抗环境中,智能体的状态空间和行动空间一般都是非常大的,由于时间和存储的限制,探索整个对抗空间是不可能的。抽象建模方法可以在一定程度上减少问题维度的大小,但往往是以牺牲解决方案的质量为代价,没有理论上的保证。
技术实现思路
1、本发明要克服现有技术的上述缺点,提供一种结合先验知识的深度强化学习对抗方法,通过深度强化学习算法对智能体进行训练的同时,结合先验知识影响决策的实施,从而更为快速的提升智能体的对战效果。
2、为解决上述技术问题,本发明所采用的技术方案如下:
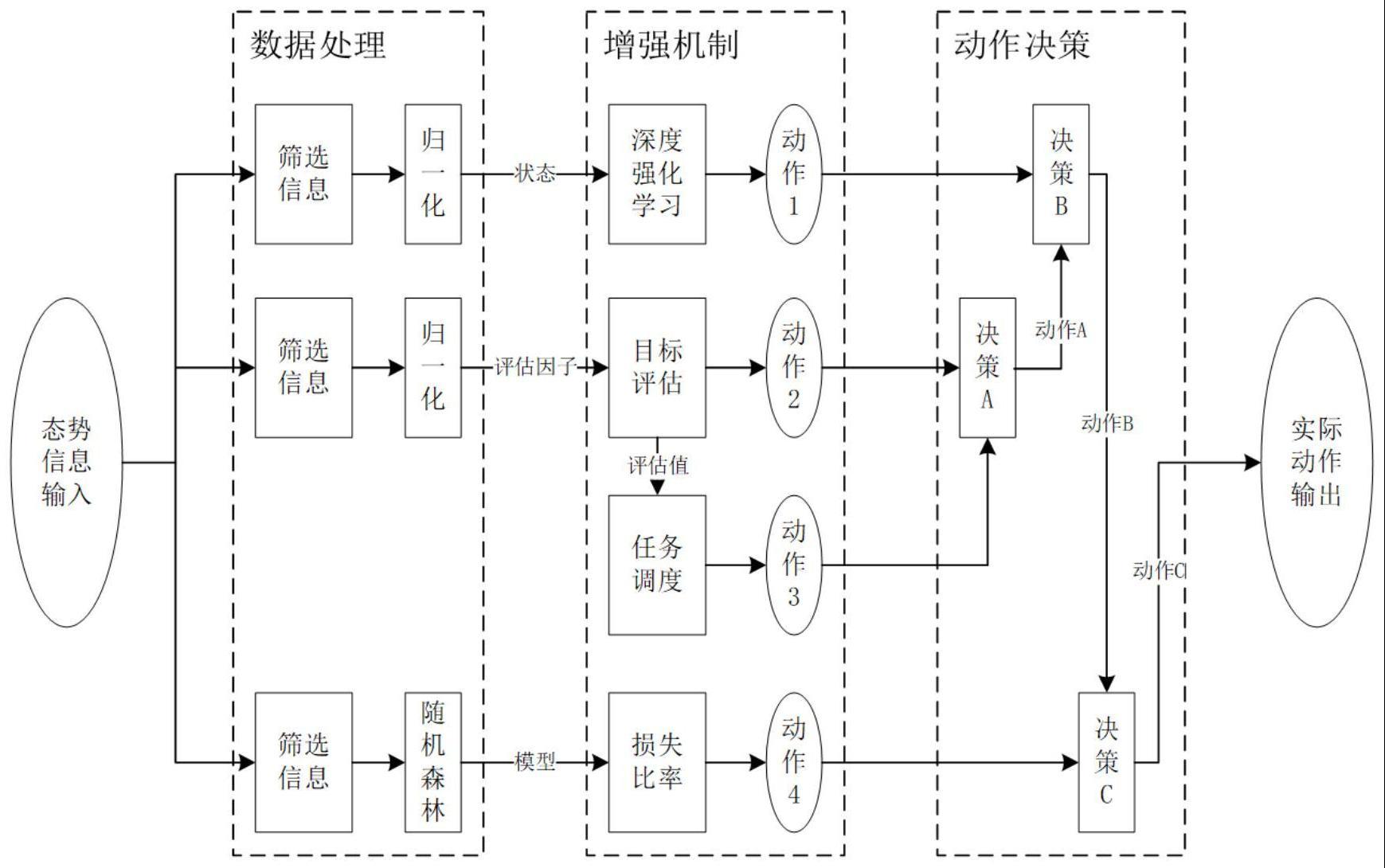
3、针对复杂环境下的对抗问题,将先验知识与深度强化学习算法相结合,提出了一种新的对抗流程框架。此框架包含数据处理、增强机制以及动作决策等内容。首先,对输入的态势信息进行筛选,将筛选后的信息加工处理输出至各个增强机制中。然后,运用深度强化学习算法对态势信息进行训练;选择对己方构成危险的目标评估因子,通过评估因子构建评估模型并以此做出目标矩阵;设计了目标矩阵扩展为任务目标矩阵,并针对特殊情况进行相应的行为调度;引入了损失比率以提升智能体的收敛速度和最终效果。最后通过动作决策找出最佳动作并将其通过指令进行实际动作输出。
4、将流程框架与仿真对抗环境相结合,对智能体参数和增强机制进行设计。选取单位信息和情报信息的部分信息构成状态空间,不存在的情况置零处理,避免了维度灾难的问题;对战场区域进行划分,将无限的空间区域分割为有限的子区域,降低了学习的压力;对单位进行编组,并将所有编组进行指令整合,大幅度精简了动作空间;结合仿真设计基于仿真平台的奖励函数。最后,结合仿真环境对智能博弈对抗框架进行了专门设计,增加智能体的胜率。
5、本发明的结合先验知识的深度强化学习对抗方法,各步骤的具体构成如下:
6、s1.输入数据,输入信息需要的是智能对抗环境中己方视角下所能获取的所有具体信息,然后获取到的信息会被进行数据处理。这里需要注意的是针对不同的环境所获取的信息是不同的,有的环境是部分可知的,其只能获取单方信息,而有的环境是完全可知的,获取的态势信息类似于打开了游戏中的上帝视角。
7、s2.处理数据,对态势输入的信息进行处理,筛选出所需信息,并将其加工处理后进行增强机制处理。数据处理根据需求功能不同,因此其具体所筛选的信息也不同,包括:筛选出深度强化学习所需的态势信息,对其进行归一化处理作为深度强化学习的状态信息;筛选出先验知识所需的信息,根据先验知识对其进行相应处理。
8、s3.增强机制,将先验知识与深度强化学习结合起来,进而提升智能体收敛速度以及最终成绩。增强机制的处理过程包括深度强化学习处理以及先验知识处理,其中深度强化学习处理过程类似于黑盒子,它基于深度强化学习算法根据输入的状态输出相应动作;为使算法更快的收敛,先验知识的处理过程是将数据处理后的数据经机器学习方法训练后得到对应的先验模型,然后按照根据先验模型得到相应动作。
9、s4.决策动作,对增强机制处理后输出的动作进行决策,找出最佳动作,然后按其进行实际动作输出。其首先对先验知识输出的动作进行优先度判定;然后将其和深度强化学习模型得到的动作进行决策;最后根据损失比率决策对其动作进行相应的决策,得到最佳动作。
10、s5.输出动作,对动作决策后的动作进行实际输出。
11、进一步,步骤s1中包括:
12、s11.从当前态势中获取己方的各种基础信息,包括类型、速度、角度以及位置等信息。
13、s12.从当前态势中获取己方已探测的对方单位的各种基础信息,包括类型、速度、位置以及方向等信息。
14、进一步,步骤s2中包括:
15、s21.将s11以及s12中的信息合并后进行归一化处理。
16、s22.对s21得到的数据按照不同需求进行相应的处理,如:筛选目标因子、筛选状态信息以及通过机器学习方法进行数据训练等。
17、进一步,步骤s3中包括:
18、s31.深度强化学习,为了提升复杂环境下的智能博弈对抗问题,本发明在深度强化学习中采用的是目前深度学习领域最为常见的ac算法框架。ac算法将基于值的方法与基于策略的方法结合了起来,具有样本利用率高、价值函数估计准确等优点。在面对具有态势信息庞大,动作组合极其复杂等特点的复杂环境时,ac算法存在收敛速度慢、高方差以及维度过高时难以收敛等问题。考虑到这些问题,因此本发明选择了ac算法的优化版本a2c算法来设计,a2c算法使用优势函数代替critic网络中的原始回报作为衡量选取动作值和所有动作平均值好坏的指标。
19、s32.在设计智能体时,对智能体的状态空间、动作空间以及奖励函数进行了专门的设计,以提升智能体的训练效果。
20、s33.确定目标评估的评估公式为:
21、w=α(aρ+bθ+cμ+dυ)+βγ (1)
22、其中,ρ表示能量指数、θ表示角度指数、μ表示距离指数、υ表示速度指数、γ表示装备威胁指数。
23、s34.传统的能量指数一般参考己方单位的机动性ρv、装备威力ρa、探测能力ρb、可操作性ε1、血量ε2、最大活动空间ε3以及隐藏能力ε4来进行评估。传统能量指数的评估方式如下:
24、ρ=[lnρv+ln(ρv+1)+ln(ρb)]ε1ε2ε3ε4 (2)
25、s35.本发明在s34的基础上考虑通过对抗单位的类型、速度等能力信息对该单位进行能量威胁指数的判定。
26、s36.角度指数θ根据双方的航向角与位置角得出,角度指数的评估方式如下:
27、
28、其中表示己方单位与对方单位的位置角,α1表示己方航向角,α2表示对方航向角。
29、s37.距离指数μ根据双方的相对距离l得出,距离指数的评估方式如下:
30、
31、其中l表示双方的空间距离,dn表示自动攻击距离,df表示最大攻击范围,dz表示单位探测范围。
32、s38.速度威胁指数υ根据双方的速度得出,速度威胁指数的设计方式如下:
33、
34、其中v1表示己方单位的速度,v2表示敌方单位的速度。
35、s39.装备指数γ根据对方装备的状态以及与己方的距离得出,装备指数的设计方式如下:
36、
37、其中rh表示高危距离,rl表示低危距离。
38、s310.由上诉s33的评估公式可计算目标程度大小,假定有m个己方单位以及n个对方单位,那么建立对方单位对己方单位的评估矩阵w。
39、s311.在目标评估的基础上,任务调度可根据目标的优先度对己方单位进行相应的行为调度,通过任务评估矩阵a分析对方单位对己方整体目标程度大小bn进行行为调度,它可以直接影响智能体的实时性能。
40、s312.将当前态势的数据输入至机器学习模型,根据模型输出的结果做出相应的动作。
41、进一步,步骤s4中包括:
42、s41.对增强机制处理后输出的动作2以及动作3进行决策,输出动作a。
43、s42.对增强机制处理后输出的动作1以及动作决策输出的动作a进行决策,输出动作b。
44、s43.对增强机制处理后输出的动作4以及动作决策输出的动作b进行决策,输出动作c。
45、进一步,步骤s5中包括:
46、输出动作,将动作决策的最终输出动作进行实际输出。
47、本发明设计的一种结合先验知识的深度强化学习对抗方法,通过将深度强化学习强大的数据处理能力与避免走入死胡同的先验知识相结合,进而做出当前状态下的动作决策。
48、本发明的优点是:考虑到复杂对抗环境下传统的深度强化学习方法很难满足收敛速度以及最终胜率等性能要求。针对此类问题提出了一种结合先验知识的深度强化学习对抗方法,设计了数据处理、增强机制以及动作决策等内容来提升智能体在复杂对抗环境下的收敛速度和对抗效果。在dc平台上进行仿真,仿真结果可以很好的满足收敛速度以及最终效果。
- 还没有人留言评论。精彩留言会获得点赞!